










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkEducación Superior
versión impresa ISSN 2518-8283
Edu. Sup. Rev. Cient. Cepies vol.7 no.1 La Paz mar. 2020
ARTÍCULOS CIENTÍFICOS
Análisis textual de los documentos base para la aplicación de la Ley N° 070
Avelino Siñani - Elizardo Pérez
Textual analysis of the foundational documents for the enforcement of the Law N° 070
Avelino Siñani - Elizardo Pérez

Amusquivar Caballero, Wilma
Docente - Facultad de Ingeniería Universidad Mayor de San Andrés
wamusca@yahoo.com La Paz, Bolivia
Fecha de Recepción: 27 de diciembre de 2019. Fecha de Aprobación: 11 de marzo de 2020 en reunión de comité editorial.
Resumen
El presente trabajo tiene como objetivo determinar un sistema de códigos y categorías asociados a la aplicación de la Ley N° 070 Avelino Siñani - Elizardo Pérez, y en especial determinar la categoría central o núcleo de la propuesta educativa concomitante, a partir del corpus formado por los documentos elaborados como guía para la aplicación de la Ley. Desde una perspectiva cuali -cuantitativa, los métodos empleados fueron: el análisis textual (cuantitativo), complementado con el análisis de cualitativo en cada fase, las técnicas empleadas fueron las lexicométricas y matriciales de agrupamiento (clustering), aplicadas a datos textuales. Como resultado se obtuvieron cinco clústeres, identificados con las siguientes categorías: 1) proceso de enseñanza - aprendizaje, 2) proyecto socio - comunitario, 3) modelo educativo, 4) currículo y 5) base epistemológica. Esta última resultó ser la categoría central o núcleo de la propuesta educativa, lo que sin duda contribuirá a orientar futuras investigaciones en relación a la aplicación de la Ley.
Palabras Clave. Ley N° 070, categoría central, clúster.
Abstract
This paper aims at determining a system of codes and categories associated to the enforcement of the Law N° 070 Avelino Siñani - Elizardo Pérez, and parti cularly at determining the central category or the core of the concomitant educational proposal. That, on the basis of a corpus consisted of documents prepared as a guide for the enforcement of the Law. From a qualitative and a quantitative perspective, the methods used were the textual analysis (quantitative) complemented with a qualitative analysis in each stage. The techniques applied to this research were the lexicometrical and the matrix technique of grouping (clustering) applied to textual data. As a result, five clusters were obtained. They were identified as the following categories: 1) teaching and learning process, 2) socio-communitarian project, 3) educational model, 4) curriculum and 5) epistemological base. The last one turned out to be the central category or the core of the educational proposal, which, surely will contribute to direct future research reIated to the enforcement of the Law.
Keywords. Law N° 070, central category, cluster.
1. Introducción
En circunstancias en las que se cuestiona la vigencia de la Ley N° 070 Avelino Siñani - Elizardo Pérez (Agencia Boliviana de Información, 2019), se confronta nuevamente el advenimiento de una nueva reforma educativa. Para poder formular un modelo de evaluación de la Ley N° 070, y realizar los cambios y transformaciones que requiere el sistema educativo plurinacional es necesario encontrar el núcleo central de la propuesta educativa, inmersa en los documentos emergentes de la Ley N° 070; es decir el conjunto de directrices que orientan su aplicación.
El núcleo es la categoría central del corpus textual, asociado a la Ley. Esta categoría está rodeada de un entramado de categorías periféricas, las que se subordinan a la categoría central. Las funciones del núcleo central son de generación y organización del sistema categorial (Escalante, 2009, p. 58); de acuerdo a esta propuesta, la emergencia de los diferentes elementos de la reforma educativa, que se fueron implementando a lo largo del tiempo; tales como el currículo base, la formación docente y el modelo educativo socio - comunitario productivo tendrían base en el núcleo central.
De ahí que los objetivos de la presente investigación apuntan a obtener: a) un sistema de códigos y categorías y b) la categoría central, como el núcleo de la propuesta educativa contenida en la Ley.
