Exposición al comercio internacional e ingresos laborales en Bolivia: evidencia al nivel del trabajador
Trade Exposure and Labor Earnings in Bolivia: Worker Level Evidence
José Miguel Molina Fernández*, Rodrigo Gonzáles Zuazo**
* Economista investigador en Ciess Econométrica. Contacto: joselito_mmvi@hotmail.com
** Economista investigador en Ciess Econométrica. Contacto: rodrigogonzaleszuazo@hotmail.com
Resumen
El presente documento investiga cómo la exposición a las importaciones en determinadas industrias bolivianas afectó a los ingresos laborales de los trabajadores en dichas industrias. Trabajando con las encuestas de hogares 2005-2009, se estiman ecuaciones de Mincer mediante técnicas de pseudo-panel, para controlar la presencia de variables no observables constantes en el tiempo. Se discuten los problemas econométricos de inconsistencia que pueden surgir al no considerar explícitamente la presencia de estos efectos al estimar ecuaciones de Mincer. Nuestros resultados de pseudo-panel sugieren efectos reducidos: se estima que un aumento del 1 % en la penetración de las importaciones en una industria dada reduce el ingreso laboral real para sus trabajadores en un 0,84%.
Palabras clave: Penetración de importaciones, ingresos laborales, comercio internacional, pseudo-panel.
Abstract
This document investigates how the import exposure in certain Bolivian industries affected workers' labor income from these industries. Working with the 2005-2009 Household Surveys, Mincer equations are estimated using pseudo-panel techniques to control the presence of constant non-observable time-invariant variables. The econometric problems of inconsistency that can arise when not explicitly considering the presence of these effects when estimating Mincer equations are discussed. Our pseudo-panel results suggest reduced effects: we estimate that a 1% increase in imports penetration in a given industry reduces real labor income for its workers by 0.84%.
Key words: Import penetration, labor income, international trade, pseudo-panel.
Clasificación/Classification JEL: F16, F66, J31
]]>
1. Introducción
El comercio adquirió una relevancia sin precedentes para la economía boliviana en los últimos años, en relación con lo que se ha observado en la historia moderna. De 2004 a 2017,la relación entre el comercio de mercancías y el PIB alcanzó consistentemente niveles superiores a los registrados en cualquier año desde 1960. El auge de las exportaciones financió una triplicación en el volumen de importaciones entre 2003 y 2011 (el volumen de importación disminuyó posteriormente, pero todavía está por encima de los niveles de 2003) (Banco Mundial, 2018).
Los investigadores han estudiado extensamente las consecuencias del auge de las exportaciones, pero no muchos han analizado los efectos potenciales del notable aumento de las importaciones (sino de forma secundaria)1. Para una industria determinada, un aumento de las importaciones no es necesariamente "un problema", si no le representa competencia. Por ejemplo, un aumento en el ingreso disponible de los consumidores probablemente podría resultar en un crecimiento de ventas similar, tanto para los productores nacionales como los extranjeros en la industria. También es posible que los productores nacionales y extranjeros compitan en diferentes mercados debido a la diferenciación del producto, a pesar de estar en la misma industria. Un aumento de las importaciones también podría explicarse por insumos más baratos o de mayor calidad para los productores nacionales. Sin embargo, si los productos extranjeros perjudican las ganancias reales o potenciales en la industria, las decisiones tomadas por las empresas como respuesta pueden tener repercusiones para los trabajadores.
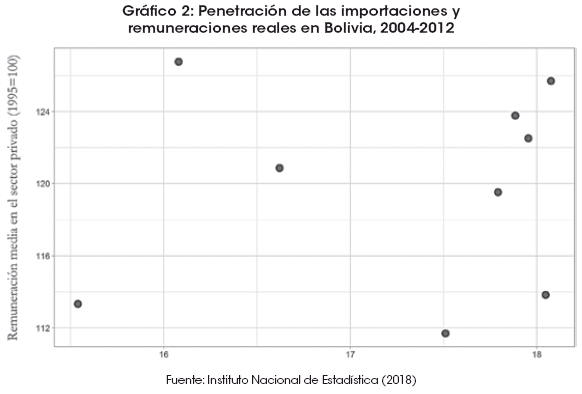
La reciente literatura empírica sobre comercio internacional ha prestado mucha atención a los efectos de la exposición del comercio internacional a nivel subnacional y a nivel industria. Se ha llegado a resultados bastante diversos que han aportado conocimiento que no se había logrado develar previamente en estudios con datos agregados (Autor et al., 2016; Pavcnik, 2017). Desde un punto de vista teórico, esto era de esperarse, puesto que los cambios en los flujos comerciales generan tanto ganadores como perdedores, y, por lo tanto, producen resultados heterogéneos para diferentes individuos. La diversidad de resultados no se logrará capturar con promedios (datos agregados), algo que se hace evidente en el Gráfico 2.
