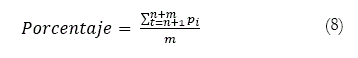
Predictor alternativo del precio de los activos financieros.
El caso de la plata y el oro
Alternative predictor of the price of financial assets The
case of silver and gold
José Martínez1, Luis Améstica-Rivas2, Antonino Parisi3 ]]>
César Gurrola4
1 Magíster en Gestión de Empresas. Facultad de Ciencias Empresariales, Universidad del Bío-Bío,
Chile. Email: : jimartin@egresados.ubiobio.cl
2 Dr. en Administración y Dirección de Empresas, Académico Departamento de Gestión Empresarial,
Facultad de Ciencias Empresariales, Universidad del Bío-Bío, Chile. Investigador asociado grupo de
investigación en Dirección Universitaria de la Universidad Politécnica de
Cataluña. Email: lamestica@ubiobio.cl
3 Dr. en Economía y Finanzas. Académico Facultad de Ingeniería y Negocios, Universidad Adventista
de Chile. Email: aparisi5555@gmail.com
4 Dr. en Administración. Académico Universidad Juárez del Estado de Durango, ]]>
México. Email: cgurrola@ujed.mx
Recepción: 28/06/2020 Aceptación: 28/12/2021
Resumen
El objetivo de este trabajo es comprobar la eficacia del modelo ARIMA optimizado con fuerza bruta operacional para pronosticar en el mercado financiero el precio de dos commodities: oro y plata, como una técnica alternativa que permita rentabilizar inversiones y mejorar la toma de decisiones de los actores financieros. Se utilizó información de los precios de cierre semanales del oro y de la plata durante el período 2015 - 2018, observando las variaciones de precios y comparando los datos reales con las pronosticadas a través del modelo. Se utilizaron para ambos modelos ocho variables, generando un millón de iteraciones aleatorias con fuerza bruta, ya que esta técnica no restringe la obtención de algún resultado, como lo hace la optimización por simplex y/o solver. Con la técnica de fuerza bruta se pudo establecer una capacidad de predicción en ambos activos superior al 60%.
Palabras clave: mercado de capitales, modelo predictivo, rentabilidad, commodities, activos.
Abstract
The objective of this work is to test the effectiveness of the ARIMA model optimized with operational gross force to forecast the price of two commodities: gold and silver in the financial market, as an alternative technique to make investments profitable and improve the decision-making of financial actors. We used information from the weekly closing prices of gold and silver during the period 2015 - 2018, observing the price variations and comparing the real data with the ones predicted through the model. Eight variables were used for both models, generating one million random iterations with gross force, as this technique does not restrict the obtaining of any result, as does simplex and/or solver optimization. With the brute force technique it was possible to establish a predictive capacity in both assets of more than 60%.
Keywords: capital market, predictive model, profitability, commodities, assets.
INTRODUCCIÓN
En el competitivo mundo de las inversiones y mercado de activos, es necesario tener la mayor cantidad de información para tomar mejores decisiones, idealmente fundamentadas y basadas en confiables modelos estadísticos, econométricos o financieros, que permitan actuar ante la incertidumbre que estos mercados generan. Por lo anterior se hace necesario la creación de modelos que tengan capacidad predictiva y que sean herramientas útiles para combatir la incertidumbre y el riesgo inherente de los mercados, predecir los cambios en los precios de activos y obtener beneficios de esta operación.
Tanto inversionistas, tomadores de decisión y académicos, entre otros, han intentado encontrar la forma en que sus inversiones e investigaciones tengan mejores resultados, esto los ha llevado a incursionar en diversas herramientas que les permita aspirar a las expectativas propuestas. Es en esta línea en que se desenvuelve esta investigación, lograr la aplicación del modelo ARIMA optimizado con fuerza bruta operacional, a partir de lo propuesto por Parisi (2015), en el precio del oro y de la plata, teniendo como finalidad, predecir con un porcentaje de predicción de signo sobre el 60%, la variación del precio de una semana respecto a otra y por consiguiente mejorar la toma de decisiones para los inversionistas, quienes podrán tomar medidas precautorias y saber cómo actuar ante una eventual situación desfavorable, teniendo en consideración al menos, en este análisis, dos activos de refugio analizados, con el objetivo de verificar en que commodity es más efectivo, ya que ambos se evaluaron bajo las mismas condiciones, y reafirmar con esto lo expuesto por Fama (1970), que nos dice que el mercado es eficiente cuando este refleja completa y correctamente toda la información relevante para la determinación de los precios de activos.
