











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. INTRODUCCIÓN
Como individuos racionales, los inversionistas al momento de invertir buscan conformar un portafolio con la mejor selección de activos disponibles que logren la óptima relación entre riesgo y rendimiento; es decir, una combinación que maximice su rentabilidad esperada asumiendo un mínimo riesgo posible de pérdida [1]. Hace más de 70 años, la economía financiera inició su investigación para satisfacer esta necesidad de los inversionistas, hecho que derivó en la aparición de una teoría que enmarca la toma de decisiones de inversión llamada Teoría Moderna de Carteras.
En 1952, el economista Harry Markowitz publicó el artículo Portfolio Selection, en el que expone su teoría basada en la distribución de activos en un portafolio en relación con dos criterios: maximizar la rentabilidad para un nivel máximo de riesgo o alternativamente, minimizar el riesgo para una rentabilidad mínima esperada[2]. A partir del supuesto de que los inversionistas únicamente asumirán más riesgo si son compensados con una mayor rentabilidad esperada[3], se considera la rentabilidad de un portafolio como una variable aleatoria calculada a partir de una distribución de probabilidad para un periodo de tiempo. Precisamente, el valor esperado de dicha variable aleatoria cuantifica la rentabilidad, además de que se considera a la varianza como medida de riesgo para cada activo y para todo el portafolio[2]. Con su trabajo, Markowitz reveló que el rendimiento de un portafolio está determinado por el rendimiento promedio ponderado de los activos, mientras que el riesgo depende de la covarianza entre los activos que componen el portafolio[4].
Este modelo buscaba una combinación de todas las posibilidades de inversión que optimicen la relación riesgo-rendimiento y que al agruparlas conformen una frontera eficiente de la que no es posible obtener una mejor relación [3]. Si bien es a partir de estas dos variables que se desarrolla el modelo, se añade la correlación entre los activos como otro elemento clave para medir el riesgo de la cartera y ver el efecto de los cambios de rendimiento de un título sobre otro[5]. Fundamentalmente, el modelo de Markowitz quería expresar que “la capacidad para manejar el riesgo de una cartera se basa en la correlación esperada entre los activos que la integran” [3], introduciendo de manera implícita la idea de diversificación. Esta teoría pretendía mostrar que “gran parte del riesgo de los títulos puede eliminarse mediante la formación de carteras” [6].
Es por esto que el principal aporte a la teoría moderna de portafolios es el principio de que el riesgo total de una cartera disminuye con la diversificación. Esto hace referencia a que la variedad de posibles resultados del retorno promedio esperado durante y al final del horizonte de inversión es menor en una cartera con una óptima composición de valores[3]. La investigación y análisis de Markowitz vinculada a la gestión del riesgo en una inversión es el primer modelo propuesto de selección de carteras, y es esencial para el desarrollo de nuevas ideas y modelos. Este trabajo marcó el punto de partida para que varios investigadores realicen aportes adicionales con el fin de lograr un modelo más consistente y eficaz[2].
A partir del modelo tradicional y clásico de selección de carteras de inversión propuesto por Markowitz en 1952, se abre el espacio a que otras investigaciones contribuyan a la teoría de los portafolios. En este sentido, “se han desarrollado en la investigación varias alternativas a este, se han propuesto nuevos estimadores de rentabilidad y riesgo, y se han introducido nuevos objetivos al problema. Todas estas aportaciones han tenido el objetivo común de mejorar los resultados empíricos o prácticos del Modelo de Markowitz.” [7].
Los fundamentos matemáticos para el desarrollo de la Inteligencia Artificial (AI), disciplina que busca replicar y desarrollar la inteligencia, han estado presentes desde los años cincuenta, más su aplicación generalizada ha sido posible gracias a los avances tecnológicos recientes[8]. Esto se traduce en el aumento de emisión de datos (Big-Data) con millones de dispositivos electrónicos conectados, además de numerosas interacciones online que producen grandes cantidades de datos electrónicos a tiempo real[9], el abaratamiento de los costes de almacenamiento de información y la computación en la nube. Esto en conjunto ha permitido acceder y procesar grandes cantidades de información y a mayor velocidad, lo que ha impulsado el uso de IA en trabajos empíricos para la toma de decisiones[8].