En este trabajo exploramos la relación entre el ingreso laboral de los trabajadores y el ratio de penetración de las importaciones de su industria, es decir, la proporción del gasto total en bienes y servicios que corresponde a importaciones en dicha industria. Si bien es difícil precisar un evento específico en la historia reciente que podría permitirnos usar una metodología cuasi-experimental, tratamos de controlar variables no observables mediante la construcción de un pseudo-panel, usando encuestas de hogares de 2005 a 2009 (la "Encuesta de hogares" es llevada a cabo por el Gobierno y es la encuesta anual de hogares más grande del país).
Son dos las razones principales para la elección del período estudiado. Primeramente, las encuestas de hogares del período comparten un diseño similar, a diferencia de la "Encuesta continua de hogares 2003-2004", que se llevó a cabo durante dos años, o la "Encuesta de hogares 2011", que tenía un conjunto diferente de unidades primarias de muestreo. En segundo lugar, porque, por ahora, los índices industriales de penetración de importaciones sólo se pueden calcular hasta 2012, dado que las matrices Insumo-Producto no están disponibles para años posteriores.
La ecuación de Mincer (1974) es lo primero que viene a la mente al tratar de explicar el ingreso laboral como una función de otras variables. El estudio de su relación con la exposición al comercio internacional no ha sido la excepción en la literatura.
]]> Nina y Andersen (2004) estiman los efectos de las importaciones y exportaciones sobre el ingreso laboral individual utilizando datos de la encuesta MECOVI 2002. Mediante ecuaciones de Mincer, sus estimaciones puntuales sugieren que, si las exportaciones e importaciones del país se duplicaran, el ingreso laboral promedio de los trabajadores podría cambiar en un 2.7% y -4.7%, respectivamente; ambos coeficientes son significativos al 1% de nivel de significancia. Este trabajo es el único intento de evaluar directamente los efectos de las importaciones sobre el ingreso laboral con microdatos para Bolivia.Galiani y Porto (2010) utilizan secciones cruzadas repetidas para estimar la relación entre los aranceles de las industrias y la estructura salarial en Argentina. Sin discutir las implicaciones de la estructura de sus datos, los autores estiman regresiones agrupadas (pooled regressions) de Mincer para 28 años (1974-2001). Sus resultados muestran que los recortes arancelarios reducen los salarios promedio para los trabajadores en las industrias protegidas y aumentan el skill-premium promedio (sus resultados son significativos al menos al 10% de nivel de significancia).
Sin embargo, ninguno de los dos artículos discute explícitamente la importancia de las variables no observables en la estimación de las ecuaciones de Mincer, y como se argumenta en la próxima sección, esta omisión podría dar lugar a serias inconsistencias en las estimaciones.
Este artículo está organizado de la siguiente forma. La sección 2 presenta nuestra estrategia empírica. La sección 3 describe y explora los datos. La sección 4 muestra nuestros principales hallazgos y sus implicaciones. La sección 5 presenta las conclusiones.
2. Estrategia empírica
Uno de los principales objetivos de nuestra estrategia empírica será intentar controlar por factores inobservables que puedan afectar el ingreso laboral. Aunque ignorar estas variables podría generar estimadores inconsistentes, el problema frecuentemente se pasa por alto. Éste ha sido el caso, por ejemplo, en Nina y Andersen (2004) y Galiani y Porto (2010).
Considérese nuestro caso específico, que es una regresión de los ingresos laborales de los trabajadores sobre una medida de la exposición a las importaciones en sus respectivas industrias. Solo se obtendrá una estimación consistente si tanto la pertenencia a la industria como la exposición a las importaciones en dicha industria no están correlacionadas con el término de error. Pischke y Schwandt (2012) encuentran evidencia a favor de lo contrario para los Estados Unidos, mostrando evidencia de una correlación entre afiliación industrial y características individuales que no varían en el tiempo, como la educación de los padres y la estatura (variables no medidas en las encuestas de hogares anuales). Es probable que un patrón similar pueda surgir en el caso de los trabajadores bolivianos, y en general, asumir que la afiliación de la industria no está correlacionada con las variables no-medidas/no-medibles es un supuesto demasiado fuerte.
Las características individuales fijas pueden controlarse, incluso sin conocerse ni medirse explícitamente, estimando un modelo de efectos fijos utilizando datos de panel (Wooldridge, 2010). Esto siempre y cuando el resto del modelo para la esperanza condicional de la variable este correctamente especificado (de tal forma que los efectos fijos no capturen ruido). Desafortunadamente, no existen datos de panel para nuestras variables de interés en Bolivia2.