Sin embargo existe ciertas dudas por parte de la academia y de analistas respecto a estos modelos predictivos, en esta ámbito se puede aseverar que existe controversia respecto a las predicciones, pero al margen de esta controversia, al observar los modelos que examinan la importancia de la información contenida en las secuencias de precios, Grundy & McNichols (1989) y Brown & Jennings (1989) consideraron modelos de expectativas racionales en los cuales un único precio no revela la información subyacente, pero sí lo hace una secuencia de precios de activo, demostrando con esto que el análisis técnico de patrones de precios puede ser valioso ya que facilita el aprendizaje de los traders.
Además se realizó una revisión de los más importantes modelos predictivos y sus aplicaciones, realizadas en acciones y commodities. Para desarrollar el modelo se utilizó la información disponible en internet para conocer los precios de ambos activos comprendidos en el período 2015 - 2018, donde se observó la variación de los precios, y así poder comparar los datos reales con las variaciones pronosticadas.
Una vez terminada la investigación, se concluyó que si es factible construir un modelo predictivo con una capacidad de predicción superior al 60% para el caso del oro alcanzando un 65,7% y en el caso de la plata un 64,5%. El modelo ARIMA se construyó con 1.000.000 de iteraciones con fuerza bruta, dado que la optimización por simplex o Solver no alcanzaron el resultado esperado, entregando un mejor resultado para el caso del oro.
Alcances en los modelos predictivos en finanzas
]]> Dentro de los métodos más populares de diseñar modelos para las series de tiempo encontramos el autorregresivo integrado de media móvil (ARIMA), más conocido como la metodología Box-Jenkings, metodología que se utilizó en esta investigación, sin embargo existen otros modelos que han tenido éxito y son bastante utilizadas, dentro de estos podemos encontrar; Autómatas Celulares, que fueron diseñados por John Von Neumann y Stanislaw Ulam en los años 40. Desde su creación los autómatas celulares han sido estudiados demostrando su importancia y transversalidad en distintas áreas de estudio, por lo que son de interés en diferentes disciplinas (Rechtman, 1991). Los autómatas celulares se pueden definir como un sistema dinámico formado por un conjunto de elementos sencillos idénticos entre sí, pero que en conjunto son capaces de demostrar comportamientos complejos globales.Se aencuentra también los Algoritmos Genéticos, propuestos por Holland (1975), son métodos adaptativos que pueden usarse para resolver problemas de búsqueda y optimización. Están basados en el proceso genético de los organismos vivos. Consisten en una función matemática o una rutina que simula el proceso evolutivo de las especies, teniendo como objetivo encontrar soluciones a problemas específicos de maximización o minimización. Otro famoso modelo, son las redes neuronales desarrolladas por McCulloch y Pitts (1943), las redes de neuronas artificiales (denominadas habitualmente como RNA o en inglés como: "ANN"1) son un paradigma de aprendizaje y procesamiento automático inspirado en la forma en que funciona el sistema nervioso biológico. Se trata de un sistema de interconexión de neuronas que colaboran entre sí para producir un estímulo de salida.
Pero profundizando más aún en el modelo en cuestión para esta investigación, el modelo ARIMA, es un modelo estadístico implementado por Box y Jenkins (1976) que utiliza variaciones y regresiones de datos estadísticos con el fin de encontrar patrones para una predicción hacia el futuro. Se trata de un modelo dinámico de series temporales, es decir, las estimaciones futuras vienen explicadas por los datos del pasado y no por variables independientes.
El interés por predecir las variaciones de precios en commodities no es nuevo y queda plasmado en la siguiente revisión, donde se presentan investigaciones con una pequeña y breve síntesis sobre los resultados en diferentes investigaciones realizadas en torno a los modelos predictivos y su aplicación a los commodities. Engel y Valdes (2001) comparan la capacidad predictiva de mediano plazo (1 a 5 años) de una variada gama de modelos de series cronológicas para el precio del cobre. Concluyendo que los dos modelos con mejor capacidad predictiva son el proceso autorregresivo de primer orden y el camino aleatorio. Finalmente presentan evidencia sugiriendo que los modelos de series cronológicas entregan mejores predicciones de mediano plazo que los modelos econométricos. Hanns De La Fuente, H., Lorca, N., Rojas, J. (2008) en su investigación, Análisis de la serie de precios del trigo mediante la Metodología Box-Jenkins, y su co-integración con las Series de precios de productos derivados, trabajan sobre el precio del trigo, construyeron un modelo econométrico estimativo del precio del trigo, en el cual incluyeron la estacionalidad que el mercado de este producto posee en los meses de noviembre, diciembre y enero.
