










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkEducación Superior
versión impresa ISSN 2518-8283
Edu. Sup. Rev. Cient. Cepies vol.8 no.2 La Paz set. 2021
ARTÍCULOS CIENTÍFICOS
Modelo de aplicación orientada a la web 4.0 en el rendimiento
académico del estudiante en educación superior
Web 4.0-oriented application model for student academic
performance in higher education
Mendoza Jurado, Helmer Fellman
Docente de la Carrera de Sistemas Universidad Privada Domingo Savio – Sede
Tarija tj.helmer.mendoza.j@upds.net.bo Tarija, Bolivia
Fecha de Recepción: 12 de agosto de 2021 Fecha de Aprobación: 9 de septiembre de 2021 en reunión de Comité Editorial
Resumen
El presente artículo tiene el objetivo de proponer un modelo de Machine Learning (Aprendizaje Automático) con base a la Web 4.0, la cual subyace en una relación intrínseca entre un modelo de Reglas de Asociación y un modelo de árbol de decisión que busca generar un resultado predictivo para la alerta temprana en el rendimiento académico del estudiante en educación superior, siendo reflejado por inercia en las calificaciones que cuantifican al aprendizaje en distintas asignaturas que son objeto de estudio, principalmente desde la potencialidad que trae el algoritmo Apriori, que logra una baja eficiencia de recorrido frecuente de conjuntos y elementos, buscando relaciones causales de elementos frecuentes basadas en reglas de asociación y árboles de decisión. Sin embargo, existen claras dependencias entre asignaturas, niveles, el entorno social y cultural del estudiante. Asimismo, establecer que la principal motivación del proceso de investigación busca generar un modelo que proporcione una orientación académica precisa, que pueda mejorar de manera efectiva la calidad en la gestión del aprendizaje de las personas, siendo esto de gran importancia para el rendimiento académico del estudiante. Además, que pretende coadyuvar en la experiencia educativa a nivel superior, siendo que, en la actualidad, la tecnología proporciona una inmejorable oportunidad de buscar un sistema educativo más efectivo y moderno, incluso en comparación con otros algoritmos de Inteligencia Artificial, que caracteriza a la Web 4.0.
Palabras Clave: Web 4.0, Rendimiento Académico, Reglas de Asociación y Arboles de Decisión.
Abstract
The objective of this paper is to propose an application model based on Web 4. 0 (Intelligent Web), which underlies an intrinsic relationship between an artificial intelligence model based on association rules and a decision tree algorithm that structures a predictive model for early warning in the pedagogical development of the student, which is reflected in the grades that quantify the degree of learning in different subjects, mainly from the potential of the Apriori algorithm that achieves a low efficiency of frequent paths of sets of elements, this model uses mainly the FP- growth model to search frequent sets of elements by means of association rules and decision trees. However, there are clear dependencies between subjects, levels, social and cultural environment, leading to a rational analysis and early warning of the learning process of each subject, like with the evaluated student. The proposed model provides a precise academic orientation, which can effectively improve the quality in the management of people’s learning, being of great importance for the development and orientation of the students themselves. Besides that, it aims to help understand the situation of students in all aspects and improve the overall level of students, being more effective compared to other machine learning algorithms (Machine Learning), which characterize the Web 4.0.
Keywords: Web 4.0, Academic Performance, Association Rules and Decision Trees.
1. Introducción
En la actualidad existe una gran variedad de investigaciones que indagan la correlación de factores significativos en el rendimiento académico del estudiante, entre los cuales se incluyen (Alpaydin, 2020; Wang, 2011; Ying y Lv, 2011), que establece una visión transversal direccionada en las diferencias de género, entorno de aprendizaje y estado familiar, pero es necesario puntualizar que existe una escasez de estudios que indaguen en la correlación que puede llegar a existir entre cursos de diferentes semestres.