Como alternativa al uso de datos de panel, Deaton (1985) propuso usar secciones cruzadas repetidas para estimar un modelo subyacente de efectos fijos, como si existieran datos reales de panel (un "pseudo-panel"). Para una breve explicación, y siguiendo a Verbeek (2008), supongamos que queremos estimar el siguiente modelo de efectos fijos en forma vectorial con datos poblacionales de tamaño N para T períodos de tiempo:
]]>Podemos tomarlo como un grupo de ecuaciones que explican nuestro resultado y. Si definimos C cohortes3 de individuos no superpuestas para cada período, podemos usar estas ecuaciones para llegar a:
![]()
Esta ecuación nos dice que no necesitamos datos individuales para estimar β, ya que podemos recuperar el parámetro a partir de los promedios de las cohortes (sin perder su interpretación inicial).
Sin embargo, en la práctica no tenemos acceso a los datos de panel poblacionales. En cambio, en un pseudo-panel tenemos acceso a muestras independientes de nuestra población para cada período de tiempo, y eso hará que observemos a diferentes individuos en cada punto del tiempo. Como resultado, hay dos consideraciones importantes que deben hacerse en la estimación de los promedios de cohortes de secciones transversales repetidas:
En una contribución esencial a la literatura, Moffitt (1993) demostró que estimar el modelo con promedios de cohortes por mínimos cuadrados ordinarios (OLS) es equivalente a estimarlo por mínimos cuadrados en dos etapas (2SLS) a nivel individual, usando variables identificadoras de cohortes (dummies) por período como variables instrumentales. Por lo tanto, concluye que las cohortes deben cumplir con las restricciones habituales de inclusión y exclusión, incluso si se estima mediante MCO a nivel de cohorte. No se pueden incluir controles invariantes en el tiempo en la regresión (ya que los efectos fijos ya están presentes en el modelo subyacente)4.
Pese a estas limitaciones, Deaton (1985) afirma que la estimación de pseudo-paneles no es necesariamente inferior a la de datos de panel reales, ya que éstos tienen sus propios problemas, como el desgaste (personas que salen del panel) o la pérdida de representatividad de la muestra en el tiempo.
]]> Estimamos la siguiente ecuación por 2SLS:![]()
Donde yitj es el ingreso laboral del individuo i, en la industria j, en el periodo t a precios constantes; penj,t-1 y expibj,t-1 son un rezago del ratio de penetración de importaciones y del ratio exportaciones/PIB en la industria a la que éste está afiliado; Zit es un vector de variables de control y yeart es un vector de efectos fijos de año.
Introducimos el ratio exportaciones/PIB en la respectiva industriaj porque la penetración de las importaciones será más o menos relevante dependiendo de qué proporción de las ventas provengan de clientes internacionales. El conjunto de variables de nivel individual introducidas como variables de control se describen en la sección 3.
Nuestras variables instrumentales son identificadores binarios de cohorte. Las cohortes se construyeron como grupos de personas nacidas en el mismo rango de años y trabajando en la misma industria (se proporcionarán detalles en la sección 3). En promedio, logramos aproximadamente 410 observaciones por cohorte.
La restricción de inclusión para nuestros identificadores de cohortes puede probarse, y en este contexto, significa que debe haber suficiente variación de las variables entre cohortes. Esto es más difícil de lograr en la práctica de lo que parece. Si las variables bajo las cuales se construyen las cohortes no tienen poder predictivo sobre nuestras covariables, nuestros instrumentos serán débiles. Análogamente, en la versión de la cohorte promedio del modelo, en un caso extremo donde todos los promedios de las cohortes de las variables son idénticos para cada cohorte, todos los coeficientes serán iguales a cero, y las relaciones causales existentes no serán identificables (Verbeek, 2008).
La restricción de exclusión es más difícil de probar empíricamente, pero creemos que es razonable pensar que se cumplirá. Específicamente, asumimos que: i) la edad solo afecta a los ingresos laborales de un trabajador a través de su relación con los años de escolaridad y la experiencia laboral (nuestra especificación para estas dos variables toma en cuenta el hecho de que los retornos por edad comienzan a disminuir en un cierto punto), y ii) la pertenencia a una industria afecta al ingreso laboral solo a través del desempeño de la industria en los mercados locales e internacionales -medidas por nuestras dos variables de nivel industria- y el conjunto de características individuales que explícita e implícitamente tomamos en cuenta.
En nuestra especificación, utilizamos variables rezagadas de exposición a las importaciones, como en Ebenstein et al. (2014). Debido a las rigideces del mercado laboral, tales como los contratos temporales y las fricciones de búsqueda, la penetración de las importaciones solo podría afectar al ingreso laboral después de transcurrido algún tiempo5. Nótese que no surgen problemas de simultaneidad, ya que los ingresos laborales individuales actuales no pueden afectar la penetración de las importaciones industriales pasadas.