Posteriormente comprobaron cuantitativamente sus suposiciones, es decir, que existe significancia estadística, ya que efectivamente durante los meses de Noviembre, Diciembre y Enero, el precio del trigo alcanza sus valores máximos año tras año debido a la escasez del producto en dicha fecha, pues lo que se vende durante este período es lo último que queda de las cosechas anteriores, por lo que el precio se eleva por sobre los niveles usuales. En esta línea Viego, V. & Broz, D. (2012) proponen un Modelo ARIMA basado en la metodología de Box Jenkins. Utilizaron series de precios de tres clases diamétricas (C1, C2, C3) de productos de Pinus spp, desde Junio de 2006 hasta Febrero de 2012, para el Norte de la Provincia de Corrientes con el objeto de estimar precios futuros.
En la investigación los modelos de pronóstico propuestos lucieron satisfactoriamente en el corto plazo. Las series de precios de C1 y C2 presentan predicciones con errores estables menores al 1%. Los errores de predicción del modelo de precios propuesto para C3 promedian 1,72%. Y en lo que es más cercano la investigación que se desarrolla en este trabajo se presenta lo expuesto por Parisi, Améstica & Chileno (2016) en su artículo, Modelo predictivo para variaciones de precio del petróleo. Optimización de ARIMA utilizando fuerza bruta operacional. La investigación buscaba evaluar la eficacia del modelo ARIMA multivariable optimizado mediante fuerza bruta computacional para el caso del precio del petróleo, prediciendo el comportamiento que tendrán las acciones de dicho activo. Conjuntamente los resultados de las pruebas arrojaron que los modelos ARIMA creados en base a variables endógenas y exógenas obtuvieron gran capacidad para predecir el comportamiento en el cambio de signo de las variaciones semanales del precio del petróleo.
Elaboración del Modelo ARIMA, AR y MA Para series de tiempo
Proceso Autorregresivo (AR)
Sea Yt el Precio de la acción en el período t. Si se modela Yt como
(Yt - δ) = α1 (Yt - δ) + ut (1)
]]> Donde δ es la media de Y y donde ut es un término de error aleatorio no correlacionado con media cero y varianza constante σ2 (ruido blanco), entonces se dice quePero, si se considera este modelo
(Yt - δ) = α1 (Yt-1 - δ) + α3 (Yt-2 - δ) + ut (2)
Entonces, se dice que Yt sigue un proceso autorregresivo de segundo orden, o AR(2). Es decir, el valor de Y en el tiempo t depende de sus valores en los dos períodos anteriores, los valores de Y expresados alrededor del valor de su media.
En general, se tiene
(Yt - δ) = α1 (Yt-1 - δ) + α2 (Yt-2 - δ) + ut + ... + αp (Yt-p - δ) ut (3)
En cuyo caso, Yt , es un proceso autorregresivo de orden p, o AR(p).
Obsérvese que en todos los modelos anteriores solamente se están considerando los valores actuales y anteriores de Y; no hay otros regresores.
Proceso de media móvil (MA)
El proceso AR recién expuesto no es el único mecanismo que puede haber generado a Y. Supóngase que se modela Y de la siguiente manera:
]]> Yt = μ + β0 ut + β1 ut-1 (4)Donde μ es una constante y u, al igual que antes, es el término de error estocástico ruido blanco. Aquí, Y en el período t es igual a una constante más un promedio móvil de los términos de error presente y pasado. Así, en el caso presente, se dice que Y sigue un proceso de media móvil de primer orden, o MA(1).
Pero, si Y sigue la expresión
Yt = μ + β0 ut + β1 ut-1 + β2 ut-2 (5)
Entonces, es un proceso MA(2). En forma más general,
Yt = μ + β0 ut + β1 ut-1 + β2 ut-2 + ... + βq ut-q (6)
Es un proceso MA(q). En resumen, un proceso de medio móvil es sencillamente una combinación lineal de términos de error ruido blanco.
Por supuesto, es muy probable que Y tenga características de AR y de MA a la vez y, por consiguiente, sea ARMA. Así, Ytsigue un proceso ARMA si éste puede describirse como:
Yt = θ + α1 Yt-1 + β0 ut + β1 ut-1 (7)
Porque hay un término autorregresivo y uno de media móvil. En general, en un proceso ARMA(p,q), habrá p términos autorregresivo y q términos de medias móviles.
