Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkRevista de Medio Ambiente y Mineria
Print version ISSN 2519-5352
REV. MAMYM no.5 Oruro 2018
ARTÍCULOS
Aplicación de Redes Neuronales Artificiales de Base Radial y Geoestadística para la Interpolación/Reconstrucción de Base de Datos de Leyes de Cobre.
Application with Radial Basis Neural Netwoks and Geostatistical for Interpolation/reconstruction for Database in copper grade.
Freddy A. Lucay1, Felipe D. Sepúlveda2, José Delgado3
1. Departamento de Ingeniería Química y Procesos de Minerales, Universidad de Antofagasta, Chile, Av. Angamos 610. Email: freddy.lucay@uantof.cl.
2. Departamento de Ingeniería en Minas, Universidad de Antofagasta, Chile, Av. Angamos 610. Email: felipe.sepulveda@uantof.cl.
3. Departamento de Ingeniería en Minas, Universidad de Antofagasta, Chile, Av. Angamos 610. Email: jose.delgado@uantof.cl
Resumen
Para cuantificar un depósito mineral, es esencial determinar su calidad (ley) y su cantidad (tonelaje), y para realizarlo, existen dos etapas que deben ser cumplidas: 1) planificación y ejecución de una malla de sondajes, donde se determinan los elementos/compuestos de interés, 2) creación de una base de datos y la aplicación de técnicas matemáticas para el cálculo de la ley/tonelaje del depósito.
Éstas etapas presentan las siguientes consideraciones: 1) la planificación de la malla, el número de sondajes y los elementos/compuestos estudiados, dependen del capital económico del proyecto y se ejecuta en función de la experiencia del ingeniero/geólogo a cargo, 2) la base de datos, es generada frecuentemente con los datos más relevantes, 3) la evaluación matemática depende de la experiencia del ingeniero y las herramientas computacionales que posee.
Éstas consideraciones, pueden generar incertidumbre en la calidad del resultado final, por lo tanto, el objetivo del trabajo, es el de realizar un análisis en la base de datos para mejorar la cantidad de información (interpolación y reconstrucción de datos), aplicando Redes Neuronales de Base Radial (RNBR), cuyos resultados son comparados con los de la Regresión Polinomial (RP) y Geoestadística (Ge). Tanto las expresiones matemáticas, como los resultados de los ajustes y sus análisis (ventajas/desventajas), serán presentados.
Los resultados obtenidos indican que el uso de la RP, nunca fue adecuado, por la deficiencia en su estimación, mientras que los resultados de la RNBR, siempre presentaron errores muy bajos y compatibles con la geoestadística, manteniendo la tendencia espacial de los datos reconstituidos.
Palabra clave: Leyes, Minería, Interpolación/reconstrucción, Sondajes, Geoestadistica.
Abstract
To quantify a mineral deposit, it is essential to determine its quality (grade) and its quantity (tonnage), so there are two stages that must be met are the following: 1) planning and execution of a mesh of a drillhole where the elements/compounds of interest are determined, 2) creation of a database and the application of mathematical techniques to calculation of the grade/tonnage of the deposit under study.
These stages present the following considerations: 1) the planning of the mesh, the number of drillholes and the elements/compounds studied depends on the economic capital of the project and is carried out according to the experience of the engineer/geologist in charge, 2) The database is often created with the most relevant data, 3) The mathematical evaluation depends on the engineer´s experience and the computational tools he has.
These considerations may generate uncertainty in the quality of the final result, therefore, the aim of this research is to perform an analysis in the database to improve the amount of information (interpolation and reconstruction of data), applying Neural Networks of Radial Base (NNRB), being compared their results with the Polynomial Regression (PR) and Geostatistics (Ge). The mathematical expressions and the results of the adjustments and analyzes (advantages/disadvantages.
The obtained results indicate that the use of PR, was never adequate, due to the deficiency in its estimation, while the results of the NNRB, always presented very low errors and compatible with Ge, maintaining the spatial tendency of the data repositioned.
Keywords: copper grade, Mining, Interpolation/Reconstruction, drilling, geostatistics.
Introducción
Todo depósito mineral presenta múltiples complejidades geológicas, algunas de éstas son: mineralizaciones no homogéneas, alteraciones geológicas, diferentes litologías y niveles freáticos, tamaño del depósito, etc. Éstas complejidades hacen que la determinación de las leyes de las especies valiosas, sean complejas (Akbar 2012). Por lo tanto, es necesario poseer información de calidad y que tenga la cantidad mínima requerida, para que se pueda generar una buena cuantificación.
La obtención de la información requerida, es realizada principalmente por medio de sondajes. Los sondajes van mapeando distintas zonas en los tres ejes de coordenadas (norte-sur, este-oeste y profundidad), y por medio de éstos, se logran estimar las leyes. Una vez que toda la información de los sondajes es recolectada, se genera la base de datos, la cual georreferencia una información relevante, como por ejemplo, la ley de los elementos principales, previamente definidos dentro del proyecto, y a ésta información, se le asigna una coordenada específica. Con toda esta información, se realiza el análisis de los datos aplicando la geoestadística (Jalloh et al. 2016), área matemática, que ha va siendo utilizada hace aproximadamente 50 años. Esta disciplina reúne métodos que permiten modelar estructuras, considerando relaciones espaciales por medio de funciones denominadas variogramas (Vr), el siguiente paso es el de realizar una interpolación espacial mediante los métodos denominados kriging (Melo, 2012; Akbar, 2012).
Los métodos kriging tienen su génesis en los trabajos de Sichel (1947) y Krige (1951), el primer autor realizó estimaciones de reservas de oro en minas sudafricanas, bajo el supuesto de que las mediciones realizadas eran independientes, idea incorrecta, pues existen zonas más ricas que otras. Posteriormente, una aproximación más robusta para estimar las reservas de oro en estas minas sudafricanas, fue realizada por el geólogo Krige, quien propuso una variante del método de medias móviles, que puede ser considerado como el equivalente al kriging (Kr) simple.
Las interpolaciones realizadas con los métodos Kr, permiten estimar la ley media del elemento de valor en un volumen de material que se define como, bloque (Bargawa et al. 2016), a partir del cual y mediante el criterio de costo de oportunidad implementado para block caving (el cual incorpora la secuencia minera), se determinan las reservas extraíbles en el bloque (De la Huerta 1994).
Todo el proceso de estimación geoestadística (Ge), tiene como base principal, la recolección suficiente de información de calidad (rigurosidad en la toma de la muestra y determinación de su ley) y cantidad (numero suficientes de muestras para caracterizar el bloque), que fue obtenida por medio de sondajes. Pero en la práctica, no necesariamente se poseen la calidad y cantidad de datos necesarios para hacer una estimación del bloque, esto debido a distintos factores: planificación deficiente en las campañas de sondajes, complejidades de colocación de equipos por terrenos abruptos o inaccesibles, recursos económicos y/o técnicos insuficientes para generar un buen mapeo de los bloque en estudio (número de sondajes), recursos económicos y/o técnicos insuficientes para realizar análisis de múltiples elementos (muestreos dentro del sondaje), generación de mallas de sondajes irregulares (por ejemplo, focalizarse en la evaluación de algunas zonas en desmedro de otras) (Akbar 2012; Zamora 2013; Jalloh et al. 2016) o generación de muestras con distancias no equidistantes (debido muchas veces a la inexistencia de un procedimiento de muestreo sistemático o por decisiones que se ajustan a la experiencia del operador, ingeniero o geólogo).