Dentro de la Inteligencia Artificial y a partir del año 2006, se populariza el Aprendizaje Automático o Machine Learning (ML) como una rama de esta disciplina[10] que permite usar modelos matemáticos para que los ordenadores aprendan automáticamente a realizar tareas y resolver problemas a partir de una serie de datos existentes sin instrucciones directas[8]. Es de la mano de grandes empresas como Microsoft, IBM, Google, Facebook y Amazon, que al lanzar sus plataformas de Machine Learning, expanden globalmente el manejo y procesamiento de datos de ML [10].
Dentro de las Finanzas, la creciente presencia y uso de los modelos de ML predomina por sobre todo en áreas vinculadas al:
Riesgo de crédito y decisión sobre la concesión de préstamos, un área en la que existe consenso del beneficio potencial derivado del uso de ML al poder lograr una predicción más precisa de posibles impagos[8].
Prevención de fraude y el control del blanqueo de capitales, considerando que los modelos de ML coadyuvan en la detección de anomalías. La complejidad en los patrones de pagos y transferencias por la diversidad en los medios de pago, son un escenario óptimo para el uso de técnicas de ML en el procesamiento de una gran cantidad de información[8].
Predicción de variables financieras, como el retorno de acciones o de índices de referencia de renta variable o el tipo de cambio[8].
Si bien estas áreas tienen una gran relevancia potencial y nivel de uso actual de técnicas de Machine Learning por parte de entidades financieras, existen también otras áreas donde se aplica el ML, como lo es el área de gestión de carteras[8]. Dentro de esta área se han implementado diferentes técnicas, entre ellas las técnicas de Clustering, con el fin de ser una alternativa más para los modelos de selección de carteras de inversión.
Las técnicas de Clustering forman parte de la rama de aprendizaje no supervisado de la Inteligencia Artificial. Son técnicas descriptivas útiles para identificar patrones que explican o resumen los datos mediante la exploración de sus propiedades[11]. Para el área de gestión de portafolios, ante una muestra de empresas de las que se dispone una serie de observaciones como precios de acciones, el análisis de Clustering permite clasificarlas en grupos lo más similares posible en base a variables observadas como el riesgo y/o el rendimiento[12], considerando al mismo tiempo los efectos de la diversificación propuesta inicialmente por Markowitz.
En ese contexto, la presente investigación aborda la siguiente pregunta de investigación: ¿Las técnicas de Clustering de Machine Learning mejora el proceso de estructuración de portafolios de inversión de renta variable en comparación con las técnicas tradicionales, generando así medidas de rentabilidad-riesgo óptimas?
El objetivo general es aplicar la técnica de Clustering de Machine Learning en la estructuración de carteras de inversión de renta variable para maximizar las medidas de rentabilidad y riesgo, centrándose en las empresas que cotizan en el índice bursátil Standard & Poor’s 500 (S & P 500).
Para alcanzar este objetivo, el trabajo se organiza en cinco partes: Después de la introducción, en la segunda sección se desarrolla el marco teórico, donde se abordan conceptos sobre Machine Learning,Graphical Lasso, algoritmos de Clustering, Manifold Learning a través de Multi-Dimensional Scaling, Red Gráfica, las herramientas de Machine Learning y las herramientas financieras.
En la tercera sección, se presenta la metodología de investigación y se expone el proceso dela estructuración de 30 portafolios mediante la técnica de Clustering y se explica la metodología para la comparación con portafolios estructurados a partir de técnicas tradicionales.
La cuarta parte se centra en los resultados del estudio. Inicialmente, se contrastan los resultados globales de las técnicas tradicionales. Luegose exponen los resultados específicos de la técnica Clustering, presentando los tres mejores y peores portafolios tras relacionar métricas de rentabilidad y riesgo entre sí, y se realiza un análisis comparativo entre técnicas tradicionales y Clustering. Finalmente, en la quinta parte, se exponen las conclusiones de la investigación.