2. Materiales y Métodos
Se tomaron como materiales los textos más importantes de la reforma educativa, implantada por la Ley N° 070 Avelino Siñani - Elizardo Pérez, en su versión digitalizada. Los textos considerados fueron: la Ley N° 070, el Modelo Educativo Sociocomunitario Productivo (Ministerio de Educación [ME], 2017) y el Currículo Base del sistema educativo plurinacional (Ministerio de Educación [ME], 2012). La población del estudio estuvo constituida por todos los documentos oficiales que se publicaron a partir de la promulgación de la Ley N° 070 el año 2010; por tanto, la muestra fue intencional, no probabilística, constituida por los documentos base para la aplicación de la Ley N° 070.
La presente investigación se realizó desde un enfoque cuali-cuantitativo. Se aplicaron los métodos de: a) análisis textual (Romero-Pérez, Alarcón-Vásquez y García-Jiménez, 2018), b) modelación y c) sistematización (Rodríguez y Pérez, 2017). Las técnicas lexicométricas posibilitaron el análisis textual, mediante el cálculo de frecuencias, la reducción del universo textual y la obtención de términos relevantes. La realización de técnicas cálculo matricial y de agrupamiento (clustering), viabilizaron la sistematización de los datos textuales. La modelación se realizó mediante un grafo y su representación matricial (matriz de co-ocurrencias).
Los instrumentos para el registro y el procesamiento de información fueron: el software de procesamientos de textos Atlas.ti 7, la hoja electrónica de cálculo y el software corriente del álgebra lineal. El procesamiento cuantitativo de los datos textuales fue complementado en cada etapa, por el respectivo análisis cualitativo.
Se inició el trabajo con la aplicación de técnicas lexicométricas al corpus textual (Romero-Pérez et al, 2018). Las técnicas usadas para la obtención de las palabras significativas, fueron en primera instancia cuantitativas. Se procedió a construir el universo lexical, el mismo que fue obtenido, mediante: a) la eliminación de las palabras vacías (artículos, conectores, verbos, etc.), b) la lematización o agrupamiento de palabras con la misma raíz, c) la unión de sinónimos y d) la desambiguación de palabras homógrafas.
Posteriormente, mediante el criterio de frecuencias se seleccionaron las palabras de mayor recurrencia en el corpus, considerando como umbral inferior la frecuencia de 300 ocurrencias y como umbral superior 1200. Se procedió luego, a la codificación mediante el análisis cualitativo del significado de cada palabra en su contexto. Se determinaron como términos relevantes, aquellos cuyo uso era el más adecuado para el lenguaje especializado, los que posteriormente dieron lugar a 21 códigos.
Una vez determinados los códigos, dentro del proceso de modelación, se establecieron las citas textuales (Muñoz-Justicia y Sahagún-Padilla, 2017), mediante la búsqueda de citas en las que están presentes los códigos. Si bien el trabajo se realizó con apoyo de software, fue necesario contextualizar la ocurrencia de cada código, mediante la lectura del parágrafo correspondiente y la evaluación de relevancia del código en contexto, procediendo a la obtención de la cita respectiva, llegando a totalizar 6148 citas. Con las citas elaboradas se procedió a la obtención automática de la matriz de co-ocurrencias, tomando como referente la oración en la que co-ocurren o aparecen dos códigos simultáneamente, obteniendo así una matriz de 21 filas por 21 columnas.
Cada elemento de la matriz encontrada, registró la frecuencia de co-ocurrencia entre dos códigos, la matriz obtenida es simétrica, con valores igual a cero en la diagonal y valores positivos en el resto de las posiciones, estos últimos valores son las frecuencias absolutas de co-ocurrencia entre códigos. Esta matriz representa a un grafo con 21 vértices y 7334 aristas.
Una vez obtenida la matriz, y mediante el cálculo del autovector principal, que corresponde al autovalor máximo de la matriz de coocurrencias, se logró establecer la importancia o centralidad de cada código a través del cálculo matricial. Según el teorema de Perron -Frobenius (Abreú y Del-Vecchio, 2014, pp. 36-37), se estableció que el grado de centralidad o influencia de los códigos, determinado por las posiciones asignadas a cada variable (código).
Para la obtención de agrupamientos o clústeres de términos se trabajó con la matriz de Laplace: L = D - A, fórmula en la que A es la matriz de co-ocurrencias y D es una matriz diagonal, cuyos elementos están determinados por la suma de los elementos de las respectivas filas de A (Abreú y Del-Vecchio, 2014). Luego, la matriz de Laplace L se sometió a un proceso de diagonalización. Luego se determinó el autovalor más pequeño superior a cero, para la obtención del vector de Fiedler (Berzal, 2014). Este vector permitió, mediante los signos de sus elementos, dividir en dos agrupamientos el conjunto de códigos, agrupando en un clúster a los códigos cuya posición corresponde a los signos positivos, y por otra parte los códigos correspondientes a los signos negativos.