Las consideraciones anteriormente mencionadas, generan una falta u omisión de información dentro de la base de datos, generando incertidumbre en los posteriores cálculos Ge. Las alternativas de solución a este inconveniente, son principalmente dos: 1) reprocesar los testigos de los sondajes, 2) reconstrucción de la base de datos. La primera opción en muchos casos es imposible, debido a los altos costos asociados a la realización del análisis y a la posible inexistencia de los testigos de los sondajes. Para el segundo punto, se han desarrollado métodos de aproximación teórica, categorizadas en dos grupos: el primer grupo utiliza la Ge, y el segundo grupo utiliza técnicas matemáticas, para la reconstrucción de datos (Drymonitis 2015). Se debe tener en cuenta que cualquier reconstrucción de la información, debe cumplir lo siguiente: 1) presentar el menor error relativo posible entre los datos reales y los datos reconstruidos, 2) mantener la tendencia espacial entre los datos reales y los datos reconstruidos y 3) que los algoritmos sean fáciles de aplicar y los requerimientos computacionales sean bajos.
En el área de la Ge, Pizarro (2011) analizó los datos utilizando la Ge tradicional y la simulación condicional la utilizó para la reconstrucción de la información. A su vez, Emery (2012), extendió el trabajo anterior analizando con mayor detalle los datos mediante histogramas y su implementación de la simulación condicional para la reconstrucción de los mismos. Y Zamora (2013), realizó sub-divisiones a lo largo del sondaje, para generar estimaciones de solubilidades locales de cobre (relación entre el cobre soluble y cobre total), y con esto, verificar la información con Ge.
En el caso de las técnicas matemáticas de reconstrucción de información, se aplica como criterio principal, la interpolación por medio de distintos metamodelos (Li y Heap 2014), por ejemplo, Dubrule y Kostov (1986), implementaron polinomios cuadráticos para la obtención de datos. Sin embargo, los polinomios suelen presentar un error considerable en su ajuste, cuando los datos presentan un comportamiento complejo.
Una alternativa a la interpolación clásica, es la utilización de distintos tipos de metamodelos en base a polinomios, llamadas, Redes Neuronales Artificiales (RNA). Las RNA están inspiradas en el comportamiento y función del cerebro humano (McCulloch y Pitts 1943), en particular del sistema nervioso, que está compuesto por redes de neuronas biológicas que poseen bajas capacidades de procesamiento, sin embargo, toda su capacidad cognitiva se sustenta en la conectividad de éstas. Las RNA son capaces de aprender y resolver una amplia gama de problemas complejos.
Las RNA con Propagación Hacia Adelante (RNAPD), son un tipo especial de RNA y tienen la capacidad de aproximar cualquier función continua (Hornik 1991; Park y Sandberg 1991). Las RNAPD están organizadas en capas y están formadas por un gran número de elementos simples de procesamiento, llamados neuronas. Los elementos básicos del modelo son: a) un conjunto de conexiones caracterizadas por un peso (![]() , b) funciones base que ponderan las entradas que llegan al nodo, y c) funciones de activación que limitan la amplitud de la salida del nodo, (Hilera y Martínez 1995; Yao 1993). Los pesos de las conexiones son determinados mediante el entrenamiento que recibe la RNAPD a través de un algoritmo. El entrenamiento puede ser clasificado en off-line u on-line (Saad 2009; Nakama 2009), y supervisado o no supervisado (Rumelhart y Zipser 1985; Kaelbling et al. 1996).
, b) funciones base que ponderan las entradas que llegan al nodo, y c) funciones de activación que limitan la amplitud de la salida del nodo, (Hilera y Martínez 1995; Yao 1993). Los pesos de las conexiones son determinados mediante el entrenamiento que recibe la RNAPD a través de un algoritmo. El entrenamiento puede ser clasificado en off-line u on-line (Saad 2009; Nakama 2009), y supervisado o no supervisado (Rumelhart y Zipser 1985; Kaelbling et al. 1996).
Las RNA tipo perceptrón multicapa (PM) y redes neuronales de base radial (RNBR), son dos ejemplos de las RNAPD. Las PM, son probablemente el tipo de red neuronal más implementada en la literatura. Ésto, se debe al desarrollo eficiente del algoritmo de entrenamiento Backpropagation (Werbos 1975; Rumelhart et al. 1986). Sin embargo, el proceso de entrenamiento, muestra una lenta convergencia y suele caer en óptimos locales (Zhao y Huang 2007). Las RNBR, han surgido como una alternativa, pues presentan una topología más compacta que otras RNA (Lee y Kil 1991) y su velocidad de entrenamiento es más rápido, debido al carácter local de las neuronas (Moody y Darken 1989).
Las RNBR, han sido ampliamente aplicadas en distintas áreas de la ingeniería, por ejemplo, Jin et al. (2001) realizó un estudio comparativo de RNBR con otros metamodelos, en base a múltiples criterios de modelado; mientras que Powell (1987), utilizó RNBR, para ajustar contornos arbitrarios de superficies de respuesta, tanto determinísticas como estocásticas, a su vez, Tu y Barton (1997), indican que las RNBR proporcionan metamodelos eficientes, para la simulación de circuitos eléctricos. Las RNBR también han sido utilizadas como una alternativa de ajuste en ecuaciones con derivadas parciales (Arora y Bhatia, 2017), además las RNBR, han sido utilizadas para determinar propiedades de distintos fluidos (Zou et al. 2013) y para el modelamiento medioambiental (Li y Heap 2011).