Un supuesto implícito adicional es el de ausencia de sesgo de selección. Podrían existir características no observadas y variables en el tiempo de los individuos que determinen en qué industria deciden trabajar (éstas no están controladas en la regresión). Si este fuera el caso, los individuos escogen su tratamiento en base a ellas, y no se podría aislar el efecto de la exposición al comercio sobre sus ingresos laborales.
Hasta ahora nos hemos centrado en las ventajas estadísticas de un enfoque de pseudo-panel, pero puede haber una ganancia aún mayor en términos de relevancia conceptual. Trabajar con más de un período de tiempo nos permite capturar los efectos de la penetración de las importaciones en una industria a lo largo del tiempo (en lugar de tener en cuenta sólo las variaciones entre industrias). Esto ciertamente representa una gran ventaja de un enfoque de pseudo-panel sobre una estimación de sección cruzada.
]]>3. Los datos
Utilizando las Matrices Insumo-Producto (MIP) del país a precios constantes de 1990, la penetración de las importaciones para el individuo i en el año t se calculó como la fracción de las importaciones en el consumo nacional para el sector j:
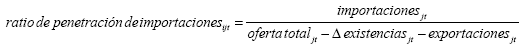
Donde j representa cada una de las 35 actividades industriales enumeradas en las MIP. Las variaciones de existencias y las exportaciones se restan de la oferta total para obtener el consumo interno del país para la industria j en el año t.
El aumento de las importaciones que se muestra en el Gráfico 1 ha sido una fuente de gran preocupación en los medios6. Varios comentaristas han interpretado con frecuencia y erróneamente un aumento en la competencia de las importaciones que no les permitió crecer a las empresas durante el boom del comercio. La penetración de importaciones, que representa la participación de mercado de los productores extranjeros, es una medida mucho mejor de la competencia de importaciones en una industria determinada. El Gráfico 2 muestra que los cambios en dicha variable no han sido tan grandes como los observados en otros indicadores comerciales para el mismo período (moviéndose sólo en el rango del 16 al 18%).
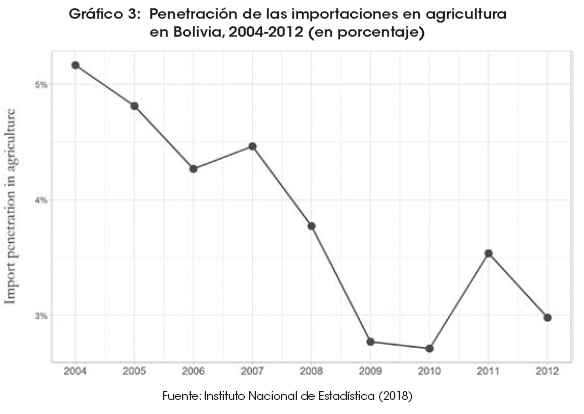
La agricultura y la manufactura son comúnmente vistas como las industrias más severamente afectadas por la competencia de las importaciones. Los Gráficos 3 y 4 muestran la evolución del ratio de penetración de las importaciones en la agricultura y la manufactura entre 2004 y 2012. Algo sorprendente es que el porcentaje de consumo interno de productos agrícolas importado disminuyó del 5% en 2004 al 3% en 2012, solamente con pequeñas fluctuaciones en los años de estudio. La industria manufacturera está más expuesta a la competencia del extranjero y la penetración de las importaciones en el sector aumentó del 36% en 2004 al 37% en 2012 (aun así, es un cambio no tan grande como se suele pensar). Esto sugiere que el aumento de las importaciones que se muestra en el Gráfico 1 fue de una magnitud similar al aumento del consumo de productos producidos por empresas nacionales.
]]> No obstante, existe una gran heterogeneidad en el grado de competencia del extranjero que los productores de diferentes productos agrícolas han venido enfrentando. Cálculos basados en los datos presentados en Prudencio (2017) sugieren que la penetración de las importaciones aumentó del 1% en 2005 al 9% en 2015 para los tomates, del 1 al 8% para las leguminosas (como las lentejas) y del 3 al 7% para frutas y derivados, ambos en el mismo periodo. Por lo tanto, el Gráfico 3 representa solo una tendencia general.
Es importante mencionar que los datos de afiliación industrial de las encuestas de hogares para los años 2005-2009 siguen la Clasificación Boliviana de Actividades Económicas de 2005 (CAEB) que son distintos a la clasificación industrial de las MIP. Por lo tanto, es necesario un procedimiento de emparejamiento entre las industrias de las encuestas (CAEB-2005) y las industrias de la MIP. Para lograr la precisión suficiente, unimos un total de 161 categorías dela CAEB a 3 dígitos a las 35 industrias de las MIP7.
Nuestra variable dependiente, el ingreso laboral, se mide en bolivianos de 2016. Las variables de control a nivel individual incluyen: i) años de escolaridad, ii) un polinomio de la experiencia laboral de segundo grado, y iii) las ocho categorías de condiciones de empleo del trabajador (por ejemplo, empleador, empleado)8.