2. MARCO TEÓRICO
2.1. Aprendizaje automático o Machine Learning (ML)
El Machine Learning (ML) es una rama de la Inteligencia Artificial (IA) que utiliza técnicas estadísticas y algoritmos computacionales para proporcionar a las computadoras la capacidad de aprender[13] a reconocer patrones, extraer conocimiento, descubrir información y hacer predicciones[14]. Por medio de estas capacidades, las máquinas pueden convertir un conjunto amplio de cifras y datos en conocimiento, resultando ser útil tanto para tomar sus propias decisiones como para que las personas amplíen su conocimiento y se pueda reducir los errores en la toma de decisiones [15].
ML se caracteriza por permitir a las maquinas mejorar sus resultados en una tarea especifica a través del entrenamiento en grandes volúmenes de datos[16], todo esto realizado de manera automática, sin instrucciones explicitas externas [13]. La construcción de modelos de Machine Learning requiere adaptaciones propias debido a la naturaleza de los datos o el contexto al que se aplica. Es por esto que resulta necesario investigar diversas técnicas que permitan obtener resultados precisos y confiables en un tiempo razonable [16]. Machine Learning se clasifica en tres grandes corrientes que se enfocan en entrenar estos modelos:
Aprendizaje Supervisado o Supervised Learning (SL): Los algoritmos de SL utilizan la técnica de entrenamiento y prueba, basada en dividir un conjunto de datos etiquetados (preclasificados) en dos [16], la primera parte para entrenar un modelo predictivo y la otra para evaluar su rendimiento. El proceso de entrenamiento dura hasta que el modelo alcance un determinado nivel de precisión[16]. Este entrenamiento a las maquinas permite que aprendan a seleccionar y clasificar dichas etiquetas y aplicarlas en otras bases de datos.
Aprendizaje No Supervisado o Unsupervised Learning (UL): Los algoritmos de UL no están programados para detectar un tipo específico de datos[17], es decir, que el conjunto de datos no presenta etiquetas explicitas. Al contrario, cuando las maquinas reciben los datos, buscan patrones y estructuras ocultas presentes en los datos de entrada, de tal forma que se puedan agrupar los conjuntos de datos que sean similares[15]. Unsupervised Learning es menos restringido en el contexto de una clasificación particular y permite que las maquinas revelen información interesante en los datos. Al igual que la técnica de Aprendizaje Supervisado, utiliza la técnica de entrenamiento y prueba para evaluar la calidad de la solución del modelo predictivo [16].
Aprendizaje por Reforzamiento o Reinforcement Learning (RL): Los algoritmos de RL utilizan la técnica de prueba y error, combinando datos etiquetados y no etiquetados para generar una función deseada o clasificador[16]. Reinforcement Learning permite a la maquina interactuar con un entorno para aprender en base a señales de recompensa o castigo (retroalimentación) a ajustar su política de decisión de tal forma que logre conseguir la mayor recompensa posible en la tarea determinada[14]. Tras llegar a la mejor solución, la maquina la aprende para acudir a ella en caso de que la necesite de nuevo[15].
Dentro de Unsupervised Learning(UL), encontramos tres técnicas que se complementan entre sí para realizar un Análisis Gráfico detallado del comportamiento de acciones. En primer lugar, la técnica Graphical Lasso proporciona una estimación de la matriz de precisión que revela las relaciones de dependencia entre variables. Estas relaciones se utilizan como base en el proceso de Clustering. Acto seguido, la técnica principal en este análisis es Clustering vía Affinity Propagation, que identifica Clusters o grupos significativos de acciones en función de patrones en el conjunto de datos y su similitud.
Para mejorar aún más la interpretación y visualización de los Clusters, se incorpora Manifold Learning a través de Multidimensional Scaling. La información obtenida previamente de Graphical Lasso y Affinity Propagation guía este proceso, permitiendo la transformación de datos hacia un espacio visual más manejable que facilite la percepción de patrones y relaciones entre las acciones, enriqueciendo así la comprensión del Análisis Gráfico.