En la minera, la implementación de RNBR, ha sido desarrollada con variadas aplicaciones (Kapageridis 2002). Pero específicamente en investigaciones para cuantificar elemento/compuestos y así determinar su cantidad/calidad para su evaluación económica, se pueden mencional los siguientes: Uno de los primeros trabajos desarrollados, fue el de Kapageridis y Denby (1998), quienes aplicaron RNBR, para determinar la ley espacial en 2D, de un yacimiento de cobre/oro con información proveniente de 77 sondajes. Posteriormente, Kapageridis y Denby (2000), desarrolló la aplicación (GEMMet -II) para el programa Vulcan, la cual, permite realizar estimaciones de leyes en 3 dimensiones y comparar los resultados de Ge con los de RNBR. Los autores comentan que el tiempo de cálculo utilizado por RNBR, es de aproximadamente 10 horas, mientras que con la Ge, se utilizó sólo 10 min. Entre tanto, Yamamoto (2002), realizó la evaluación de la ley de un yacimiento de cobre con la utilización de una malla irregular de sondajes y un diagrama de bloques. Matías et al. (2004), evaluó un yacimiento de sal con Ge, y compararon los resultados con RNBR. A su vez, Lin y Chen (2004), implementaron en su trabajo la RNBR, incorporando modelos de Vr. Estos autores comentan que RNBR, presenta compatibilidad matemática con la Ge. Chatterjee et al. (2006), estimó la ley de la caliza, usando RNA, específicamente, aplicó RNBR con el propósito de estimar la ley de distintos componentes de la caliza (CaO, Al2O3, Fe2O3 y SiO2). Estos autores realizan un análisis estadístico y geoestadístico de la información obtenida, y posteriormente es comparada con los resultados entregados por el Kr ordinario. Mahmoudabadi et al. (2009), realizó la estimación de leyes de yacimientos mediante RNBR, entrenadas con algoritmos genéticos. Samanta y Bandopadhyay (2009), realizaron la estimación de la ley de oro de un yacimiento mediante RNBR, entrenadas con Algoritmos Evolutivos. Chatterjee et al. (2010), implementó RNBR con Algoritmos Genéticos, para la proyección de leyes de un yacimiento de plomo/zinc. Kapageridis y Triantafyllou (2011), realizaron una actualización del programa GEMMet-II, para desarrollar la aplicación LavaNet. Esta aplicación es utilizada en el programa minero Vulcan e incluye RNBR y mapas de Kohonen, para determinar las leyes de los yacimientos. Fazio y Roisenberg (2013), realizaron una comparación analítica entre RNBR y Kr. Estos autores reiteran en su trabajo que, la RNBR presenta compatibilidad matemática con la Ge. Hillier et al. (2014) realizó el modelamiento geológico superficial de datos espaciales, para esto, realizan interpolaciones con RNBR. Kentwell (2014) realizó la evaluación y comparación de curvas de ley/tonelaje en un yacimiento de oro. Este autor utiliza RNBR, datos de simulación condicional gaussiana y Kr ordinario. Jalloh et al. (2016), integra RNA y Ge por medio del algoritmo Levenberg-Marquardt para estimar las reservas de un yacimiento de Sierra Leona. Das Goswami et.al., (2017), realizó una comparación entre dos métodos de RNA y compara sus resultados en datos de una mina de hierro. Y finalmente, Jafrateh y Fathianpour (2017), utilizaron colonia artificial de abejas, para optimizar la RNA estimando leyes de un yacimiento.
Queda de manifiesto que la aplicación de RNBR en minería es amplio, sin embargo, todos los trabajos desarrollados hasta la fecha, no mencionan el problema de la cantidad de la información existente en los sondajes, es decir, no cuestionan el número de información mínima necesaria, para que las estimaciones posteriores (estimación de la ley y el tonelaje del depósito), no presenten el problema de la incertidumbre cuando se realiza el modelo de bloques.
El presente trabajo tiene como objetivo, la interpolación/reconstrucción de datos de sondajes por medio de RNBR. Se desarrollaron múltiples casos, y sus resultados son comparados con la RP y analizados con Ge.
Modelo sustituto o metamodelo (Storlie y Helton, 2008; Iooss y Lemaître, 2015)
Cuando los sistemas que se estudian son complejos y no se logra obtener relaciones claras para poder correlacionar los datos de ingreso con los datos de egreso, es posible analizarlos por medio de metamodelos, es decir, se genera un modelo sustituto que permita ajustar los datos iniciales (por ejemplo, utilizando la metodología de los mínimos cuadrados) y predecir los datos de salida con un tiempo de procesamiento aceptable. Las técnicas que se consideran dentro de este grupo, son las que se derivan de cualquier modelo de regresión lineal, no-lineal paramétrica o no paramétrica. Los metamodelos más utilizados incluyen a los polinomios, splines, modelos lineales generalizados, modelos aditivos generalizados, Kr, gaussian process metamodeling (donde algunos autores incluyen al Kr), RNA y árboles de regresión.
RP, es una de las técnicas de metamodelos más ampliamente usadas, aquí se ajusta un polinomio de orden ![]() entre los datos muestreados de entrada y salida, usando el método de mínimos cuadrados. En general, el modelo es una función de la forma (Van Gelder et al., 2014):
entre los datos muestreados de entrada y salida, usando el método de mínimos cuadrados. En general, el modelo es una función de la forma (Van Gelder et al., 2014):
![]()
Donde ![]() es la salida estimada,
es la salida estimada, ![]() es el vector de entrada,
es el vector de entrada,![]() es el orden del polinomio y
es el orden del polinomio y ![]() son los coeficientes de regresión. El polinomio de segundo orden, ha recibido gran atención por diferentes autores, especialmente para la implementación de la metodología de superficie de respuesta (Engelund et al. 1993; Venter et al. 1996). En este trabajo, sólo la RP lineal es considerada.
son los coeficientes de regresión. El polinomio de segundo orden, ha recibido gran atención por diferentes autores, especialmente para la implementación de la metodología de superficie de respuesta (Engelund et al. 1993; Venter et al. 1996). En este trabajo, sólo la RP lineal es considerada.
Redes Neuronales de Base Radial (RNBR) (Haykin 1998)
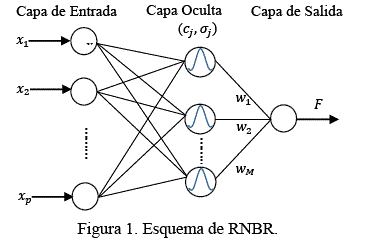
Como se menciona anteriormente, una red neuronal artificial, es un grupo interconectado de nodos que suelen constar de varias capas. En el caso de redes neuronales de funciones radiales (ver Figura 1), se tienen tres capas de neuronas: una capa de entrada, en la cual las neuronas transmiten las señales de entrada a las neuronas ocultas, una capa oculta, en la que las neuronas calculan su salida usando funciones de base radial y una capa de salida, que suministra la respuesta de la red neuronal a partir de la combinación lineal ponderada de las funciones de activación de las neuronas ocultas, ésta combinación es de la forma (Idri et al., 2010):
 (2)
(2)
Donde ![]() es el número neuronas ocultas,
es el número neuronas ocultas, ![]() es la entrada,
es la entrada, ![]() son los ponderadores (o factores de peso) y
son los ponderadores (o factores de peso) y ![]() es una función radial, es decir, es una función cuyo valor depende sólo de la distancia del vector
es una función radial, es decir, es una función cuyo valor depende sólo de la distancia del vector ![]() respecto de algún vector
respecto de algún vector ![]() , es decir,
, es decir,
![]() (3)
(3)
En la ecuación (3) la función ![]() suele ser la función gaussiana, es decir,
suele ser la función gaussiana, es decir,
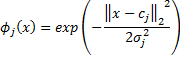 (4)
(4)
Donde ![]() y
y ![]() son el centro y ancho, respectivamente, de la jth neurona oculta.
son el centro y ancho, respectivamente, de la jth neurona oculta.