Como antecedente Vijayalakshmi y Venkatachalapathy (2019) establecen principalmente que la tecnología implícita en los modelos de regresión doble o árbol de decisión, algoritmos genéticos, redes neuronales artificiales, fundamentalmente tienen el objetivo de encontrar distintos factores externos relacionados con el rendimiento académico de los estudiantes, pero estos factores solo afectan el rango flotante en el rendimiento hasta cierto punto, en lugar de determinar un logro específico. Ahora bien, los métodos de minería de datos que desarrollan un análisis bidireccional relacionado con el rango de Kendall (Azad-Manjiri, 2014) y las referencias (Jun-yu, 2014; Koenker y Hallock, 2001; Yongguo, 2012; Zhang y Lou, 2021), que principalmente buscan descubrir reglas de asociación o patrones ocultos relacionados con una asignatura en específico. Si bien estos métodos son favorables para optimizar la estructura curricular y mejorar la calidad en la enseñanza, el alcance del análisis curricular tiene grandes limitaciones, la mayoría de ellos se basan en el diseño de conceptos educativos, lo cual infiere por inercia en información útil direccionada al modelo predictivo de la Web 4.0, estableciendo las reglas de asociación curricular y los problemas de enseñanza reflejados en el plan de estudios, pero que no se exploran completamente. En otras palabras, no se puede proporcionar a los estudiantes una orientación específica y efectos de alerta temprana, ni tampoco se puede proporcionar sugerencias y una correcta toma de decisiones para el desarrollo de la enseñanza de las universidades. En consecuencia, es muy importante construir un modelo que brinde una alerta temprana de acuerdo al desempeño pertinente y que busque proporcionar una guía de aprendizaje eficaz para los estudiantes.
La educación superior contemporánea, ha provocado una rápida expansión en la escala curricular, lo cual subyace en una creciente escasez de recursos didácticos, lo que dificulta la enseñanza en los estudiantes de acuerdo a condiciones individuales. Así por ejemplo la facultad de Ingeniería de la Universidad Privada Domingo Savio, con sede en la ciudad de Tarija, establece las asignaturas a nivel de pregrado como “Sistemas Digitales”, “Estructuras de datos” y “Cálculo”, las cuales tienen como antecedentes niveles de seguimiento, que forman así una estructura de árbol compleja.
Cada uno de estos niveles tiene un cierto grado de dificultad y requieren mucho tiempo y energía desde el proceso de enseñanza y aprendizaje, lo que aumenta la carga cognitiva en los estudiantes.
En consecuencia, el presente trabajo de investigación pretende como principal objetivo proponer un modelo que pueda alertar de manera temprana y objetiva, de acuerdo al desempeño en el aprendizaje del estudiante y, por lo tanto, se busca complementar de manera eficiente al trabajo docente, y las condiciones individuales del estudiante en su proceso de enseñanza y aprendizaje. Además, se busca que los estudiantes puedan mejorar su rendimiento académico de acuerdo a materias relacionadas y obtener una mejora significativa en su aprovechamiento. Es decir, que se propone un método para combinar reglas de asociación, con un modelo de árbol de decisión para establecer una alerta temprana enfocada al rendimiento en el aprendizaje.
2. Materiales y Métodos
El proceso de investigación fue desarrollado desde un enfoque cuantitativo, fundamentalmente desde la gestión de recursos educativos virtuales basados en la plataforma Moodle, que intuitivamente se integra al modelo de predicción propuesto, esto debido a que Moodle al ser una herramienta adaptada para funcionar en la Web 4.0 o Web inteligente, permite una inclusión directa de cualquier modelo de inteligencia artificial en los datos, recursos y calificaciones que fueron trabajadas en la plataforma, siendo fundamentado por un paradigma positivista, así mismo el proceso de investigación subyace desde un tipo de investigación observacional y descriptivo, puesto que se pretende observar, y extraer información de manera independiente o principalmente relacionada en la implementación de modelos de Machine Learning (Reglas de Asociación y Arboles de decisión) propios de la Web 4.0.
Data de muestra
Los datos se derivan de más de 400 registros de estudiantes de pregrado (Ciclo Básico y Motivacional y Ciclo de Profesionalización) de la facultad de Ingeniería en la Universidad Privada Domingo Savio, estableciendo un conjunto de datos inicial que comprende las asignaturas de: Álgebra lineal, Técnicas de Investigación, Programación Básica, Inteligencia Artificial, Sistemas Digitales, por consiguiente se establece un muestreo probabilístico estratificado, donde se optó por clasificar a los estudiantes de acuerdo a cinco asignaturas de esta población, los detalles por asignatura se muestran en la Tabla 1.
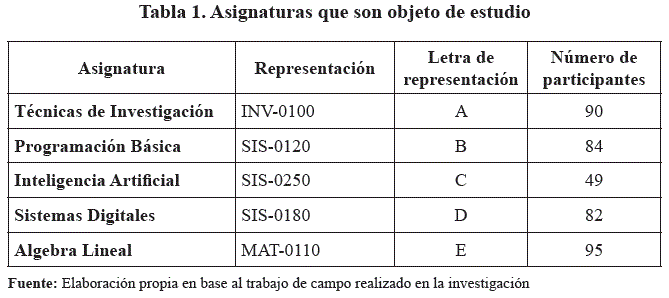
De acuerdo con el análisis de demanda del algoritmo de reglas de asociación y el algoritmo de árbol de decisión, establece el rendimiento en el estudiante que se divide en cinco grados o niveles, como se muestra en la Tabla 2.