Se adoptó el método de agrupamiento mediante el vector de Fiedler, en vista de la optimización que representa en su aplicación, ya que minimiza el número de cortes que implica el proceso de agrupamiento. Este proceso (Kisner y Thomas, 2018) fue repetido cuatro veces, llegando a obtener cinco clústeres de códigos, estos agrupamientos fueron sometidos a un análisis cualitativo, remitiendo su significado al contexto de los códigos, a través de citas textuales. Se obtuvo como resultado de este análisis, el sistema de categorías emergentes del proceso de agrupamiento (Romero-Pérez et al., 2018).
Para el análisis cuantitativo de los clústeres se vinculó el número de aristas del grafo, asociado a cada clúster, y el número de códigos del clúster, tanto en su vinculación interna como externa, a través de los indicadores de densidad (conectividad interna) y centralidad (conectividad externa). Posteriormente se calcularon la densidad de cada clúster y su centralidad mediante las siguientes fórmulas:

Finalmente, una vez obtenidas las categorías asociadas a los clústeres, así como los índices de centralidad y densidad, se procedió a la determinación de la categoría central, como la categoría asociada al clúster de mayor centralidad y densidad.
3. Resultados
La selección de términos relevantes se realizó a partir de la frecuencia de aparición, en el corpus textual, tomando como criterio cuantitativo la frecuencia relativa mínima de 3% sobre el universo considerado. Posteriormente, para la obtención de códigos desde el punto de vista cualitativo, se realizó la revisión de los términos relevantes en contexto, optando por aquellos, cuyo uso era el más adecuado para el lenguaje especializado. Como resultado de este criterio se obtuvieron 21 términos relevantes (Tabla 2 y Figura 1).
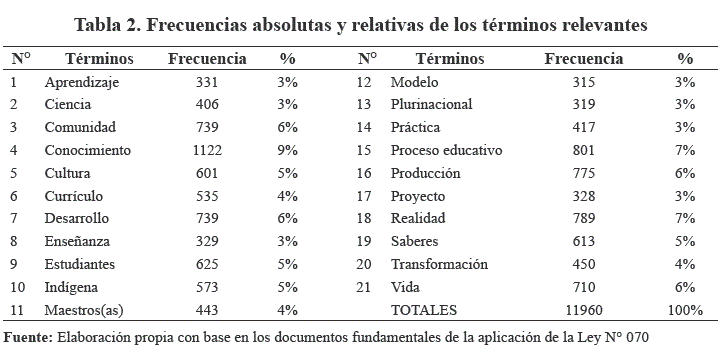
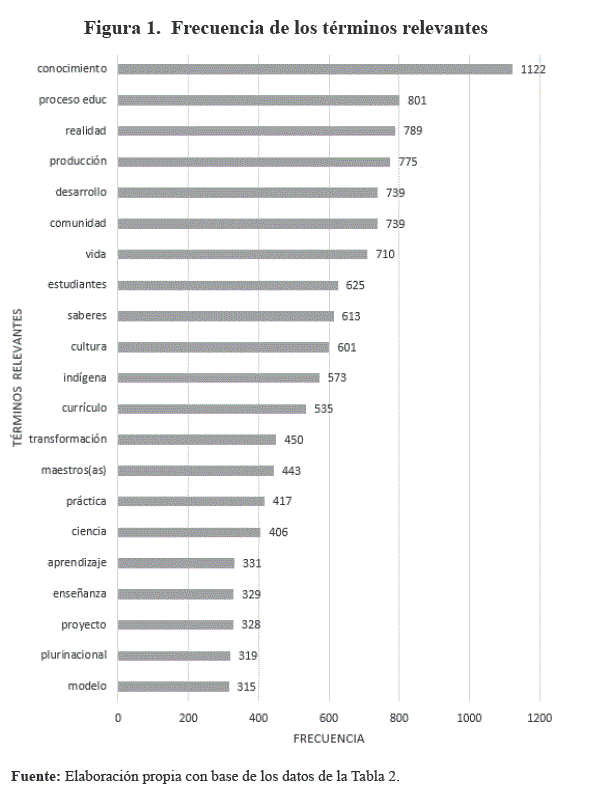
Centralidad de los códigos
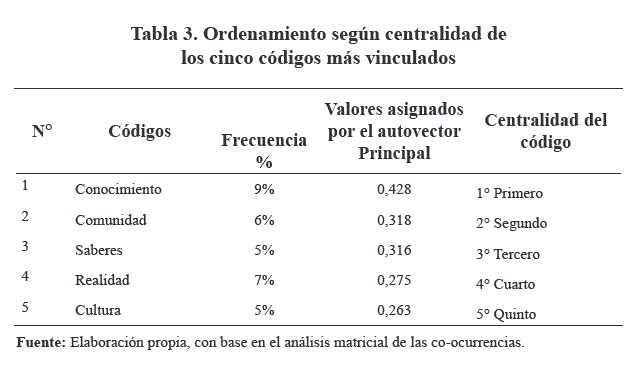