A continuación, describimos la construcción de cohortes. Sobre la base del rango común de años de nacimiento en todas las encuestas, consideramos individuos nacidos entre 1941 y 1995, que se agruparon en tres cohortes: las primeras dos cohortes de 18 años y una cohorte final de 19 años9. Luego, agrupamos a los trabajadores de acuerdo con su afiliación industrial en cuatro cohortes, siguiendo la CAEB-2005 (agricultura, minería e hidrocarburos, manufactura y otras industrias). Terminamos con 60 variables de cohorte: 3 para los años de nacimiento, 4 para la afiliación industrial y 5 para cada año de encuesta (3 * 4 * 5 = 60)10.
4. Resultados
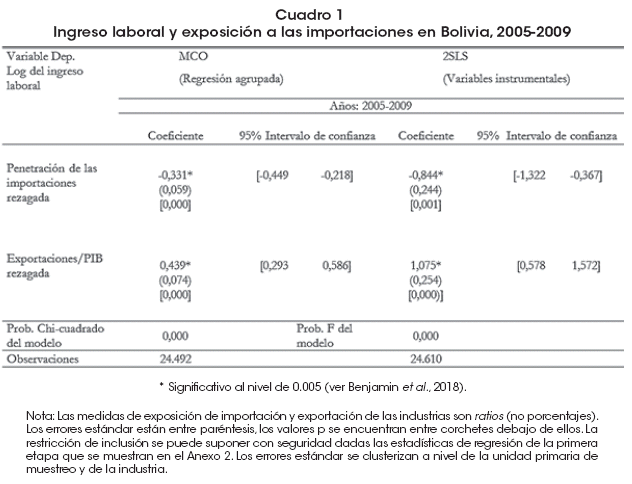
Nuestros resultados se presentan en el Cuadro 1. Presentamos resultados tanto para la regresión MCO de secciones cruzadas repetidas agrupadas como para la estimación de pseudo-panel por 2SLS11.
Recordemos que en la columna "MCO (regresión agrupada)" simplemente tomamos los datos de todos los individuos y periodos y estimamos la regresión de Mincer descrita en la sección 2 (sin efectos fijos) por mínimos cuadrados ordinarios, ignorando la dimensión temporal, como en Galiani y Porto (2010).
En contraste, en la columna "2SLS (variables instrumentales)" se corre un modelo de mínimos cuadrados por dos etapas. En la primera etapa, se corre una regresión de las variables independientes contra el vector de variables binarias que identifican a cada individuo dentro de una cohorte. En la segunda etapa, se toman los valores de las variables independientes predichos por aquellas variables binarias para estimar la regresión de la sección 2 (ambas estimaciones se hacen por mínimos cuadrados ordinarios).
En aras de una comparación equitativa entre ambas estimaciones, los resultados de MCO incluyen controles invariantes en el tiempo (género y primer idioma) que se consideran automáticamente en nuestra estimación 2SLS. También presentamos los resultados de nuestra variable de exposición a la exportación, ya que pueden ser de interés y no se presentan sesgos de simultaneidad.
]]> Los errores estándar se clusterizan a los niveles de la unidad primaria de muestreo y a nivel de la industria. Según lo recomendado por Abadie et al. (2017), los errores estándar deben clusterizarse cuando: i) exista un diseño de encuesta complejo que implique la clusterización (en lugar de un muestreo aleatorio), o ii) cuando el tratamiento es asignado por grupos. Ambas condiciones necesarias están presentes en nuestro caso12, ya que la "Encuesta de hogares" boliviana tiene un diseño de encuesta complejo y la penetración de las importaciones en una industria afecta a todos sus trabajadores (como grupo).Nuestros resultados de la estimación de pseudo-panel sugieren que un aumento del 1 % en la penetración de las importaciones en una industria disminuye el ingreso laboral real para sus trabajadores en un 0.84% el año siguiente, en ausencia de correlación con la exposición a las exportaciones13. Esta estimación debe entenderse en el contexto de variaciones pequeñas de la penetración de las importaciones de un año a otro. Entre 2004 y 2012, el cambio promedio en la penetración de las importaciones de todas las industrias de un año a otro fue del 1.85%. Además, ni una sola industria en nuestra base de datos presentó un aumento (o disminución) continuo de la penetración de importaciones. En el peor de los casos, la penetración de las importaciones de una industria aumentó en 6 de los 9 años en nuestro período de estudio. Esto significa que el efecto acumulado sobre los salarios en el decenio del auge de las importaciones puede no haber sido muy grande.