Pero si una serie de tiempo es integrada de orden 1 [es decir, si es I(1)], sus primeras diferencias son I(0), es decir estacionarias. En forma similar, si una serie de tiempo es I(2), su segunda diferencia es I(0). En general, si una serie de tiempo es I(d), después de diferenciarla d veces se obtiene una serie I(0). Por consiguiente, si se debe diferenciar una serie de tiempo d veces para hacerla estacionaria y luego aplicar a ésta el modelo ARMA (p,q), se dice que la serie de tiempo original es ARIMA(p,d,q), es decir, es una serie de tiempo autorregresivo integrada de media móvil, donde p denota el número de términos autorregresivo, d el número de veces que la serie debe ser diferenciada para de hacerse estacionaria y q el número de términos de media móvil. Así, una serie de tiempo ARIMA (2,1,2) tiene que ser diferenciada una vez (d=1) antes de que se haga estacionaria, y la serie de tiempo estacionaria (en primera diferencia) puede ser modelada como un proceso ARMA(2,2), es decir, que tiene dos términos AR y dos términos MA. Por supuesto, si d = 0 (es decir, si para empezar la serie es estacionaria), ARIMA(p,d = 0,q) = ARMA(p,q) .
Obsérvese que un proceso, ARIMA(p,0,0) significa un proceso estacionario AR(p) puro; un ARIMA(0,0,q) significa un proceso estacionario MA(q) puro. Dados los valores de p,d y q , puede decirse cuál proceso está siendo modelado.
El punto importante de mencionar es que para utilizar la metodología Box-Jenkins, se debe tener una serie de tiempo estacionaria o una serie de tiempo que sea estacionaria después de una o más diferenciaciones. La razón para suponer estacionariedad puede explicarse de la siguiente manera:
“El objetivo de BJ [Box-Jenkins] es identificar y estimar un modelo estadístico que pueda ser interpretado como generador de la información muestral. Entonces, si este modelo estimado va ser utilizado para predicción, se debe suponer que sus características son constantes a través del tiempo y, particularmente, en períodos de tiempo futuro. Así, la simple razón para requerir información estacionaria es que cualquier modelo que sea inferido a partir de esta información pueda ser interpretado como estacionario o estable, proporcionando, por consiguiente, una base válida para predicción.”
Técnica de Fuerza Bruta
Esta técnica se utilizó para optimizar el modelo ARIMA aplicado al precio del oro y de la plata, se siguió el procedimiento utilizado por Parisi (2015), quien utiliza este recurso gracias a la capacidad actual de las computadoras para poder encontrar la mejor solución a un problema de optimización. Esta técnica aplicada a los modelos ARIMA genera escenarios diferentes en los cuales cada uno de ellos brinda una solución óptima al problema. La función de este modelo ARIMA con fuerza bruta, es comparar los nuevos escenarios generados con los anteriores y el resultado óptimo.
De otro forma se puede decir que recuerda al igual que un humano el comportamiento que ha tenido para darle una mejor solución a determinado problema, y si ese comportamiento solucionó el problema, cada vez que suceda un escenario parecido, el humano utilizará dicho comportamiento. De la misma manera, ARIMA con fuerza bruta utiliza el modelo óptimo.
En los modelos ARIMA, que son modelos de regresión, la técnica fuerza bruta permite generar infinitos coeficientes de un universo establecido, para darle un peso a cada variable establecida y evaluada en el modelo. Incluso se puede afirmar que usando fuerza bruta se puede contemplar todos los escenarios del universo establecido, siendo así, una mejora a los algoritmos genéticos, los cuales solo buscan alrededor de un punto en el universo que ofrece una solución de primera instancia óptima Parisi (2015).
]]> Esta técnica se explica muy bien en lo expuesto por Durán, G. (2006), donde señala que la fuerza bruta consiste en enlistar todos los casos y para cada uno calcular la solución, identificando de este modo el caso que ofrezca la mejor solución. Trabajando bajo el mismo concepto Riveros (2015), en una investigación para encontrar la solución óptima al problema del “camino más corto” para una empresa de logística, comenta que la solución más directa es con fuerza bruta, es decir, evaluar todas las posibles combinaciones y quedarse con el trayecto que utiliza una menor distancia.En resumen, la fuerza bruta, prueba una a una, las diferentes condiciones y características de un sistema para resolver el problema propuesto. En el momento en que encuentra la solución, se queda con dicho sistema. Esta técnica no se utilizaba dada la baja capacidad para resolver problemas que requerían la evaluación de una cantidad de variables considerada demasiado grande. En cambio, en la actualidad, esto no es un problema, gracias al desarrollo tecnológico del último tiempo, y cualquier persona puede contar con un computador con recursos altamente efectivos capaces de procesar información mucho más rápido que herramientas o computadoras de hace algunos años. Por esto, es que es prudente e incluso más eficaz, utilizar la técnica fuerza bruta gracias la capacidad de una computadora de alta tecnología.