Método de reglas de asociación, y árbol de decisiones
Reglas de asociación (Apriori)
Las reglas de asociación describen la relación potencial que existe entre elementos de datos en un conjunto, estableciendo principalmente una división en asociaciones simples, asociaciones de series de tiempo y asociaciones causales, que infiere un método de minería de datos significativo, que se divide en dos etapas:
1. Inicialmente todos los conjuntos de elementos frecuentes del conjunto de datos, siendo que, en primer lugar, se recopila el grado de apoyo del proyecto de investigación X y Y. Deje que count (X U Y) represente el número de conjuntos y elementos que contienen tanto X como Y en la base de datos D, luego el grado de soporte del conjunto de elementos X → Y es:
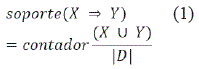
Luego se establece el grado de soporte mínimo (Supmin), que representa la menor importancia de las reglas de asociación que interesan a los usuarios. Si soporta (X) Y) Supmin, entonces x es un conjunto frecuente.
2. Se establecen conjuntos de elementos frecuentes para generar reglas de asociación y filtre, las reglas de asociación sólidas según los umbrales preestablecidos. La confianza se define en:
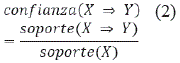
La confianza mínima es (Confmin), infiere que las reglas de asociación más fuertes definen el apoyo y la credibilidad de conjuntos frecuentes que son menos que Supmin y Confmin.
3. El algoritmo de Apriori. Los algoritmos clásicos de minería de reglas de asociación incluyen AIS, AETM, Apriori (Mark et al., 2016), Eclat y Partitio. El algoritmo Apriori de uso común es el núcleo de dichos algoritmos. El algoritmo utiliza el conocimiento previo de la naturaleza de los conjuntos de elementos frecuentes para encontrar iterativamente todos los conjuntos frecuentes de orden superior de abajo hacia arriba, y solo considera todos los conjuntos de elementos con la misma longitud k en el k-ésimo escaneo.
En el primer escaneo, se calcula primero el soporte de todos los elementos y se genera un conjunto de elementos frecuentes de longitud 1, exploraciones posteriores, los conjuntos de elementos triviales de longitud k obtenidos en la exploración anterior se utilizan como base, y el superconjunto de cada elemento frecuente, siendo un conjunto candidato, se genera un nuevo elemento frecuente de longitud k + 1. El análisis se repite hasta que no se encuentran nuevos conjuntos de elementos frecuentes.
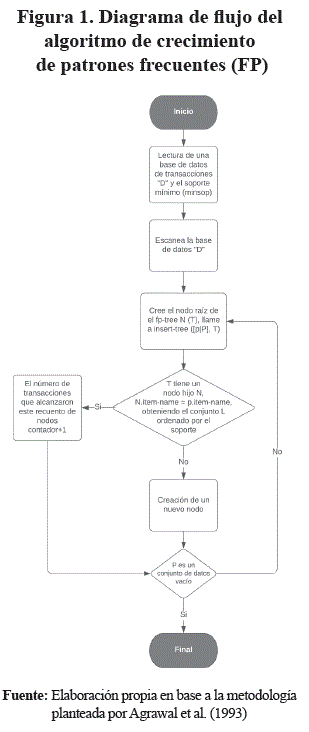
4. El algoritmo de crecimiento de patrones frecuentes (Agrawal et al., 1993) utiliza un árbol de patrones frecuentes (FP) como estructura de datos para almacenar conjuntos de elementos frecuentes, es decir, un árbol de prefijos, donde las ramas del árbol representan cada elemento, los nodos almacenan elementos de sufijo y rutas representan conjuntos de elementos a fin de que se permita ordenar conjuntos de elementos frecuentes de acuerdo con su soporte, lo que es la clave del algoritmo de crecimiento FP. En comparación con el algoritmo Apriori, el algoritmo de crecimiento de FP no genera un conjunto de candidatos y solo necesita atravesar la base de datos dos veces, mejorando así la eficiencia. En el árbol FP generado, los elementos con un alto soporte se clasifican en primer lugar, lo que hace que los conjuntos de elementos frecuentes sean más fáciles de compartir, reduciendo efectivamente el espacio requerido para la operación del algoritmo. Se construye una base de datos de proyección condicional y un árbol FP de proyección para cada conjunto de elementos frecuentes. Al mismo tiempo, este proceso se repite para cada árbol FP recién construido, sabiendo que el árbol FP construido está vacío o contiene solo una ruta. Cuando el árbol FP está vacío, su prefijo es un patrón frecuente; cuando contiene solo una ruta, todas las combinaciones posibles se enumeran y combinan para conectarse con el prefijo de este árbol y así obtener un patrón frecuente. La división espacial mutuamente excluyente de estos patrones frecuentes, produce subconjuntos independientes, que a su vez forman información completa. FP Proceso de ejecución del algoritmo de crecimiento es mostrado en la Figura 1.