Se obtuvo como el código central al conocimiento, seguido de los códigos: saberes, comunitario y cultura; cabe hacer notar, que este ordenamiento no coincide con el de las frecuencias, lo que muestra que para que un código sea importante, no es suficiente una frecuencia elevada, sino el grado de conexión o relación con el resto de los códigos. Existe una mayor presencia de códigos asociados a lo cognitivo, lo comunitario y la cultura. En cuanto al código: realidad, presenta sus vínculos más fuertes con los códigos: conocimiento y transformación, en este último caso la asociación nos muestra la frase "transformación de la realidad" como recurrente, esta aparece 54 veces en el corpus textual. A continuación, se muestran los cinco primeros códigos en la Tabla 3.
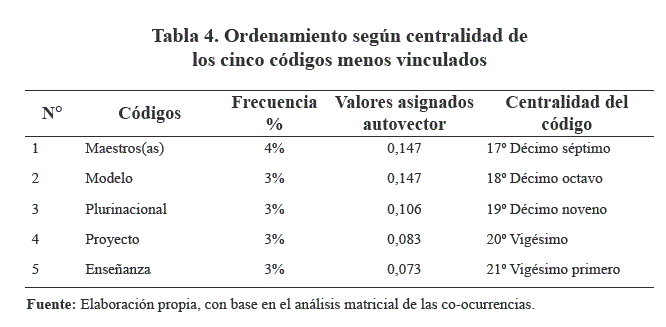
Entre los últimos códigos en orden de centralidad, están aquellos que figuran en los puestos vigésimo y vigésimo primero: proyecto socio-productivo y enseñanza, respectivamente. Lo que explica la escasa importancia que se otorgó a la actividad propiamente docente, en la aplicación de la reforma asociada a la Ley N° 070 Avelino Siñani - Elizardo Pérez; mientras que en el caso del proyecto socio - productivo, su introducción fue tardía (ME, 2017).
Agrupamientos o clústeres de códigos
Para la sistematización de los 21 códigos en agrupamientos o clústeres, se procedió al cálculo del vector de Fiedler de la matriz de Laplace L, en la primera bipartición y se obtuvo el primer clúster que contiene a las categorías de aprendizaje y enseñanza. Posteriormente, se repitió el proceso en cuatro oportunidades, llegando a obtener cinco clústeres de códigos, tal como se muestra en el diagrama de árbol expuesto en la Figura 2.
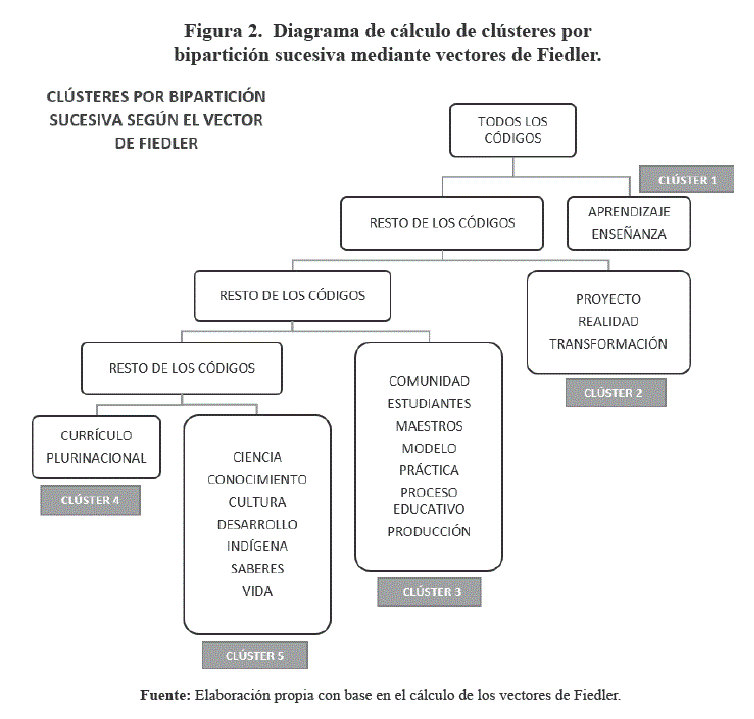
Análisis cualitativo de los clústeres
Para el análisis cualitativo de los clústeres, se extrajeron citas textuales del material bibliográfico analizado, que muestran la relación entre los códigos que componen cada clúster. Se seleccionaron citas que vinculan los códigos pertenecientes al clúster analizado (Tabla 5).