Se presenta a continuación la metodología utilizada en esta investigación. Se muestran aspectos como el tipo de investigación, las técnicas y procedimientos que fueron utilizados para llevar a cabo el estudio.
Tipo de Investigación y diseño
Esta investigación tiene un enfoque cuantitativo, de acuerdo a lo expuesto por Hernández, Fernández, y Baptista (2010), y también correlacional puesto que los modelos ARIMA trabajan en base a series de tiempo, por lo que se utiliza la relación entre el precio pasado para proyectar el precio futuro del activo. Ahora bien, no se explica cuál es la relación en específico, pero se sabe que los precios pasados afectan en la variación del precio a futuro. Esto se ve reflejado en el porcentaje de predicción a partir de estas variables.
Población y muestra
La población utilizada en esta investigación, son los precios históricos de la plata y el oro publicados en el London Metal Exchange (LME), que es el mayor mercado del mundo en contratos a futuro de metales no ferrosos. La muestra son los precios de cierre semanales de ambos commodities y que correspondan al período comprendido entre Enero de 2015 y Noviembre de 2018.
Análisis de Datos
La construcción del modelo ARIMA optimizado con fuerza bruta operacional, detallado anteriormente, se realizó para evaluar su poder predictivo para frecuencias semanales. La intencionalidad es determinar el comportamiento del modelo en su función predictiva en la variación del signo desde una semana a otra para los precios del oro y de la plata.
]]> Como se ha mencionado con anterioridad durante esta investigación la técnica fuerza bruta de Parisi (2015) y utilizado en Parisi, Améstica y Chileno (2016), tiene como objetivo encontrar los coeficientes óptimos que maximicen el porcentaje de predicción de signo de las variaciones semanales de las cotizaciones para los valores en análisis.Se realizó una evaluación de la predicción y luego una análisis de significancia estadística, para comprobar si el resultado es por efecto del azar o por el correcto desempeño del modelo.
Evaluación de la predicción
En este punto se evalúa la calidad de cada modelo en función del porcentaje de predicción de signo alcanzado (PPS). La evaluación se realizó sobre la base de un conjunto extramuestral de 203 datos semanales para el modelo aplicado en los dos activos. Se utilizó la muestra total tanto para estimar los coeficientes α, β y θ de cada modelo respectivamente, por medio de la minimización de la suma del cuadrado de los residuos del modelo, como para evaluar la capacidad predictiva de los modelos.
Esta evaluación se realiza comparando el signo de la proyección con el signo de la variación observada en cada i-esimo período, en el que i = 1,2,...,m. La efectividad del modelo analizado aumenta cuando los signos entre la proyección y el observado coinciden y en caso contrario, disminuye su capacidad predictiva.
Proyectado el signo de la variación del precio para el período n+1, la variación observada correspondiente se incluye en la muestra de tamaño de n con objeto de reestimar los coeficientes del modelo, contando ahora con una observación más. Así, el mismo modelo pero con sus coeficientes recalculados es utilizado para realizar la proyección correspondiente al período n + 2. Este procedimiento recursivo se efectuó una y otra vez hasta acabar con las observaciones del conjunto extramuestral. Finalmente, el PPS de cada modelo se calculó de la siguiente forma:
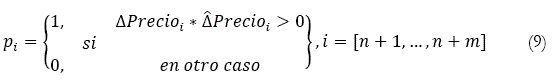
En la que Δ en la ecuación (9), representa la variación observada, la ![]() variación estimada, n = 0 y m = 203 ó 109, pi se refiere al precio observado en el período i que es representado por t que también se refiere al período o tiempo en el que se observa el precio. De esta manera, los modelos multivariados dinámicos construidos optimizados con técnica fuerza bruta fueron evaluados en función de su capacidad para predecir el signo de los movimientos del precio del valor en estudio.
variación estimada, n = 0 y m = 203 ó 109, pi se refiere al precio observado en el período i que es representado por t que también se refiere al período o tiempo en el que se observa el precio. De esta manera, los modelos multivariados dinámicos construidos optimizados con técnica fuerza bruta fueron evaluados en función de su capacidad para predecir el signo de los movimientos del precio del valor en estudio.