Árbol de Decisión
El algoritmo de árbol de decisión (Houtsma y Swami, 1993) es un algoritmo de clasificación clásico. Primero procesa los datos originales y generaliza para generar reglas legibles, siendo que esta regla generalmente se refleja en la estructura de árbol, la cual se denomina cómo árbol de decisión. Cuando es necesario clasificar nuevos datos, solo se necesita el árbol de decisiones para analizar los nuevos datos y obtener los resultados de la clasificación. Este método se ha utilizado ampliamente en algoritmos de minería de Big Data.
Un árbol de decisión es un árbol acíclico dirigido. Cada nodo hoja del árbol corresponde a un atributo en el conjunto de muestra de entrenamiento. Una rama en cada nodo corresponde a una división numérica del atributo. Cada nodo hoja representa una clase, desde el nodo raíz hasta la hoja. La ruta de un nodo se llama regla de clasificación. La construcción del árbol de decisiones se mide principalmente mediante la selección de atributos correspondientes. En la actualidad, existen principalmente métodos de medición de atributos: ganancia de información, tasa de ganancia de información e índice de ganancia.
1. Entropía de la información: Establece un concepto importante en la física y las ruedas de información, que se utiliza para medir el grado de desorden de una distribución de datos. Para una muestra de entrenamiento, cuanto menor es su entropía, menor es el desorden de la muestra de entrenamiento, es decir, es más probable que las muestras de entrenamiento pertenezcan a la misma clase.
La ganancia de información es un método para medir la entropía de la información de la muestra. La probabilidad de que una muestra del conjunto de datos D, que subyace en la k-ésima muestra es la proporción pk (k =1,2,3, ,|y|) del número de k-ésimo muestras al número total de muestras. La entropía de información de D se define como:
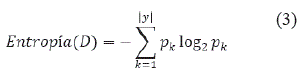
2. Algoritmo C4.5: Propone mejorar la capacidad de generalización de los árboles de decisión, que utiliza la tasa de ganancia de información para la selección de características. Entre ellos, la tasa de ganancia se define como:
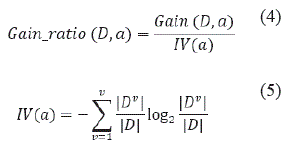
Entre ellos, IV(α) se llama el valor propio del atributo a. Cuando el número de valores potenciales del atributo a es mayor, el valor propio del atributo a es mayor. En la implementación del algoritmo específico, los atributos con una tasa de ganancia de información más alta que el nivel promedio se encuentran primero a partir de los atributos de partición candidatos, y luego se selecciona el atributo con la tasa de ganancia más alta como base de clasificación de datos final.
3. Resultados
Los principales hallazgos establecidos por el presente trabajo de investigación se presentan a través del modelo propuesto que tiene como arquitectura de un árbol de decisiones (Figura 2), de ahí que se establecen dos aspectos en el árbol de decisiones: el que tiene más probabilidades de fallar (¡Quizás-Fallar!), y el de no fallar (Éxito). Asimismo, se desarrollan las reglas de asociación de acuerdo al modelo Apriori desglosa los resultados generados por el árbol de decisiones, integrando una relación horizontal y vertical entre cada asignatura y el curso reprobado para advertir de manera temprana a los estudiantes. En los resultados finales, el primer atributo indica que se trata de la asignatura más importante que debe prestar más atención el estudiantado y que es parte del objeto de estudio.