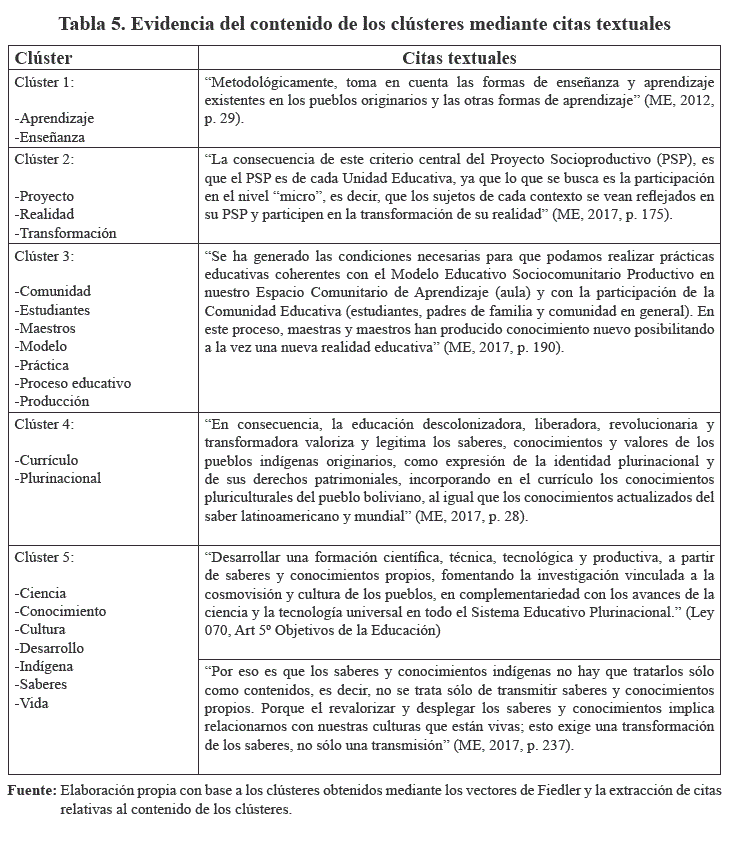
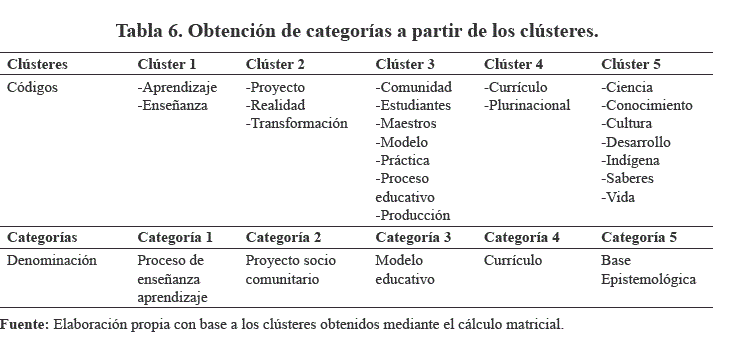
Del análisis de los códigos correspondientes a cada clúster, y de acuerdo a la contextualización mediante las citas extraídas, de las que se exponen solo ejemplos, se procedió a la construcción de las categorías. En este proceso se identificaron las siguientes categorías: proceso de enseñanza - aprendizaje (clúster 1), proyecto socio - comunitario (clúster 2), modelo educativo (clúster 3), currículo (clúster 4) y base epistemológica (clúster 5). Estas categorías se detallan en la Tabla 6:
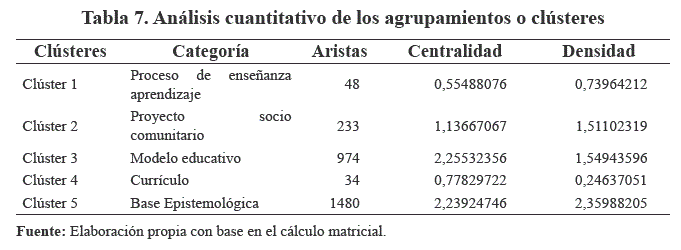
Análisis cuantitativo de los agrupamientos o clústeres
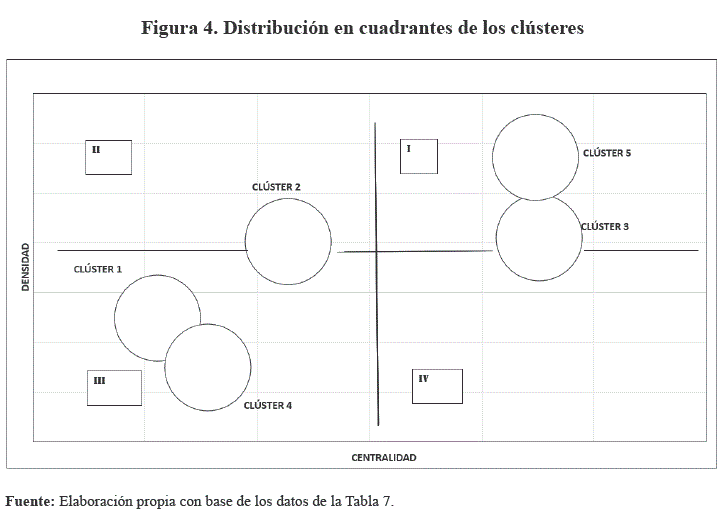
Se determinaron los grafos asociados y las sub-matrices de co-ocurrencia, para cada clúster, llegando a establecerse la influencia tanto interna como externa de cada uno, de acuerdo a cálculos de densidad y centralidad (Ruíz de Osma et al., 2014), los que se pueden apreciar en la Tabla 7 y Figura 3. Esto posibilitó mediante el gráfico de la Figura 4, establecer que la categoría: base epistemológica, correspondiente al clúster 5,