También es interesante ver que la estimación de regresiones agrupadas, que ignora por completo las variables no observables, es significativamente diferente. Los intervalos de confianza estimados al 95% para el efecto de la penetración de importación no se superponen con los de la estimación de pseudo-panel14. Dados los argumentos estadísticos a favor del uso de esta última técnica (argumentos descritos en la sección 2), los futuros investigadores deberían pensar dos veces antes de estimar una regresión agrupada en lugar de una regresión de pseudo-panel, o al menos reportar ambos resultados, especialmente en el caso de ecuaciones de Mincer, ya que muchos factores no-medidos/no-medibles podrían influir en los ingresos.
Nuestras estimaciones de pseudo-panel también encuentran evidencia de mayores ingresos laborales en las industrias expuestas a las exportaciones (para trabajadores similares). Esto tiene implicaciones importantes y debería explorarse a mayor profundidad en futuras investigaciones.
5. Conclusiones
El incremento sustancial de las importaciones en los últimos años ha recibido mucha más atención en los medios que en la academia. De cierta forma, los temores parecen estar justificados. Un incremento de la penetración de las importaciones en una industria puede ocasionar una disminución de los salarios reales de sus trabajadores. Sin embargo, la evolución reciente del indicador de penetración de las importaciones (que se ha mantenido en el rango de 16 a 18%) muestra que el incremento del gasto en bienes y servicios importados no se aleja del incremento en el gasto en bienes y servicios producidos en el país. Es decir, tanto productores del extranjero como productores nacionales se han beneficiado del incremento del ingreso de los residentes del país a través de mayores ventas.
No obstante, nuestros resultados dan a entender que se debe prestar atención a industrias específicas que presenten un alto grado de competencia de productos importados, pues sus trabajadores podrían verse afectados. Estudios específicos para dichas industrias podrían determinar la mejor forma de proceder en términos de políticas públicas.
Por otra parte, hemos discutido la importancia de controlar por efectos no observables fijos en ecuaciones de Mincer. Nuestra estimación del pseudo-panel por 2SLS resulta sustancialmente diferente a la estimación agrupada por MCO, en la cual no se considera la presencia de efectos fij os. Por ello es que recomendamos enfáticamente a futuros investigadores considerar los serios problemas de inconsistencia que surgirían en este tipo de estimaciones al no considerar la presencia de variables no-observables/no-medibles. Específicamente, se propone utilizar secciones cruzadas repetidas al momento de estimar ecuaciones de Mincer mediante el uso de técnicas de pseudo-panel para verificar la sensibilidad de los resultados encontrados a esta especificación alternativa.
]]>Notas
1 Ejemplos de trabajos previos sobre los efectos del boom exportador son Lay, Thiele y Weibelt (2008) y Barja y Zavaleta (2016). Algunos otros estudios han considerado parcialmente los efectos de los cambios en las importaciones, como es el caso de Gonzáles (2016).
2 Vale la pena señalar que los efectos fijos individuales no siempre se han incluido, incluso en los casos en que había datos de panel disponibles (Autor et al., 2014; Ebenstein et al., 2014), posiblemente minimizando la importancia de los no observables a nivel individual.
3 Entendidas como grupos de personas con características compartidas.
4 Moffitt (1993) señala que, como en el caso de los datos de panel, en un contexto de pseudo-panel no es posible Identificar los parámetros del modelo si el vector de covariables contiene variables invariantes en el tiempo.
5 El mismo argumento aplica al rezago del ratio exportaciones/PIB por industrias.
6 Algunos ejemplos: "Vetan importación de papa y liberan la venta de girasol” (La Razón, 2012, http://www.la-razon.com/economia/Vetan-importacion-liberan-venta-girasol_0_1611438860.html);“Los alimentos del extranjero desplazan a la producción local” (Página Siete, 2015, https://www.paginasiete.bo/economia/2015/9/12/alimentos-extranjero-desplazan-produccion-local-69805.html); "Importación de calzados, cuero y textiles de China crece en 176%" (Página Siete, 2015, https://www.paginasiete.bo/economia/2015/9/6/importacion-calzados-cuero-textiles-china-crece-176-69134.html) y "Ante la bonanza ‘Perdimos una época de oro’" (El Día, 2018, https://www.eldia.com.bo/index.php?cat=357&pla=3&id_articulo=259613).
7 Para una descripción completa del procedimiento de emparejamiento entre la clasificación industrial CAEB a 3 dígitos y las MIP, véase el Anexo 1.
8 Las personas de la séptima categoría, que comprenden "trabajadores familiares o aprendices sin remuneración", son retirados de la base de datos (ya que las remuneraciones son precisamente nuestra variable de interés). También fueron retirados los trabajadores que no reportaron percibir ningún ingreso laboral.