Se trazan cinco líneas desde el conjunto de datos, que representan los cinco niveles de rendimiento de los estudiantes que asisten al examen de las asignaturas evaluadas, las cuales se dividen en diferentes puntajes y en diferentes niveles: 60, 60-70, 70-80, 80-90, 90–100. Por ejemplo, la primera línea, D-Risk, significa que se está por debajo de 60. Una vez conocido el puntaje de alguna asignatura de mayor impacto en el resultado final (¡Quizás-Fracasar! O Éxito).
Combinación de reglas de asociación de FP-Growth con Árbol de Decisión
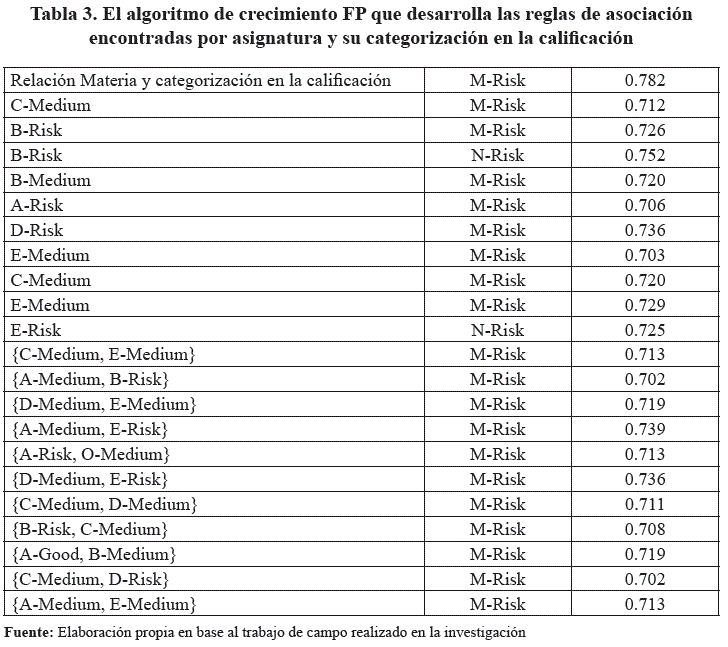
El algoritmo de crecimiento de FP se utiliza para derivar las reglas de asociación. Dado que la proporción de datos en los 395 datos actuales es muy pequeña, la puntuación entre 60 y 70 se define como Riesgo agregado a las reglas de asociación que se estructuran a nivel de sintaxis en la Figura 3.

Como se muestra en la Tabla 3, {C-Medium, E-Medium} -> M-Risk, implica principalmente al sujeto C alcanza una puntuación de 70 a 80 y el sujeto O alcanza una puntuación de 70 a 80, entonces el tema M puede tomar 60-70, debe llamar la atención en base a una notificación personalizada. Otro ejemplo infiere que el factor D-Risk, implica que si el sujeto L alcanza una puntuación de 60-70, entonces es probable que el sujeto N alcance una puntuación de 60-70, es necesario prestar atención al estudio de la N sujeto. Esta es la regla de asociación resultante.
Combinando las reglas derivadas de las reglas de asociación obtenidas como características con un árbol de decisión, el árbol de decisión final incorpora 42 características. Como se muestra en la Figura 1, las categorías de clasificación se dividen en: ¡Quizás-Fallar!, y Éxito. El nodo raíz del árbol de decisión es el curso Física, lo que demuestra que esta asignatura es el atributo más importante para nuestra clasificación. Por ejemplo, si se obtiene una puntuación de 60 a 70, entonces hay una alta probabilidad de que haya un fenómeno de sujetos colgados. Si se obtiene 80-90 puntos, entonces se establece que el número alto -2, si el número alto -2 pasó 60-70 o 70-80, es probable que cuelgue la prueba, si pasa el 80 –100, no colgarás la prueba. Juega un buen papel en la advertencia y el estímulo.
4. Discusión
El uso del árbol de decisión y las reglas de asociación buscan establecer la relación interna a nivel de los datos procesados por el modelo desarrollado, inicialmente por el nivel de segmentación que por naturaleza tiene un árbol de decisión, que por inercia establecerá un fenómeno en los datos que requieren suficientes muestras de acuerdo al grado de confianza y el apoyo de las reglas de asociación del modelo Apriori, se establece que algunas de las relaciones en el experimento solo tienen una pequeña cantidad de datos que las respaldan, la conclusión (relaciones si existieran) no se puede extraer de estos datos, porque una pequeña cantidad de datos no representa reglas comunes.