ubicada en el cuadrante I, con fuerte centralidad y la mayor densidad, como la categoría central o núcleo de la propuesta educativa. Esta categoría resulta determinante para el resto, tal como se puede apreciar en la Figura 4, en segundo término, tenemos a la categoría de modelo educativo, que corresponde al clúster 3, mientras que el resto de categorías de baja densidad y baja centralidad se ubican en el cuadrante III, por tanto, son periféricas y subordinadas a la categoría central (Figura 3).

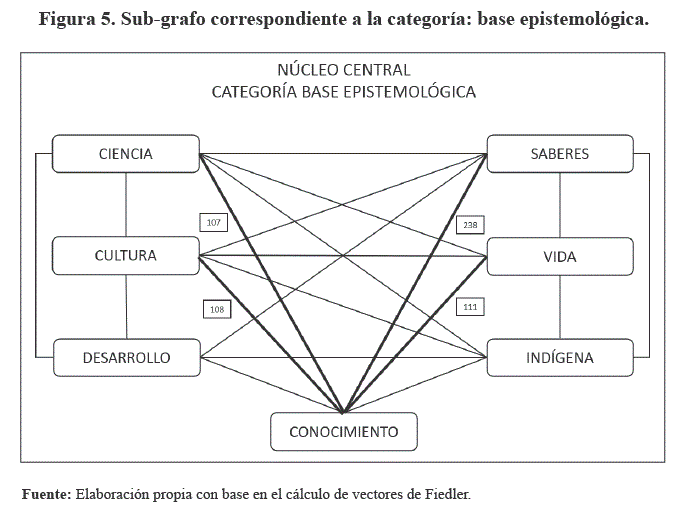
De los datos tanto cuantitativos como cualitativos, obtenidos en el análisis del clúster, setiene a la categoría: base epistemológica, como el núcleo central de la propuesta educativa. En la Figura 5 se muestra el grafo correspondiente a la categoría central, en línea gruesa tenemos las aristas ponderadas con los enlaces más fuertes, entre los códigos que componen el clúster. Corresponde al código conocimiento, la centralidad dentro de la categoría, fuertemente vinculado con 238 co-ocurrencias con el código saberes, el cual alude al conocimiento generado por las culturas nativas.