]]> 9 Es decir que la primera cohorte de edad comprende a los individuos nacidos entre los años 1941 y 1958, la segunda a los nacidos entre 1959 y 1976 y la tercera a los nacidos entre 1977 y 1995.10 El supuesto de no variación en el tiempo se cumple para el año de nacimiento, pero el caso de la pertenencia a una industria es menos claro. La revisión bibliográfica de Pavcnik (2017) sugiere que los ajustes en el mercado laboral en países en desarrollo están vinculados principalmente a los salarios, no a los cambios en el estado del empleo. En Bolivia, según datos de panel de la Encuesta Continua de Empleo 2016-2017, de acuerdo a cálculos generales, la movilidad entre nuestros 4 grupos de industrias para un período de cuatro años se encontraría entre el 3.7 y el 20%.
11 Algunos diagnósticos del modelo se pueden encontrar en el Anexo 2.
12 Y también condiciones adicionales que hacen necesario clusterizar, especificadas en Abadie et al. (2017)
13 La estimación puntual del efecto de la penetración de importaciones usando la corrección de muestra finita de Devereux (2007b) es -0.71 %.
14 El número diferente de observaciones en ambas regresiones se explica por los missing values en la variable "primer idioma"; omitiendo la variable, los intervalos de confianza cambian en menos de 0.01 %.
Fecha de recepción: 5 de diciembre de 2018
Fecha de aceptación: 25 de marzo de 2019
Manejado por IISEC
]]>Referencias
1. Abadie, A.; Athey, S.; Imbens, G. W. y Wooldridge, J. (2017). When should you adjust standard errors for clustering? (Nº. w24003). National Bureau of Economic Research.
2. Autor, D. H.; Dorn, D.; Hanson, G. H. y Song, J. (2014). “Trade adjustment: Workerlevel evidence”. The Quarterly Journal of Economics, 129(4), 1799-1860.
3. Autor, D. H.; Dorn, D. y Hanson, G. H. (2016). “The china shock: Learning from labormarket adjustment to large changes in trade”. Annual Review of Economics, 8, 205-240.
4. Banco Mundial, World Development Indicators. (2018). "Volumen de importaciones Bolivia". [ Links ]
5. Barja, G. y Zavaleta, D. (2016). “Disminución de precios de commodities en un ambiente de enfermedad holandesa y bendición/maldición de los recursos naturales”. Revista Latinoamericana de Desarrollo Económico, (25), 7-40.
6. Benjamin, D. J.; Berger, J. O.; Johannesson, M.; Nosek, B. A.; Wagenmakers, E. J.; Berk, R.; Cesarini, D… (2018). “Redefine statistical significance”. Nature Human Behaviour, 2(1), 6.
7. Deaton, A. (1985). Panel data from time-series of cross-sections. Econometric Research Program, Princeton University. [ Links ]
8. Devereux, P. J. (2007a). “Small‐sample bias in synthetic cohort models of labor supply”. Journal of Applied Econometrics, 22(4), 839-848.
]]> 9. ---------- (2007b). “Improved errors-in-variables estimators for grouped data”. Journal of Business & Economic Statistics, 25(3), 278-287.10. Ebenstein, A.; Harrison, A.; McMillan, M. y Phillips, S. (2014). “Estimating the impact of trade and offshoring on American workers using the current population surveys”. The Review of Economics and Statistics, 96(4), 581-595.
11. Galiani, S. y Porto, G. G. (2010). “Trends in Tariff Reforms and in the Structure of Wages”. The Review of Economics and Statistics, 92(3), 482-494.
12. Gonzáles, R. (2016). “External Shocks, Dutch Disease and Informality in Bolivia”. CIESS Econométrica-Universidad Mayor de San Andrés. Working Paper.
13. Instituto Nacional de Estadística, Estadísticas de Comercio Exterior (2018). “Penetración de las importaciones y remuneraciones reales en Bolivia”. La Paz, Bolivia.
14. ---------- (2005). “Clasificación de actividades económicas de Bolivia”, CAEB-2005. Disponible en: http://anda.ine.gob.bo/ANDA4_2/index.php/catalog/274/download/1076
15. Lay, J.; Thiele, R. y Wiebelt, M. (2008). “Resource booms, inequality, and poverty: The case of gas in Bolivia”. Review of Income and Wealth, 54(3), 407-437.
16. Mincer, J. (1974). “Schooling, Experience, and Earnings”. Human Behavior & Social Institutions, Nº 2, National Bureau of Economic Research.
17. Moffitt, R. (1993). “Identification and Estimation of Dynamic Models with a Time Series of Repeated Cross-Sections”, Journal of Econometrics, (59), 99-123.
18. Nina, O. y Andersen, L. E. (2004). “Regional integration and poverty: A case study of Bolivia” (Nº 06/2004). Institute for Advanced Development Studies.
]]> 19. Pavcnik, N. (2017). “The impact of trade on inequality in developing countries” (Nº w23878). National Bureau of Economic Research.20. Pischke, J. S. y Schwandt, H. (2012). “A cautionary note on using industry affiliation to predict income” (Nº w18384). National Bureau of Economic Research.