Kriging Ordinario.
Kr es una técnica de interpolación local usada en Ge, la cual ofrece el mejor estimador lineal insesgado de una característica desconocida que se estudia. Kr presupone que la distancia o la dirección entre los puntos de muestra, reflejan una correlación espacial que puede utilizarse para explicar la variación en la superficie. Existen varios tipos de Kr, en este trabajo se implementará el Kr ordinario.
El Kr ordinario está basado en la siguiente ecuación (Varouchakis et al., 2012):
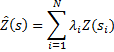 (5)
(5)
Donde ![]() ), son puntos sobre los cuales se tiene información de una determinada propiedad y
), son puntos sobre los cuales se tiene información de una determinada propiedad y ![]() es la estimación de
es la estimación de ![]() a partir de los puntos
a partir de los puntos ![]() ). Los valores
). Los valores ![]() son escogidos de forma que
son escogidos de forma que ![]() sea mínima y que el estimador sea insesgado (
sea mínima y que el estimador sea insesgado (![]() ). A partir de la última condición se tiene que:
). A partir de la última condición se tiene que:
 (6)
(6)
Este tipo de problema de minimización con restricciones, suele ser abordado con la técnica de multiplicadores de LaGrange. La aplicación de la técnica conduce a la siguiente solución:
![]() (7)
(7)
Donde ![]() ,
, ![]() ,
, ![]() es el multiplicador de Lagrange,
es el multiplicador de Lagrange, ![]() e
e ![]() , es un Vr empírico. Mientras que
, es un Vr empírico. Mientras que ![]() , es una matriz de orden
, es una matriz de orden ![]() , cuyas entradas están dadas por
, cuyas entradas están dadas por ![]() para
para ![]() ,
, ![]() para
para ![]() , mientras que,
, mientras que, ![]() . Además, bajo la condición de insesgado (
. Además, bajo la condición de insesgado (![]() ), el error de la predicción está dado por:
), el error de la predicción está dado por:
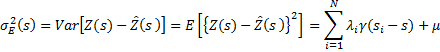 (8)
(8)
La correlación de los datos dentro de la estructura considerada está dada por el Vr empírico ![]() , el cual es obtenido aplicando el método de los momentos (Cressie, 2015):
, el cual es obtenido aplicando el método de los momentos (Cressie, 2015):
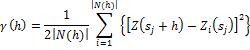 (9)
(9)
Donde,
![]()
![]() (10)
(10)
Con la inexistencia de anisotropías distintas, el Vr empírico omnidireccional puede ser estimado, y por consiguiente, será posible encontrar algún modelo paramétrico que se ajuste adecuadamente a éste. Modelos paramétricos clásicos son mostrados en la Tabla 1.

El Vr, muestra básicamente, la dependencia de los datos que se encuentran en evaluación, para esto, existen principalmente, dos opciones para su análisis. La primera opción, muestra una tendencia monótona creciente, hasta que llega a una distancia donde esta tendencia se vuelve asintótica; esta asíntota es denominada rango o alcance, y en término específico para un modelo gaussiano (tabla 2), se incluye el rango efectivo, donde ![]() es un parámetro no lineal que determina la escala espacial de la variación y el rango efectivo viene dado como:
es un parámetro no lineal que determina la escala espacial de la variación y el rango efectivo viene dado como: ![]() , que corresponde al valor 0.95c del Vr. Cuando el Vr presenta este tipo de respuesta, el sistema es definido como estacionario (presentan dependencia). La segunda opción sucede cuando el Vr no necesariamente alcanza ésta meseta, sino que tienden al infinito en función de
, que corresponde al valor 0.95c del Vr. Cuando el Vr presenta este tipo de respuesta, el sistema es definido como estacionario (presentan dependencia). La segunda opción sucede cuando el Vr no necesariamente alcanza ésta meseta, sino que tienden al infinito en función de ![]() , por lo que, son definidos como sistemas no estacionarios (no poseen dependencia). Por lo tanto, cuando los resultados del Vr muestren una tendencia estacionaria, significa que el rango determina la zona de influencia que tienen los datos en torno al punto evaluado, y fuera de esta distancia
, por lo que, son definidos como sistemas no estacionarios (no poseen dependencia). Por lo tanto, cuando los resultados del Vr muestren una tendencia estacionaria, significa que el rango determina la zona de influencia que tienen los datos en torno al punto evaluado, y fuera de esta distancia ![]() estarían los valores considerados independientes, en función al punto evaluado.
estarían los valores considerados independientes, en función al punto evaluado.
Otro elemento importante del Vr, es el conocido efecto pepita, siendo definido como la variabilidad de los datos en rangos muy pequeños de la distancia ![]() , y esto se observa como
, y esto se observa como ![]() pero
pero ![]() .
.
Algoritmo Utilizado
Los algoritmos utilizados para optimizar RNBR, consideran enfoques convencionales y metaheurísticos (Ojha et al., 2017). En el presente trabajo, se implementó un algoritmo convencional, es decir, se optimizaron los pesos de la red con herramientas matemáticas clásicas, mientras que los otros componentes, permanecieron fijos. Se propuso específicamente, topologías para la red, centros y anchos de las RNBR, mediante la técnica K-means clustering (Uykan y Guzelis, 1997). Posteriormente, se procedió a determinar los pesos de la red mediante un entrenamiento de tipo supervisado (Kaelbling et al., 1996) y el método de mínimos cuadrados (Azimi-Sadjadi y Liou, 1992). Si el error absoluto medio de proyección de la RNBR era mayor a 0.01, se modificaba la topología de la red, centros y anchos de las funciones radiales, y nuevamente se ajustaban los pesos de la red. Este procedimiento se realizó hasta obtener un error absoluto medio menor a 0.01. El algoritmo de entrenamiento fue implementado en el software Rstudio (RStudio Team, 2015). A continuación se presenta el algoritmo:
- Algoritmo usando datos reales y RNBR.
- Algoritmo usando datos reales, Kr y RNBR.
Datos experimentales y su respuesta ![]() .
.
Nuevos datos y respuesta obtenidos por Kr ordinario ![]()
Error1, incorporación de un error deseado
Determinación del número de neuronas dentro de la capa oculta M

CASOS DE ESTUDIO.
Los casos que son presentados a continuación, son las alternativas de solución de los posibles problemas que se pueden presentar en datos reales provenientes de una base de datos de sondajes.
La información de leyes de cobre es proveniente de una base de datos de una empresa minera de cobre de la Región de Antofagasta, Chile. Se desarrollan en el presente trabajo cinco casos de estudio, los primeros tres casos de estudio son desarrollados con la información del mismo sondaje, mientras que el cuarto y quinto caso de estudio se desarrollan con datos provenientes de otros dos sondajes, la información de los sondajes son el % cobre total en función de la profundidad o cotas existentes en metros sobre el nivel del mar (m.s.n.m).