Finalmente, se utiliza una Red Gráfica para visualizar los resultados del análisis gráfico de una manera clara y comprensible. Esta herramienta permite visualizar los Clusters identificados por Affinity Propagation y destaca las relaciones significativas entre las acciones.
2.2. El algoritmo deGraphical Lasso (Least Absolute Shrinkage and Selection Operator)
Graphical Lasso es una técnica que permite estimar la matriz de covarianza inversa
En dicho caso, la alta dimensionalidad provocará que la matriz tenga una significativa cantidad de error muestral y, sobre todo, la estimación de la matriz de precisión esté sesgada. Este problema puede dificultar la identificación de patrones en los datos y de relaciones significativas entre las variables, además de conducir a modelos estadísticos que se ajusten bien a los datos de entrenamiento mas no así a los de prueba [18].
Teniendo en cuenta estos problemas, se han llevado a cabo estudios con el fin de buscar técnicas que disminuyan la dimensión de la matriz Σ además de reducir el sesgo de la estimación. Estos estudios son posibles con la existencia de ordenadores cada vez más potentes. Entre las soluciones encontradas destaca la técnica de encogimiento (shrinkage) Graphical Lasso [18].
Cuando la técnica Graphical Lasso estima la matriz de precisión, busca que esta sea lo más dispersa posible, es decir, que la matriz contenga la menor cantidad posible de elementos no nulos. Para lograr esto, añade un término de penalización o regularización de norma
donde y: Vector de tamaño n que contiene los valores observados de la variable de interés (variable dependiente) del modelo de regresión lineal; X: Matriz de tamaño n x p que contiene los valores observados de las variables predictoras o explicativas (variables independientes) del modelo de regresión lineal. Cada fila de X corresponde a una observación distinta mientras que cada columna corresponde a una variable explicativa distinta; β: Vector de tamaño p que contiene los coeficientes que se estiman en el modelo de regresión lineal. Cada coeficiente corresponde al de una variable explicativa distinta[19].
Cabe mencionar que la penalización
Esta técnica de validación empleada en el presente trabajo utiliza el proceso de entrenamiento y prueba antes descrito. La Validación Cruzada divide los datos en subconjuntos de tamaño similar, realizando ajustes en el conjunto de entrenamiento y evaluando su desempeño en el conjunto de prueba. Después de repetir este proceso para cada subconjunto, se calcula una medida de desempeño promedio sobre cada uno[19]. En particular, la función Graphical Lasso CV empleada mediante la biblioteca Scikit-Learn, utiliza la medida de desempeño “log-likelihood”, que mide la probabilidad de que los datos observados se ajusten al modelo de matriz de precisión aprendido por el algoritmo. En la implementación, la función trabaja con el promedio de esta medida sobre cada subconjunto y selecciona como óptimo, el valor de lambda que maximice “log-likelihood” promedio.
De igual forma, al momento de estimar la matriz de precisión se utiliza la técnica de las correlaciones parciales precisamente para definir las variables con relaciones relevantes. La correlación parcial mide la relación directa entre dos variables, eliminando los efectos que otras variables intermedias o confusas pueden tener sobre ellas. Una vez estimada la matriz de precisión, se obtiene la información sobre la independencia condicional entre variables. La independencia condicional es un concepto de la teoría de probabilidades que en la matriz hace referencia a la ausencia de una relación directa entre dos variables después de haber eliminado el efecto de otras variables. En la matriz, los elementos no nulos indican una relación entre dos variables mientras que los elementos nulos son los que denotan independencia condicional. Al conocer el valor de las demás variables a través de la correlación parcial, el valor de la variable en cuestión ya no se encuentra influenciado por dichas variables y por ende, se dice que es independiente condicionalmente de ellas[18].
2.3. Algoritmos de Clustering: Affinity Propagation
Los algoritmos de Clustering buscan la división de los datos en grupos o conglomerados[20]denominados “Clusters” que reflejan una estructura relativamente homogénea de la información que representan los datos[21]. Es así como “un Cluster es una colección de objetos de datos que son similares a otros dentro del mismo Cluster y son distintos a los objetos de otros Clusters” [11]. Si bien este proceso conlleva la pérdida de los detalles, el representar los datos por una serie de Clusters permite su simplificación[12]. Mediante el Clustering, es posible descubrir patrones de distribución global y correlaciones interesantes entre patrones de datos[11].