La base epistemológica en los documentos analizados, se presenta como contestataria al desarrollo hegemónico de la ciencia occidental, y se plantea como una alternativa eficaz a la generación de conocimiento científico, mediante la sistematización de los saberes y tecnologías ancestrales, practicados por las culturas nativas y pueblos indígenas. También encomienda a la comunidad educativa la sistematización de este conocimiento, así como su puesta en vigencia mediante proyectos educativos y comunitarios, como una alternativa al desarrollo científico y tecnológico de occidente, identificado con el sistema capitalista (ME, 2017). De una revisión de los estudios relativos al tema, se tiene que esta propuesta epistemológica no superó la fase discursiva (Aillón, 2015), lo cual nos invita a profundizar los estudios sobre la reforma educativa, en dirección al análisis de la base epistemológica y su concreción en la práctica educativa.
4. Discusión
En la mayoría de los trabajos de investigación se aborda el análisis de grandes volúmenes de información textual, mediante el uso de ordenadores, para el procesamiento de los datos textuales; si bien esta tendencia no es reciente, en la actualidad ha cobrado un gran auge, por los siguientes aspectos: a) creciente capacidad de los ordenadores, b) la difusión de la teoría de redes (grafos) transversal a todas las disciplinas, y c) la producción de un gran número de programas de software destinados al procesamiento cualitativo de la información.
En la actualidad, el procesamiento de datos textuales ha superado la descripción de frecuencias, planteándose como tarea el agrupamiento (clustering) de datos, con la finalidad de generar sistemas de códigos y categorías. En este último caso, los métodos más difundidos son aquellos que tienen su aplicación en la teoría de redes o en diferentes campos de la ciencia y la tecnología, como se aprecia en el trabajo de von Luxburg (2007), en especial el método de k-medias (k-means); sin embargo, estos métodos presentan una gran incertidumbre en la obtención final de los agrupamientos (clústeres), debido a que estos métodos trabajan con aproximaciones sucesivas, e inician el proceso de aproximación con clústeres arbitrarios; debido a esta incertidumbre, según von Luxburg (2007) se deben remitir siempre los resultados al contexto de aplicación.
En el caso de procesamiento de datos textuales, consideramos más adecuado el método de vectores de Fiedler, debido a que su aplicación es simple y directa, reduce la incertidumbre y permite separar los agrupamientos periféricos, de baja densidad, de los agrupamientos más densos y de gran centralidad (Bertrand y Mooned, 2013); lo que nos permite efectivizar la concreción del objetivo central de nuestra investigación: hallar el núcleo central de la propuesta educativa contenida en los documentos base de aplicación de la Ley N° 070. La aplicación de este método determina como núcleo central a la base epistemológica, resultando periféricas las restantes categorías vinculadas a aspectos pedagógicos, lo que muestra la preponderancia del discurso epistemológico sobre el discurso propiamente educativo.
La aplicación de la estrategia metodológica propuesta en el presente trabajo, representa una forma eficaz de abordar el análisis de documentos, identificando la categoría del núcleo central, así como las periféricas; lo que permite abordar al núcleo central, como tema de futuras investigaciones.
5. Conclusiones
El sistema de códigos y categorías, asociados a la Ley N° 070, consta de veintiún códigos, agrupados en cinco clústeres, identificados con las siguientes categorías: 1) proceso de enseñanza - aprendizaje, 2) proyecto socio-comunitario, 3) modelo educativo, 4) currículo y 5) base epistemológica.
Se determinó que la categoría central o núcleo de la propuesta educativa, asociada a la Ley N° 070, es la categoría: base epistemológica, mostrando la preponderancia del discurso epistemológico sobre el discurso pedagógico.
La aplicación de la estrategia metodológica que comprende el análisis textual y la sistematización de la información textual en clústeres, mediante el método del vector de Fiedler, permitió obtener un sistema de códigos y categorías, así como la categoría central y las categorías periféricas en forma directa.
La determinación de la base epistemológica como categoría central induce a profundizar los estudios sobre la reforma educativa asociada a la Ley N° 070, en dirección a la concreción del discurso epistemológico en la práctica educativa.