Evaluación estadística
]]> Para medir la precisión direccional de los modelos de proyección, se aplicó la prueba de acierto direccional de Pesaran y Timmermann (1992), que proponen Parisi y Parisi (2010), en su libro Teoría de Inversiones, para medir la capacidad de predicción de los modelos de ARIMA. El test compara el signo de la proyecciónSe define la razón/ratio de éxito (SR) como:

en donde, Ii es función que toma el valor de 1 cuando el argumento es cierto y de 0 en caso contrario. Junto a esto,
![]()
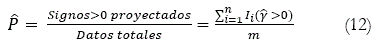
La razón/ratio de éxito en el caso de independencia de ![]() y Y, SRI, está dada por,
y Y, SRI, está dada por,
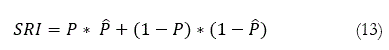
Donde su varianza es,
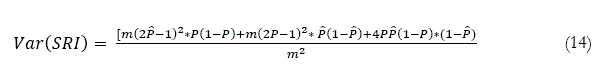
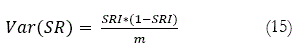
Finalizando, el test DA de Pesaran y Timmermann (1992) está definido por,
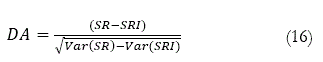
Los creadores mostraron que bajo la hipótesis nula de que ![]() y Y están distribuidos independientemente, por lo tanto el test sigue una distribución normal.
y Y están distribuidos independientemente, por lo tanto el test sigue una distribución normal.
Durante la fase recursiva de la estimación se consideraron solamente los “hits” correctos (10), dejando para el modelo optimizado la determinación de la significancia de los resultados de la predicción (16).
De acuerdo a lo mencionado anteriormente, este test trabaja bajo el supuesto que el valor que arroja el test, se distribuye según una función normal, es decir, los puntos críticos con un 95% de confianza son [-1,96; +1,96]. Lo que representa la zona de no rechazo de la hipótesis nula “Ho”; para probar que los resultados obtenidos no son producto del azar, se debe rechazar la hipótesis nula.
RESULTADOS Y DISCUSIÓN
La evaluación de cada escenario, para alcanzar el modelo óptimo, con la estructura del modelo ARIMA utilizando fuerza bruta, se realizó mediante el uso de un computador.
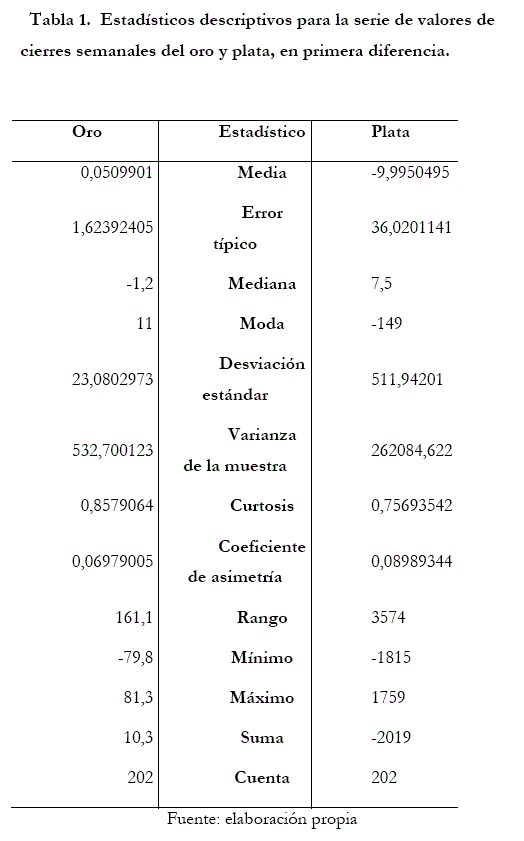
]]> En la Tabla 1 se presentan el análisis de ambas series de valores de cierre en primera diferencia, del oro y de la plata. Ambos commodities arrojaron un coeficiente de asimetría positivo, esto quiere decir que es una distribución asimétrica donde existe mayor concentración de valores a la derecha de la media que a su izquierda. Es importante mencionar lo entregado por la curtosis, los cuales son positivos, esto significa que la distribución de los valores observados en ambos commodities adoptaron una forma leptokurtósica, esto quiere decir que la distribución toma una forma más picuda.En la ecuación (17) y (18) se muestran para el caso del oro y de la plata el mejor modelo multivariado dinámico para cada caso estudiado con el Porcentaje de predicción de Signo.