Si nos enfocamos en el Clustering de Propagación por afinidad o Affinity Propagation(AP) utilizado en este trabajo, es un método de Clustering No Jerárquico que genera grupos sin una estructura definida por niveles, por lo que cada punto de datos pertenece a un solo Cluster [22]. Esta técnica de Unsupervised Learning utiliza la matriz de covarianzas como entrada para el algoritmo. Considerando que la técnica Graphical Lasso estima la matriz de precisión dispersa, se calcula su inversa para usar la matriz de covarianza en el Clustering. La razón de este proceso radica en que el algoritmo de Affinity Propagation aplicado mediante Scikit - Learn no admite la matriz de precisión directamente como entrada. Affinity Propagation necesita de una medida de afinidad, es decir, una medida que cuantifique la similitud entre pares de datos, para poder construir una matriz de similitud S que agrupe los puntos que son más similares o afines entre sí en un mismo Cluster [23]. En este caso, se usa la distancia euclidiana basada en la covarianza entre pares de datos que indica que mientras más alto es su valor, más similares son estos dos puntos [24]:
donde
Los ejemplares descritos en
El mensaje de responsabilidad definido por
donde
Por otra parte, el mensaje de disponibilidad
Por otra parte, se da lugar a la auto - disponibilidad que hace referencia a que un punto de datos esté dispuesto a ser su propio representante y que por ende, se encuentre en un Cluster por sí mismo[23]:
Cabe mencionar que el intercambio de mensajes se da únicamente entre pares de puntos donde el valor de afinidad es conocido y se realicen iteraciones hasta alcanzar un número determinado de iteraciones o hasta lograr la optimización en[23]:
El intercambio de mensajes actualiza constantemente la matriz de responsabilidad R y la matriz de disponibilidad A formadas a partir de
Para evitar oscilaciones numéricas al momento de actualizar los mensajes, se introduce un parámetro de amortiguación
donde
Cabe mencionar que el parámetro de amortiguación presenta un rango de 0 a 1 y mientras más bajo sea el parámetro, la convergencia será más rápida. De manera general y en el código de Affinity Propagation empleado, se utiliza un ajuste por defecto de amortiguación igual a 0.5 para equilibrar la velocidad de convergencia y su capacidad para producir predicciones precisas[24].
2.4. Manifold Learning a través de Multi-Dimensional Scaling (MDS)
Al momento de trabajar con datos de alta dimensión, generalmente surgen problemas para tratarlos e interpretarlos. Precisamente, el Aprendizaje Múltiple o Manifold Learning es una técnica de Aprendizaje Automático cuyo objetivo es reducir la complejidad de los datos de alta dimensionalidad para su representación visual y análisis, conservando la estructura, relaciones y patrones importantes encontrados en los datos. Su hipótesis principal supone que los datos se encuentran en una variedad (Manifold) uniforme, es decir, un espacio geométrico abstracto de baja dimensión incrustado en un espacio de alta dimensión[25].
El Escalamiento Multidimensional o Multi - Dimensional Scaling (MDS) es una técnica de Manifold Learning que busca representar gráficamente un conjunto de objetos o variables en un espacio multidimensional, transformando las relaciones de similitud en distancias entre las variables de tal forma que puedan ser representadas en un espacio de baja dimensión [26]. El algoritmo de MDS empleado a través de la biblioteca Scikit - Learn se basa en la comparación de variables similares, por lo que a medida que las variables sean más similares entre sí, menor será la distancia entre ellas en comparación a la distancia entre otras variables [27].