Casos de estudio con tendencias espaciales.
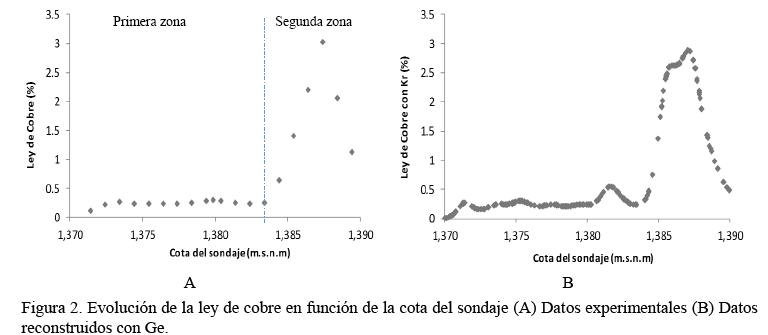
Lo primero que se necesita analizar son los datos experimentales, los cuales cuentan con 22 datos con muestreos de 1 metro (m) de distancia, la cual se pueden observar en la figura 2A, se puede apreciar que no presenta una tendencia no regular a medida que se desplaza por la cota.
La información de los datos experimentales de este sondaje para este trabajo se puede considerar escaza, por lo tanto, se realiza el proceso de reconstrucción de datos, para esto se utiliza la Ge, la cual consistió en analizar primero con los Vr y posteriormente generar nuevos datos utilizando el Kr, con estos dos pasos se generaron 600 datos nuevos datos (figura 2B) que sigue la misma tendencia espacial que los datos experimentales, y la posición espacial de estos nuevos datos fue generada aleatoriamente con el método de Monte Carlo considerando una distribución uniforme U[1,370,1,390] en m.s.n.m.
Con estas dos opciones de datos (experimental y reconstruida) se analizarán y comparan los ajustes obtenidos por medio de RP y RNBR.
Primer Caso: Evaluación con datos experimentales.
Este primer caso evalúa en los resultados obtenidos cuando se analizan los datos experimentales (figura 2A) y la interpolación del RP y la RNBR. En la figura 3A, en puntos azules se encuentran los datos experimentales en función de profundidad del sondaje, el ajuste con RP se presenta como una línea negra continua y en línea roja el ajuste por RNBR.
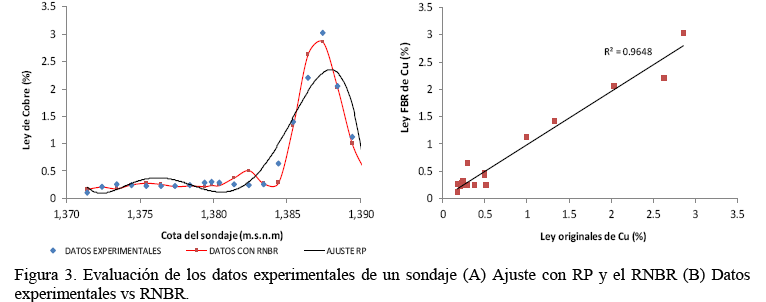
En relación al ajuste de la RP (figura 3A) se observa claramente un ajuste deficiente entre los datos experimentales y el RP, con múltiples de subestimación (1,372 m.s.n.m, 1,380 m.s.n.m y 1,386 m.s.n.m) y sobre estimación (1,376 m.s.n.m, 1,384 m.s.n.m y 1,388 m.s.n.m) de los datos, teniendo como observación, que se utilizó un polinomio de orden 5 (un orden mayor fue desestimado, pues su coeficiente de ajuste fue cero). En contraposición, la RNBR presento un mejor ajuste de la información, considerando la utilización de 6 neuronas en la capa oculta, dicho ajuste entrego un error estimado por medio de la técnica de diferencia cuadrática de 0.47, pero también presento algunos puntos de subestimación (1,384 m.s.n.m y 1,387 m.s.n.m) y sobre estimación (1,383 m.s.n.m y 1,386 m.s.n.m), pero su dispersión fue considerablemente menor (figura 3B) con respecto al ajuste generado por RP.
Segundo caso. Evaluación con datos reconstruidos.
Para este caso se considera que la cantidad de datos experimentales no generan un buen ajuste, por lo tanto, se usan datos reconstruidos (figura 2B).
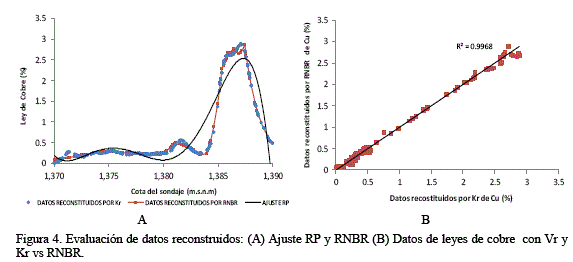
Con estos nuevos 600 datos se realizó el ajuste de los metamodelos RP y la RNBR, los resultados son mostrados en la Figura 4A. Aquí se puede apreciar que nuevamente RP presenta un ajuste deficiente, generando zonas de sub-estimación y sobreestimaciones notorias y considerando que se utilizó un RP con un orden 6, mientras que RNBR presenta un mejor ajuste que el RP a los datos reconstruidos (se consideraron 15 neuronas en la capa oculta). Además, la dispersión de los datos fue mucho menor (figura 4B) obteniéndose un error calculado por diferencia cuadrática de 1.75. Un aspecto interesante de comentar es que el aumento del número de datos y neuronas no produjo un aumento significativo del tiempo de cálculo computacional.
Tercer caso. Análisis Vr entre datos originales y datos reconstruidos.
En el siguiente caso se analizará la tendencia espacial de los datos, entre los datos experimentales, datos reconstruidos por la Ge (uso del Vr y Kr) y el ajuste obtenido RNBR cuando se utilizaron 22 datos (figura 3) y 600 datos (figura 4).