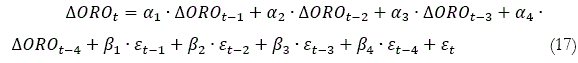
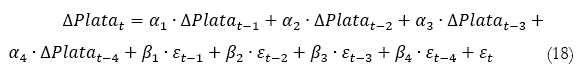
Los coeficientes αi y βi del mejor modelo para el caso del oro y la plata se muestran en la tabla 2, estos en términos del porcentaje de predicción de signo que se obtienen por el modelo, los cuales maximizan el PPS, estos coeficientes se obtuvieron después de desarrollar el modelo utilizando fuerza bruta operacional, alcanzando un millón de iteraciones.
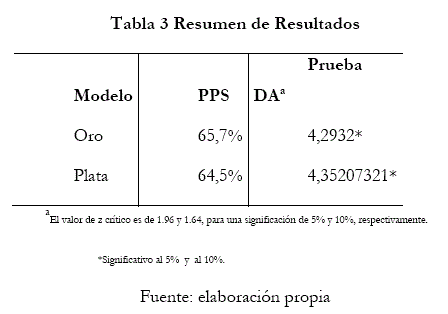
En la Tabla 3 se muestran los porcentajes de predicción de signo arrojados para ambos casos, para el oro y la plata, que se obtuvieron desde los mejores modelos producidos por ARIMA con fuerza bruta. La capacidad predictiva fue estimada en un conjunto extramuestral de 203 datos semanales para ambos casos, y según el resultado que entregó la prueba de acierto direccional se concluye que esta capacidad predictiva es estadísticamente significativa en cada uno de sus valores, comprobándose con esto la hipótesis de que si existe capacidad predictiva del modelo optimizado con fuerza bruta operacional aplicados al oro y la plata.
Se puede reafirmar que el modelo ARIMA optimizado con fuerza bruta operacional alcanzó el PPS que se esperaba, por sobre el 60%, y una significancia estadística que nos permite rechazar la hipótesis nula, ya que el valor del test DA se compara con el valor crítico de una tabla de distribución normal (z), el cual es de 1.96, para un nivel de significancia de 5%. Debido a que el valor absoluto del test DA es mayor que z, se rechaza la hipótesis nula y, en consecuencia, se concluye que el modelo tiene capacidad para predecir el signo de las variaciones del precio del oro.
]]>Se determinó que es posible desarrollar un modelo ARIMA optimizado con fuerza bruta operacional, con una capacidad predictiva mayor al 60%, para la variación del precio del oro y de la plata, PPS que es aceptable según lo expuesto por Fama y French (1992). Estos resultados son continuidad de buenos resultados de este modelo optimizado con fuerza bruta aplicado a commodities, pues Parisi, Améstica y Chileno (2016), también obtuvieron buenos resultados, para el caso de la variación del precio del petróleo.
El modelo ARIMA optimizado con fuerza bruta operacional aplicado al precio del oro y de la plata, bajo las mismas condiciones (misma cantidad de datos analizados e iteraciones con fuerza bruta), entregó un mejor PPS para el caso del oro en desmedro de la plata. Si bien no es una gran diferencia, permite entregar información al mercado acerca de estos dos activos de refugio, información que es valorada por inversionistas, traders, entre otros especialistas de los mercados de capitales, porque sus decisiones pueden estar condicionadas a la comparación de la eficiencia de un modelo respecto a dos activos. Se invita a realizar esta comparación con otros activos para verificar y comprobar que tan determinante puede ser el PPS para la toma de decisiones.
Durante la investigación se revisaron distintos modelos predictivos aplicados a diferentes commodities. Lo anterior demostró que existe interés por parte de la literatura y lo muestra a lo largo del tiempo en su intención por predecir eventos futuros, en lo que a variación de precios respecta.
Se obtuvo un buen comportamiento de los modelos respecto a la capacidad de predecir el signo de las variaciones semanales de los precios. Junto a lo anterior los resultados de la prueba de acierto direccional de Pesaran y Timmermann (1992), el cual es: útil cuando se está evaluando la capacidad predictiva de un modelo de signo (Parisi y Parisi, 2010, p. 533), demostraron que los modelos ARIMA presentaron una capacidad predictiva estadísticamente significativa, esto dado los valores presentados en el capítulo anterior.
La investigación entrega bases sólidas de que los modelos ARIMA equipados con fuerza bruta operacional son factibles de realizar y pueden ser utilizados con una metodología para seguir investigando acerca de las proyecciones de series de tiempo, siempre en función de la capacidad predictiva sobre la variación del precio.