El objetivo de MDS es encontrar coordenadas de puntos que generen una matriz de distancia euclidiana en la representación de baja dimensión que sea lo más similar posible a la matriz de similitud original S en la representación de alta dimensión. Para lograrlo, el algoritmo emplea un enfoque iterativo que ajusta gradualmente las coordenadas de los puntos en el espacio de baja dimensión hasta que se minimiza la diferencia entre las distancias euclidianas y las distancias en la matriz de Similitud S [26]. Cabe mencionar que el algoritmo de Multi - Dimensional Scaling empleado establece que la representación final tendrá dos dimensiones o 2D.
2.5. Red Gráfica: Grafo de correlaciones Parciales
La Red Gráfica es una representación visual de redes que permite comprender las relaciones potencialmente complejas entre un sistema de variables. Esta herramienta toma un grupo de variables y las asigna a la red representándolas a través de nodos o vértices. Estas variables se encuentran conectadas a través de aristas o arcos que indican su relación. Asimismo, la ausencia de arcos entre dos vértices indica la independencia condicional entre dichas variables. La ubicación en la red de cada variable indica su importancia o influencia en relación con las demás variables[28].
La red grafica aplicada en este trabajo a distintas acciones de empresas utiliza las coordenadas obtenidas mediante el análisis de MDS como entrada y recurre a las correlaciones parciales entre las acciones para determinar aquellas relaciones más significativas. Las acciones se representan mediante nodos en el grafo y la correlación entre ellas se representan a través de arcos cuyo color indica la fuerza de la correlación. Cabe mencionar que los arcos en esta red grafica no presentan flechas de dirección considerando que la correlación entre dos acciones es simétrica. Además, la coloración de los nodos del grafo se realiza con etiquetas de Clusters obtenidas mediante el análisis de Clustering Affinity Propagation. Con ello, se puede visualizar como las variables se agrupan según su correlación parcial y se relacionan dentro de cada uno de los Clusters conformados.
2.6. Herramientas de Machine Learning (ML)
Para utilizar las técnicas de ML, es necesario conocer de lenguajes de programación[13]. Cada lenguaje de programación tiene sus propios criterios y limitaciones, y dependiendo del problema y del contexto en el que se esté trabajando, uno puede ser más adecuado que otro. Entre los lenguajes de computación estadística para análisis más comunes, destaca el lenguaje Python por tener una sintaxis básica similar al inglés, la simplicidad y velocidad con la que se puede escribir un programa vinculada a las líneas de código y el número de sistemas operativos de computadora en las que se puede desarrollar, además de la descarga gratuita del software [14].
Python contiene una gran variedad de librerías que amplía la funcionalidad del lenguaje, además cuenta con funciones o métodos que son utilizados para realizar tareas determinadas o interactuar con otros sistemas, facilitando así la codificación y ahorrando tiempo en el desarrollo. Una API (Application Programming Interface) es una interfaz que permite a los desarrolladores recurrir precisamente a las librerías que reconocen el lenguaje Python [14]. Entre las principales bibliotecas de Python, encontramos a Pandas y Numpy que se utilizan para el análisis y manipulación de datos además de cálculos con operaciones matemáticas y estadísticas. A ello, Matplotlib y Scikit-Learn son dos bibliotecas fundamentales en esta investigación. Por su parte, Matplotlib permite visualizar los datos a través de gráficas personalizadas y Scikit-learn es una librería de aprendizaje automático de código abierto, capaz de proporcionar algoritmos de Aprendizaje Supervisado y Aprendizaje No Supervisado.
2.7. Herramientas Financieras
Para la comparación entre técnicas se buscó aplicar métricas de rentabilidad y riesgo, que incluyen: Retorno Promedio Anualizado, Volatilidad Anualizada, Asimetría, Curtosis, VaR de Cornish-Fisher, VaR Histórico Condicional, índice de Sharpe y Máxima Reducción.
Adicionalmente, se buscó evaluarlas a través del backtesting, que permite comparar el desempeño de cada técnica en un contexto retrospectivo y generar un índice de riqueza que mida el retorno acumulativo de los portafolios generados a lo largo del tiempo. Para ello, recurre a ventanas de tiempo específicas o Rolling Windows para estimar los parámetros de los modelos de ponderación en cada una.