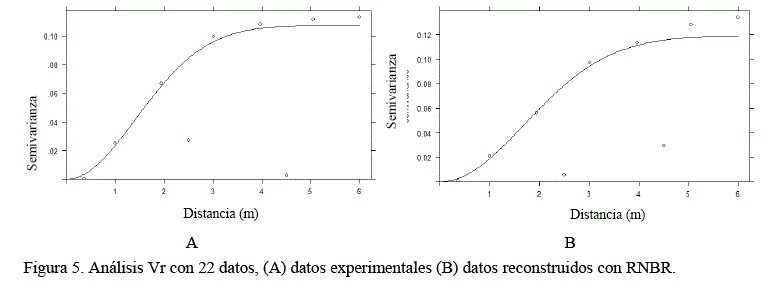
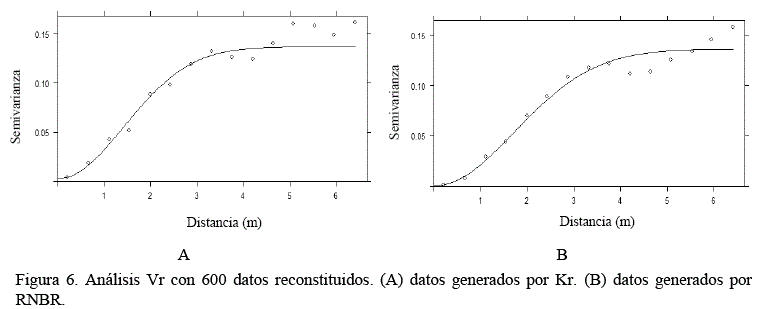
En las figuras 5 y 6 se muestran los distintos Vr. En todos los casos el modelo gaussiano fue el que presentó mejor ajuste, y en general no existe una diferencia significativa con respecto a los datos experimentales. Los ajustes indican que no hay presencia del efecto pepita y que la meseta en el caso de los datos experimentales y reconstruidos con RNBR se alcanzan a 0.107 y 0.119 con un rango efectivo de 3.486 y 4.162 m, respectivamente, es decir, a partir de estas distancias las muestras son espacialmente independientes unas de otras. En el caso de los 600 datos reconstruidos y 600 proyectados con RNBR se alcanza las mesetas de 0.134 y 0.135 a partir de un rango efectivo de 3.491 y 4.238 m, respectivamente.
Este análisis confirma en forma numérica el trabajo de Fazio y Roisenberg (2013) sobre la compatibilización matemática del Kr y la RNBR, la cual logra mantener la tendencia espacial de los datos experimentales, esto es muy relevante, ya que posteriormente en los cálculos Ge en superficies y volumen, es muy dependiente del punto de origen de su estimación.
Casos de estudio sin tendencias espaciales.
Estos casos se desarrollan con datos de sondajes cuyos datos no presentan una tendencia espacial definida (Figura 7), es decir, no es posible utilizar la Ge para realizar un análisis de sus datos (relación de la solubilidad).
Cuarto caso. Evaluación con datos originales sin tendencia espacial.
En este caso se considera la información de un sondaje cuyos datos no presentan una tendencia espacial definida (ver Figura 7), es decir, los modelos mostrados en la Tabla 1 presentan un mal ajuste al Vr experimental, por consiguiente, los datos que se pueden reconstruir con el Kr no se ajustarían espacialmente a sus datos.
La Figura 8A muestra el resultado obtenido al ajustar RP y RNBR a los datos del sondaje, aquí se puede apreciar que RP no presenta un buen ajuste. Por otro lado, el ajuste que alcanza la RNBR es mucho mejor que el RP, logrando seguir la tendencia no regular que presentan los datos experimentales. Esto se puede apreciar de mejor manera en la Figura 8B, aquí de forma similar al caso 3 se obtiene una alta correlación con una baja dispersión de los datos y un error de mínimos cuadrádos de 0.002.
Quinto caso. Incompatibilidad de la información con la geoestadística.
En este caso se considera la incompatibilidad matemática de los datos con respecto al uso de la Ge. Y esto se presenta en la relación de la solubilidad del cobre, la que es definida por: ![]() , bajo la restricción general
, bajo la restricción general ![]() . De acuerdo con Pizarro (2011. 13), la restricción anterior hace que la Ge sea no aplicable en este caso, pues los métodos Kr no consideran la incorporación de desigualdades.
. De acuerdo con Pizarro (2011. 13), la restricción anterior hace que la Ge sea no aplicable en este caso, pues los métodos Kr no consideran la incorporación de desigualdades.
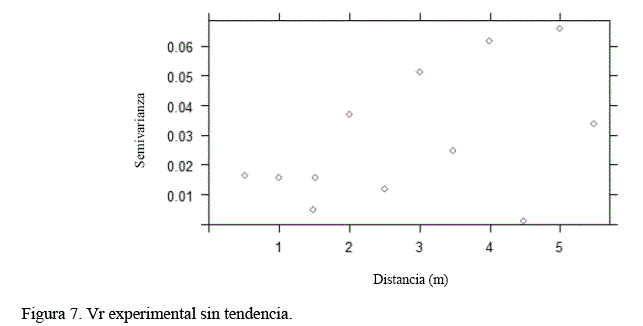
Nuevamente los resultados muestran que RNBR logra un ajuste de alta calidad independiente de las altas fluctuaciones que posee la solubilidad del cobre (Figura 8A), en comparación con los magros resultados obtenidos con RP. En la figura 8B se muestra como la proyección del cobre soluble obtenida con RNBR, la cual nunca supera la tendencia del cobre total dentro del rango de interpolación (1,360 m.s.n.m hasta 1,378 m.s.n.m.), se tiene que comentar que entre las cotas 1,360 m.s.n.m hasta 1,365 m.s.n.m y posteriormente desde 1,378 m.s.n.m hasta 1,381 m.s.n.m., no existían datos de cobre soluble, lo que hacía imposible calcular la solubilidad, y es por esa razón el cambio del rango de cotas en el eje x entre la figura 9A y la figura 9B, por lo tanto, al no existir información se le puede definir como una extrapolación de los datos de la solubilidad, y sus resultados mantienen la tendencia mostrada en la zona de interpolación, es decir, el cobre soluble es siempre menor al cobre total.
Conclusión y discusión
En este trabajo se propuso reducir la incertidumbre de los cálculos geoestadisticos, cuando no existen datos suficientes provenientes de los sondajes, esto es debido a información incompleta o sesgada (cantidad y calidad de datos experimentales) en la construcción de la base de datos. Este análisis puede principalmente útil en empresas, instituciones o personas naturales que no tengan recursos económicos o técnicos suficientes, para generar una base de datos adecuada, entregándose solución matemática sencilla (ya que su base es la interpolación) y sin un costo económico ni técnico excesivos (debido a que el requerimiento computacional es bajo y el programa utilizado para su análisis es gratuito), todo en base a la utilización de la RNBR.
Se consideraron 5 casos de estudio, en los cuales los resultados obtenidos con RNBR fueron comparados con RP en función de la calidad del ajuste. En todos los casos RNBR presentó mejores resultados que RP, esto se debe a que los polinomios no presentan un buen ajuste a datos que presentan gran variación o comportamientos complejos.
Entre los casos analizados resalta el segundo caso, en éste inicialmente se reconstruyeron 600 datos con Vr y Kr y posteriormente se ajustaron los metamodelos RNBR y RP. En el caso de RNBR el error de ajuste fue bajo. Además, los datos reconstruidos con RNBR presentan tendencias espaciales similares a los datos originales (tercer caso).