6. Bibliografía
Abreú, N., y Del-Vecchio, R. (2014). Teoría espectral de grafos. Una introducción. III Coloquio de Matemática de la región del sur. Florianópolis, Brasil. Recuperado de http://mtm.ufsc.br/coloquiosul/notas_mini curso_6.pdf [ Links ]
Agencia Boliviana de Información. (30 de noviembre de 2019). Magisterio urbano de La Paz pide abrogación de la Ley 070 y jubilación al 100%. El Día. Recuperado de https://www.eldia. com.bo/index.php?cat=1&pla=3&id_ articulo=292420 [ Links ]
Aillón, T. (2015). Posibilidades de producción de conocimiento desde la epistemología pluricultural en Bolivia. Praxis Educativa. Ponta Grossa, 10(2), 415-432. Recuperado de https://dialnet.unirioja.es/servlet/ articulo?codigo=5025687 [ Links ]
Bertrand, A., y Mooned, M. (2013). Seeing the bigger picture: How nodes can learn their place within a complex ad hoc network topology. IEEE Signal Processing Magazine, 30(3), 1-11. Recuperado de http://www.handicams-fet.eu/uploads/files/2.pdf [ Links ]
Berzal, F. (2014). Detección de comunidades [PowerPoint slides]. Recuperado de https://elvex.ugr.es/idbis/dm/slides/53%20Graph%20Mining%20 -%20Community%20Detection.pdf [ Links ]
Escalante, E. (2009). Una nota metodológica sobre los análisis cualitativos. El análisis de las relaciones entre los elementos: el análisis de las frecuencias y coocurrencias. Theoria, 18(1), 1-11. Recuperado de https://www.redalyc. org/pdf/299/29911857006.pdf [ Links ]
Kisner, H., y Thomas, U. (2018). Segmentation of 3D Point Clouds using a New Spectral Clustering Algorithm Without a-priori Knowledge. SCITEPRESS Papers, 315-322. Recuperado de https://www.scitepress.org/Papers/2018/65493/65493.pdf [ Links ]
Ley N° 070 Avelino Siñani - Elizardo Pérez. Gaceta Oficial de Bolivia, La Paz, Bolivia, 20 de diciembre de 2010.
Ministerio de Educación. (2012). Currículo Base del Sistema educativo plurinacional. Recuperado de https://www.minedu. gob.bo/files/publicaciones/veaye/dgea/5.-Curriculo-Base-del-SEP-diciembre-de-2012.pdf [ Links ]
Ministerio de Educación. (2017). Compendio Unidades de Formación -PROFOCOM. "Modelo Educativo Sociocomunitario Productivo Subsistema de Educacion Regular". La Paz, Bolivia: Equipo PROFOCOM. [ Links ]
Muñoz-Justicia, J., y Sahagún-Padilla, M. (2017). Hacer análisis cualitativo con Atlas. ti 7. Recuperado de https://www. researchgate.net/profile/Juan_Munoz7/ publication/288824979_Hacer_ analisis_cualitativo_con_Atlasti_7/ links/589b02b892851c8bb6845ddb/ Hacer-analisis-cualitativo-con-Atlasti-7.pdf [ Links ]
Rodríguez Jiménez, A., y Pérez Jacinto, A. O. (2017). Métodos científicos de indagación y de construcción del conocimiento. Revista Escuela de Administración de Negocios, (18), 1-26. Recuperado de https://www. redalyc.org/pdf/206/20652069006.pdf [ Links ]
Romero-Pérez, I., Alarcón-Vásquez, Y., y García-Jiménez, R. (2018). Lexicometría: Enfoque aplicado a redefinición de conceptos e identificación de unidades temáticas. Biblios, (71), 68 - 80. Recuperado de http://www.scielo.org.pe/pdf/biblios/n71/a05n71.pdf [ Links ]
Ruíz de Osma, E., Ruíz-Baños, R., y de La Moneda, M. (2014). Análisis ciencimétrico de las publicaciones de la internacional society for nowledge organization. ISKOIBÉRICO. Recuperado de http://www.iskoiberico.org/wp-content/ uploads/2014/09/217-222_Ruiz-de-Osma.pdf [ Links ]
Von Luxburg, U. (2007). A tutorial on spectral clustering. Statistics and Computing, 17(4), 1-32. Recuperado de https://www.researchgate.net/publication/234801250_A_Tutorial_ on_Spectral_Clustering [ Links ]