Concluyendo, esta investigación logra determinar bajo que activo de refugio el modelo ARIMA optimizado con fuerza bruta operacional es más eficiente, entregando como resultado que es más eficiente analizando las variaciones del precio del oro por sobre la plata, en una baja diferencia, pero se desempeña mejor con el oro. Es por lo anterior que esta investigación presenta evidencia empírica de que utilizar modelos equipados con fuerza bruta operacional permite entregar escenarios óptimos de situaciones futuras y de incertidumbre, permitiendo una continuación ya actualización de la investigación de Parisi, Parisi y Cornejo (2004), demostrando que utilizar el modelo es una buena opción como una herramienta útil para la toma de decisiones.
Box, G., and Jenkins, G. (1976). Time series analysis: Forecasting and Control. San Francisco: Holden Day, John Wiley & Sons. [ Links ]
Brown and Jennings, (1989). D. Brown, R. Jennings on technical analysis. Review of Financial Studies, 2 (4), 527-552. [ Links ]
Durán, G. (2006). Investigación de operaciones, modelos matemáticos y optimización. Seminario Junaeb-Dii, Santiago de Chile. Disponible en: http://old.dii.uchile.cl/~gduran/docs/charlas/junaeb_willy_8.pdf. [ Links ]
Engel, E. y Valdes, R. (2001). Prediciendo el precio del cobre: ¿más allá del camino aleatório? Documentos de Trabajo N° 100, Centro de Economía Aplicada, Universidad de Chile, Santiago de Chile. Disponible en: https://ideas.repec.org/p/edj/ceauch/100.html [ Links ]
Fama, E. and French, K. (1992). The cross-section of expected stock returns, Journal of Finance, 47 (2), 427-465. [ Links ]
Fama, E.F. (1970). Efficient Capital Markets: A Review of Theory and Empirical Work. The Journal of Finance, 25(2), 383-417. [ Links ]
Grundy, B., and M. McNichols, (1989), Trade and Revelation of Information through Prices and Direct Disclosure, Review of Financial Studies, 2, 495-526. [ Links ]
]]>Hanns De La Fuente, H., Lorca, N. and Rojas, J. (2008). Análisis de la serie de precios del trigo mediante la metodología Box-Jenkins, y su cointegración con las series de precios de productos derivados. Revista Ingeniería Industrial, 2, 59-69. [ Links ]
Hernández, R., Baptista, M. and Fernández, C. (2010). Metodología de investigación. Mexico: Mcgrawhill. [ Links ]
Holland, H. (1975). Adaptation in natural and artificial systems: An introductory analysis with applications to biology, control, and artificial intelligence. Oxford, Inglaterra: The University of Michigan Press. [ Links ]
McCulloch, W. S., and Pitts, W. (1943). A Logical Calculus of the Ideas Immanent in Nervous Activity. The Bulletin of Mathematical Biophysics, 5, 115-133. [ Links ]
Parisi, A. (2015). Modelo predictivo accionario adoptando fuerza bruta. Documento de trabajo Programa Magister Dirección de Empresas (MDE). Chillán, Universidad del Bío Bío, Chile. [ Links ]
]]>Parisi, A., Améstica, L., and Chileno, E. (2016). Modelo predictivo para variaciones de precio del petróleo. Optimización de ARIMA utilizando fuerza bruta operacional. XVI International Finance Conference, Santiago, septiembre. [ Links ]
Parisi, A., Parisi, F. and Cornejo, E. (2004), Algoritmos genéticos y modelos multivariados recursivos en la predicción de índices bursátiles de América del Norte: IPC, TSE, Nasdaq y DJI. El Trimestre Económico 284, 789-809. [ Links ]
Parisi, F., and Parisi, A. (2010). Teoría de Inversiones. Chile: Copygraph [ Links ]
Pesaran, M., Timmermann, A. (1992). A Simple Nonparametric Test of Predictive Performance, Journal of Business & Economic Statistics, 10 (4), 561-65. [ Links ]
Rechtman, R. (1991). Una introducción a células autómatas. Ciencias, UNAM, 24, 23- 29. [ Links ]
Riveros, D. (2015). Aplicación de la investigación de operaciones al problema de la distribución a una empresa logística. Universidad Nacional Mayor de San Marcos, Perú. Disponible en: https://core.ac.uk/download/pdf/54216940.pdf [ Links ]
Viego, V., and Broz, D. (2012). Un modelo de predicción de precios forestales basados en la metodología Box-Jenkins. XXVI Jornadas Forestales de Entre Ríos, At Concordia, Entre Ríos, octubre. [ Links ]
]]>