La compatibilidad de RNBR con la Ge hace que podamos obtener una expresión matemática (Kr sólo reconstruye datos) para proyectar la ley a distintas cotas del terreno, la cual preservar la tendencia espacial de los datos. Esta expresión matemática presenta la posibilidad de almacenar grandes cantidades de información, pues un sondaje puede contener entre 20 o 30 filas de datos. Además, considerando que en la práctica los datos de sondajes son complementados para obtener o actualizar modelos geológicos o geo-metalúrgicos, se tiene que la expresión matemática puede ser de gran ayuda. En efecto, la gran cantidad de datos puede ser remplazada por sólo la información necesaria (centros, desviaciones estándar y factores de ponderación) para definir el modelo matemático, reduciendo así de manera significativa la memoria informática necesaria para almacenar tal cantidad de información (Tabla 3).

La versatilidad de RNBR queda de manifiesto en el cuarto caso. La no existencia de una tendencia espacial de los datos no representa un problema para RNBR, además el tiempo de procesamiento de los datos son bajos cuando se evalúa en 1D. Sin embargo, en los casos que no se reconstruían previamente datos con Vr y Kr se tuvo que considerar un gran número de neuronas en la capa oculta (teniendo en cuenta el número bajo de datos) para obtener buenos ajustes. Este gran número de neuronas es matemáticamente y computacionalmente ineficiente, pues las neuronas en la capa oculta estában traslapadas, esto explica por qué el ajuste obtenido con RNBR en los casos 1, 4 y 5 no mejoraron de forma marcada al considerar más neuronas en la capa oculta.
El proceso de reconstruccion de datos debe ser complementado con información geológica, pues esta recostrucción considera que la mineralizacion se encuentra completamente diseminada en la unidad litologica evaluada y es visualizada en el sondaje, y desde ese punto de vista, se le considera como una función continua, pero posibles cambios litologicos podrían generar discontinuidades en la información, generando zonas con datos inexistentes.
Finalmente, la metodología de reconstrucción de datos de sondajes propuesta en este trabajo se utiliza el software estadístico Rstudio. Este software es descargable gratuitamente desde www.rstudio.com y presenta una interfaz amigable para el usuario, por lo que crear una plataforma compatible con softwares de planificación minera, pero el algoritmo podría ser programables con otros softwares matemáticos o estadísticos.
Referencias.
1. Akbar, Daya. Reserve estimation of central part of Choghart north anomaly iron ore deposit through ordinary kriging method. International Journal of Mining Science and Technology, 22 (2012), 573-577. [ Links ]
2. Arora, Geeta y Bhatia, Gurpreet. Radial basis function methods solve partial differential equations arising in financial applications-A review. Nonlinear Studies, 24 (2017): 15-25. [ Links ]
3. Azimi-Sadjadi, Mahmood y Liou, Ren-Jean. Fast learning process of multilayer neural networks using recursive least squares method. IEEE Trans. Signal Process, 40 (1992): 446-450. [ Links ]
4. Chatterjee, S. Bhattacherjee, A. Samanta, B. Pal, S.K. Ore grade estimation of a limestone deposit in India using an artificial neural network. Applied Gis, 2 (2006): 2.1-2.20. [ Links ]
5. Chatterjee. Snehamoy. Bandopadhyay, Sukumar. Machuca, David. Ore grade prediction using a genetic algorithm and clustering based ensemble neural network model. Mathematical Geosciences, 42 (2010), 309-326. [ Links ]
6. Cressie, N.A.C. Statistics for spatial data. John Wiley & Sons, Revised Edition. 2015. [ Links ]
7. Das Goswani, A. Mishra, M.K. y Patra, D. Investigation of general regression neural network architecture for grade estimation of an Indian iron ore deposit. Arab J Geosci. (2017): 10-80. [ Links ]
8. De la Huerta, F. 1994. Aplicación del criterio de costo de oportunidad en la planificación de producción de minas subterráneas. Tesis. Universidad de Chile, Chile, 2013. [ Links ]
9. Drymonitis, Dimitris. Some Mineral exploration problems that can be solved by mathematics and geostatistics. Procedia Earth and Planetary Science, 15 (2015): 747-753. [ Links ]
10. Dubrule, O. y Kostov, C. An interpolation method taking account inequality constraints: I Methodology. Mathematical Geology. 18 (1986): 33–51. [ Links ]
11. Emery, Xavier. Co-simulating total and soluble copper grades in an oxide ore deposit. Mathematical Geosciences. 44 (2012): 27-46. [ Links ]
12. Engelund, Walter. Stankey, Douglas O. Lepsch, Roger. McMillian, Mark. y Unal, Resit. Aerodynamic configuration design using response surface methodology analysis. AIAA Aircraft Design, Sys. E. Oper. Mngmt. (Monterey, CA).( 1993): 12.. [ Links ]
13. Fazio, Vinicius. y Roisenberg, Mauro. Spatial interpolation: an analytical comparison between kriging and RBF networks. Proceeding SAC '13 Proceedings of the 28th Annual ACM Symposium on Applied Computing. Marzo (2013): 2-7. [ Links ]
14. Haykin, S. Neural Network: A Comprehensive Foundation. 2nd edition. Prentice-Hall, 1998. [ Links ]
15. Hilera, Jose y Martínez, Hernando. Redes neuronales artificiales. Fundamentos, modelos y aplicaciones. Addison-Wesley Iberoamericana, 1995. [ Links ]
16. Hillier, Michael.J. Schetselaar, Ernst.M. Kemp, Eric.A. y Perron, Gervais. Three-dimensional modelling of geological surfaces using generalized interpolation with radial basis functions. Mathematical Geosciences, 46 (2014): 931-953. [ Links ]
17. Hornik, Kurk. Approximation capabilities of muktipayer feedforward networks. Neural Networks, 4 (1991): 251-257. [ Links ]
18. Idri, Ali. Zakrani, Abdelali. y Zahi, Azeddine. Design of radial basis neural networks for software effort estimation. International Journal of Computer Science Issus, 7 (2010): 11-17. [ Links ]
19. Iooss, Bertrand. y Lemaître, Paul. A review on global sensitivity analysis method. Uncertainty Management in Simulation-Optimization of Complex Systems. Algorithms and Applications. Springer, (2015): 101. [ Links ]
20. Jin, Ruichen. Chen, Wei. y Simpson, Timothy W. Comparative studies of metamodeling techniques under multiple modelling criteria. Struct Meultidisc Optim, 23 (2001): 1-23. [ Links ]
21. Kaelbling, Leslie Pack. Littman, Michael L. y Moore, Andrew W. Reinforcement learning: A survey. J. Artif. Intell. Res. 4 (1996): 237-285. [ Links ]
22. Kapageridis, Ioannis K. Artificial neural network technology in mining and environmental applications. Mine Planning and Equipment Selection, Prague (2002), [ Links ]