21. Prudencio, J. (2017). “El sistema agroalimentario y su impacto en la alimentación y nutrición”. Disponible en: http://cdn.biodiversidadla.org/content/download/147349/1121408/version/1/file/El+sistema+agroalimentario+en+Bolivia+y+su+impacto+en+la+alimentaci%C3%B3n+y+nutrici%C3%B3n.odt
22. Sachs, J. D., y Warner, A. M. (1995). “Natural resource abundance and economic growth” (Nº w5398). National Bureau of Economic Research.
23. Verbeek, M. y Nijman, T. (1992). “Can cohort data be treated as genuine panel data?”. En: Panel data analysis (9-23). Physica-Verlag HD.
24. Verbeek, M. (2008). “Pseudo-panels and repeated cross-sections. In the econometrics of panel data” (369-383). Springer, Berlin, Heidelberg.
25. Wooldridge, J. M. (2010). Econometric analysis of cross section and panel data. MIT Press. [ Links ]
Descripción del emparejamiento entre la CAEB-2005-3-dígitos y la Matriz Insumo-Producto
El cálculo de la penetración de las importaciones proviene de la siguiente expresión:

Los datos provienen de la MIP en miles de bolivianos constantes de 1990, y comprenden 35 actividades.
]]> A cada una de las 35 actividades de la MIP se le asignó una o más actividades de la CAEB-2005-3 dígitos. Para que una actividad de la CAEB pueda ser elegida para ser emparejada con alguna actividad de la MIP se utilizó el criterio de que ésta debería presentar importaciones distintas de cero en la clasificación CIIU-3 dígitos. Por lo tanto, todas aquellas actividades de la CIIU que no tienen importaciones (que no se pueden marcar en el sistema de consultas de comercio del INE) fueron excluidas en el emparejamiento CIIU-CAEB, y por lo mismo del emparejamiento CAEB-MIP. Bajo estos criterios, el emparejamiento final CAEB-MIP lo realizaron los autores guiándose por la descripción detallada de actividades del documento de la CAEB-2005 del INE (véase INE, 2005).
Algunas actividades económicas en el emparejamiento CAEB-MIP están solapadas, es decir, que a dos actividades de la MIP le corresponden una misma actividad de la CAEB. Por ejemplo, al código 011 CEAB le corresponde tanto la actividad 1 como la actividad 3 de la MIP. En estos casos, para fines de la asignación de un solo código MIP a los individuos de las encuestas de hogares se sumaron las actividades de la MIP que estaban solapadas. En el ejemplo anterior deberíamos sumar las actividades 1+3. Sin embargo, nótese que para este ejemplo específico no sumamos 1+3, debido a que la actividad 3 de la MIP (COCA) no presenta importaciones, y sumarla a la actividad 1 solo introduciría sesgo en el cálculo de la penetración de esta actividad.
Se dejaron fuera del análisis aquellas actividades de la MIP que:
i. Tenían un grado de penetración de importaciones igual a cero.
]]> ii. A pesar de que tenían un grado de penetración de importaciones distinto de cero, no encontraron correspondencia con ninguna actividad de la CAEB, debido a que ésta no tenía ninguna correspondencia con ninguna actividad de la CIIU, y por lo tanto no presentaba importaciones.
Diagnósticos del modelo 2SLS
2.1. Ajuste de la primera etapa de 2SLS
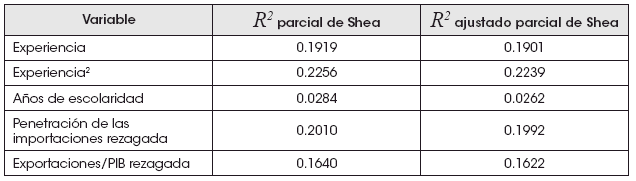
El proceso de elección de las cohortes para la aplicación de la metodología de pseudo-panel tuvo como objetivo central el conseguir evitar el problema de los instrumentos débiles y satisfacer de la mejor forma posible la restricción de inclusión de la estimación por variables instrumentales.
Se probaron definiciones alternativas con cambios en los rangos de años elegidos y agrupaciones por actividades económicas diferentes. De entre todas ellas, la tomada finalmente es la que mejores bondades de ajuste conseguía en la primera etapa (logrando al mismo tiempo hacer razonable el cumplimiento de la restricción de exclusión).
2.2. Factores de inflación de varianza

2.3. Normalidad de los residuos

El histograma de los residuos (en barras) se contrasta con la distribución normal teórica. Se rechaza la hipótesis nula de normalidad del término de error, pero dado el número de observaciones y la distribución observada de los residuos, podemos recurrir a la propiedad de normalidad asintótica del estimador de 2SLS (Wooldridge, 2010) para justificar el uso de inferencia con distribuciones de probabilidad teóricas.
]]>