En consecuencia, el hallazgo de este fenómeno se puede reducir mediante la recopilación de una gran cantidad de datos. De otra manera, se puede lograr estableciendo un factor cuantitativo en el proceso de combinación de los dos algoritmos. En otras palabras, el número calculado se puede lograr mediante reglas acordadas. A través de estas dos formas, la corrección de este modelo podría mejorarse significativamente.
5. Conclusiones
Luego de realizada la investigación en más de 400 estudiantes de pregrado en la Universidad Privada Domingo Savio, han estado involucrados en el objeto de investigación presentado en este artículo. Entre ellos, se seleccionan 5 asignaturas para desarrollar la presente investigación, que propone de manera innovadora la idea de combinar reglas de asociación con un árbol de decisión, que puede combinar información vertical con información sintagmática. Se ha utilizado la visualización de decisiones para decidir las materias que tienen mayor impacto en las calificaciones requeridas y se establecen en la Tabla 1, demostrando la influencia en diferentes grados de acuerdo a la importancia calculada por el método que puede ser ilustrado en la Tabla 3. Además, a partir de los resultados de la visualización del árbol de decisiones, para una asignatura, la influencia es diferente entre los estudiantes de diferentes grados, lo que también tiene un impacto indirecto en el cálculo de la suma de asignaturas posteriores.
Esta forma intuitiva juega un papel importante en la alerta temprana de las notas de aprendizaje, que puede mostrar a los estudiantes directamente qué otras asignaturas deben fortalecerse si quieren mejorar una de las asignaturas principales o troncales de la malla curricular y principalmente las métricas o factores del proceso de enseñanza que se requiere fortalecer. Esto presenta requisitos científicos para la mejora de los puntajes de aprendizaje de los estudiantes, también les ayuda a mejorar significativamente su desempeño.
La alerta temprana de varios grados es una parte importante de la mejora del desempeño general de los estudiantes, lo que conduce a la formación de un modelo completo y sistemático relacionado con el plan de estudios en los colegios y universidades, que realiza de manera efectiva la advertencia temprana de reprobar un examen y proporciona orientación para estrategias de enseñanza y gestión del aprendizaje de los estudiantes.
Bibliografía
Agrawal, R., Imielinski, T., & Swami, A. (1993). Mining Association Rules Between Sets of Items in Large Databases. Sigmod Record, 22(2), 207-216. https://doi.org/10.1145/170036.170072 [ Links ]
Alpaydin, E. (2020). Introduction to machine learning. MIT press. [ Links ]
Azad-Manjiri, M. (2014). A new architecture for making moral agents based on C4. 5 decision tree algorithm. International Journal of Information Technology and Computer Science (IJITCS), 6(5), 50–57. [ Links ]
Houtsma, M., & Swami, A. (1993). Set-Oriented Mining for Association Rules. IBM Research report RJ 9567. [ Links ]
Jun-yu, L. (2014). Analysis of Student’s Achievements Based on Mean Cluster and Decision Tree Algorithm. Computer and Modernization, 0(6), 79–83.
Koenker, R., & Hallock, K. F. (2001). Quantile Regression. Journal of Economic Perspectives, 15(4), 143–156. https://doi.org/10.1257/jep.15.4.143 [ Links ]
Mark, H., Eibe, F., Geoffrey, H., Bernhard, P., Peter, R., & Witten, I. H. (2016). The WEKA Workbench. Online appendix for data mining: Practical machine learning tools and techniques. Morgan Kaufmann. [ Links ]
Vijayalakshmi, V., & Venkatachalapathy, K. (2019). Intelligent Systems and Applications. Intelligent Systems and Applications, 12, 34–45. https://doi.org/10.5815/ijisa.2019.12.04 [ Links ]
Wang, C. (2011). An Investigation and Structure Model Study on College Students’ Studying-interest. International Journal of Modern Education and Computer Science, 3, 33-39. https://doi.org/10.5815/ijmecs.2011.03.05
Ying, Y., & Lv, W. (2011). A Study on Higher Vocational College Students’ Academic Procrastination Behavior and Related Factors. International Journal of Education and Management Engineering, 2, 209–212. https://doi.org/10.1109/ETCS.2011.59
Yongguo, L. (2012). Improved Genetic Algorithm Based Student Score Prediction Model [J]. Bulletin of Science and Technology, 10(28), 223–225. [ Links ]
Zhang, D., & Lou, S. (2021). The application research of neural network and BP algorithm in stock price pattern classification and prediction. Future Generation Computer Systems, 115, 872–879. https://doi.org/https://doi.org/10.1016/j.future.2020.10.009 [ Links ]