23. Kapageridis, Ioannis. y Denby, Bryan. Schofield. GEMMet II - An alternative method for grade estimation. Mine Planning and Equipment Selection, Athens, Greece, (2000): 209-216. [ Links ]
24. Kapageridis, Ioannis K. y Triantafyllou, A.G. LavaNet - Neural network development environment in a general mine planning package. Computers & Geosciences, 37 (2011): 634-644. [ Links ]
25. Kapageridis, Ioannis. y Denby, Bryan. Neural Network Modelling of ore grade spatial variability. Proceedings of the International Conference for Artificial Neural Networks, Skovde, Sweeden, (1998): 209-214. [ Links ]
26. Kentwell, D. Radial basis functions and kriging - a gold case study. Australasian Institute of Mining and Metallurgy Bulletin, 6 (2014): 54-56. [ Links ]
27. Krige, D.G. A statistical approach to some basic mine valuation problems on the Witwatersrand. Journal of the Chemical, Metallurgical and Mining Society of South Africa, 52 (1951): 119-139. [ Links ]
28. Lee, Sukhan. y Kil, Rhee M. A Gaussian potential function network with hierarchically self-organizing. Neural Network, 4 (1991): 207-224. [ Links ]
29. Li, Jin. y Heap, Andew. A review of comparative studies of spatial interpolation methods in environmental sciences: performance and impact factors. Ecological Informatics, 6(2011): 228-241. [ Links ]
30. Li, Jin. y Heap, Andrew D. Spatial interpolation method applied in the environmental sciences: A review. Environmental Modelling & Software, 53 (2014): 173-189. [ Links ]
31. Lin, Gwo-Fong. y Chen, Lu-Hsien. A spatial interpolation method based on radial basis function networks incorporating a semivariogram model, Journal of Hydrology, 288 (2004): 288-298. [ Links ]
32. Mahmoudabadi, Hamid. Izadi, Mohammad. y Begher, Mohammead. A hybrid method for grade estimation using genetic algorithm and neural networks. Compu. Geosci., 13 (2009): 91 – 101. [ Links ]
33. Matías, J.M. Vaamonde, A. Taboada, J. Gonzales-Manteiga, W. Comparison of kriging and neural networks with application to the exploitation of a slate Mine. Mathematical Geology, 36 (2004): 463-486. [ Links ]
34. McCulloch, Warren S. y Pitts, Walter. Bulletin Mathematical Biophysics, 5 (1943): 115-133. [ Links ]
35. Melo, C.E.. Análisis geoestadístico espacio tiempo basado en distancias y splines con aplicaciones. Tesis, Universidad de Barcelona. 2012. [ Links ]
36. Moody, John. y Darken, Christian J. Fast learning in network of locally-tuned processing units. Neural Computation, 1(1989): 281-294. [ Links ]
37. Nakama, Takéhiko. Theoretical analysis of batch and on-line training for gradient descent learning in neural networks. Neurocomputing, 73 (2009): 151–159. [ Links ]
38. Ojha, Varun K. Abraham, Ajith. Snásel, Václav. Metaheurisic design of feedforward neural networks: A review of two decades of research. Engineering Applications of Artificial Intelligence, 60 (2017): 97-116. [ Links ]
39. Park, J. y Sandberg, I.W. Universal approximation using radial-basis–function networks. Computacional Neuron, 3 (1991): 246-257. [ Links ]
40. Pizarro, Sebastian H. Modelamiento geoestadistico de leyes de cobre total y soluble. Tesis. Universidad de Chile, 2011. [ Links ]
41. Powell M.J.D. Radial basis functions for multivariable interpolation: review. In: Mason, J.C.: Cox, M.G. (eds.) Algorithms for approximation. Oxford University Press, 1987. [ Links ]
42. RStudio Team. 2015. RStudio: Integrated Development for R. RStudio, Inc., Boston, MA URL http://www.rstudio.com/. [ Links ]
43. Rumelhart, David E. Zipser, David. Feature Discovery by competitive learning. Cognitive Science, 9 (1985): 75-112. [ Links ]
44. Rumelhart, David E. Hinton, Geoffrey E. y Williams, Ronald J. Learning representations by back-propagation errors. Nature, 323 (1986): 533-536. [ Links ]
45. Saad, David. On-line Learning in Neural Networks 17. Cambridge, Cambridge University Press, 2009.. [ Links ]
46. Samanta, B. y Bandopadhyay, S. Construction of a radial basis function network using an evolutionary algorithm for grade estimation in a placer gold deposit. Computers & Geosciences, 35 (2009): 1592-1602. [ Links ]
47. Sichel, H.S. An experimental and theoretical investigation of bias error in mine sampling with special reference to narrow gold reefs. Tran. Inst. Min. Metall. Lond., 56 (1947): 403-473. [ Links ]
48. Storlie, Curtis B. y Helton, Jon C. Multiple predictor smoothing method for sensitivity analysis: description of techniques. Reliability Engineering & System Safety, 93 (2008): 28-54. [ Links ]
49. Tu, C.H. y Barton, R.R. Producting yield estimation by the metamodel method with a boundary-focused experiment design. Design Theory and Methodology Conf. - DTM97, DETC97/DTM3870. (1997). [ Links ]
50. Uykan, Z. y Guzelis, G. Input-output clustering for determining the centers of radial basis function networks. In: Proceedings of the ECCTD-97, Budapest, Hungary, (1997): 435-439. [ Links ]
51. Van Gelder, Liesje. Das, Payel. Janssen, Hans. y Roels, Staf. Comparative study of metamodelling techniques in building energy simulation: Guidelines for practitioners. Simulation Modelling Practice and Theory, 49 (2014): 245-257. [ Links ]
52. Varouchakis, E.A. Hristopulos, D.T. y Karatzas G.P. Improving kriging of groundwater level data using nonlinear normalizing trasformations – a field application. Hydrological Sciences Journal, 57 (2012): 1404 – 1419. [ Links ]
53. Venter, Gerhard. Haftka, Gainesville R. y Starnes, James H. Construction of response surfaces for design optimization applications. Proc. 6th AIAA/USAF/NASA/ISSMO Symp. On Multidisciplinary Analysis and Optimization (held in Las Bellevue, WA), 1 (1996): 548-564. [ Links ]
54. Werbos, Paul J. Beyond regression new tool for prediction and analysis in the behavior science, thesis, Harvard University, 1975. [ Links ]
55. Yamamoto, Jorge K. Ore reserve estimation using radial basis functions. Revista do Instituto Geológico, 23 (2002): 25-38. [ Links ]
56. Yao, Xin. A review of evolutionary artificial neural networks. International Journal of Intelligent System, 8 (1993): 539-567. [ Links ]
57. Zamora, C. F. Estudio comparativo entre kriging y cokriging aplicada s una base de datos reconstituidas en base a las solubilidades locales. Tesis. Universidad de Antofagasta, 2013. [ Links ]
58. Zhao, Zhong-Qiu. y Huang, De-Shuang. A mended hybrid learning algorithm for radial basis function neural networks to improve generalization capability. Applied Mathematical Modelling, 31 (2007): 1271-1281. [ Links ]
59. Zou, You-Long. Hu, Fa-Long. Zhou, Can-Can. Y otros. Analysis of radial basis function interpolation approach. Applied Geophysics, 10 (2013): 397-410. [ Links ]