En cada ventana de tiempo, se emplean las estimaciones de los parámetros para calcular las ponderaciones óptimas de los portafolios basándose a una función de ponderación. A partir de estas ponderaciones optimizadas y los retornos correspondientes de cada activo, se calcula el rendimiento de los portafolios para la siguiente ventana específica. Considerando que los pesos óptimos calculados pertenecen a un tramo anterior, la primera ventana de tiempo del periodo total estudiado no contiene suficiente información para calcular los pesos correspondientes. Por lo tanto, el backtestcomienza a calcular los retornos de los portafolios a partir de la segunda ventana de tiempo[29].
3. METODOLOGÍA
El alcance poblacional del estudio se limita a inversores institucionales y particulares con acceso a mercados de renta variable, que tienen la capacidad de invertir en acciones. Se optó por estos mercados debido a su alta volatilidad y exposición a cambios bruscos en el precio de los activos, lo que los convierte en una opción de inversión que ofrece altas ganancias potenciales, pero también un mayor riesgo.
Se delimitó la investigación a empresas del Standard & Poor’s 500 (S & P500), el principal índice bursátil de referencia en Estados Unidos[30], conformado por alrededor de las 500 empresas más grandes del país según su capitalización de mercado [31], es decir, el producto de la cantidad de acciones en circulación de cada empresa y el precio por acción (cotización bursátil). Además de este criterio, para formar parte del índice se consideran otros factores como liquidez, sostenibilidad financiera, grado de internacionalización, volumen de negociación de acciones, tiempo cotizando en bolsa [30].
A5 de marzo de 2023, en total el S & P500 contempla 503 empresas[32]que a su vez se encuentran divididas en 11 sectores dentro del índice, según la Clasificación Industrial Global Estándar (GICS) [33]:
Energía (Energy): Empresas involucradas en la exploración, producción y distribución de petróleo, gas y otros.
Materiales (Materials): Empresas dedicadas a la extracción y procesamiento de productos químicos, materiales de construcción, metales, minerales y empresas de embalaje y papel.
Industrial (Industrials): Empresas que fabrican y distribuyen productos vinculados al transporte y producción de bienes de capital como maquinaria y productos eléctricos empresariales.
Consumo Discrecional (Consumer Discretionary): Empresas que producen bienes de consumo no esenciales como ropa, productos electrónicos y servicios de ocio referidos a hoteles, restaurantes, comercio electrónico, etc. Además, incluye servicios relacionados a la construcción de viviendas.
Productos de Primera Necesidad (Consumer Staples): Empresas que producen bienes de consumo esenciales como alimentos, bebidas y productos de cuidado personal y para el hogar.
Salud (Health Care): Empresas que fabrican productos y prestan servicios vinculados con la atención médica, incluyendo farmacéuticas y empresas de seguros de salud.
Finanzas (Financials): Este sector involucra empresas que prestan servicios financieros como bancos, aseguradoras, empresas de intercambios financieros (mercados) y otras empresas de servicios financieros como corredores de bolsa y administradores de fondos y patrimonios.
Tecnología de la información (Information Technology): Empresas de servicios de software, hardware, fabricantes de semiconductores y equipos de tecnología como computadoras y teléfonos móviles.
Servicios de Comunicación (Communication Services): Empresas de telecomunicaciones y medios de comunicación y entretenimiento.
Servicios de Utilidad Pública (Utilities): Empresas de servicios públicos como electricidad, gas y agua.
Bienes Inmobiliarios (Real State): Empresas que ofrecen servicios vinculados a bienes raíces.
La delimitación temporal de la investigación fue 10 años, a partir del 3 de marzo del 2013 hasta el 5 de marzo del año 2023, ya que se buscó contar con suficiente información histórica que permita realizar un análisis profundo y riguroso que conduzca a conclusiones precisas y confiables, considerando la importancia de los resultados para esta investigación. La razón por la que se escogió un periodo de 10 años en lugar de uno mayor se debe a la cantidad de empresas que se consideraron de manera efectiva en cada submuestra.
La técnica de Clustering Affinity Propagation utilizada en el Análisis Gráfico sugirió que un período de 10 años era óptimo. Al incrementar el número de periodos, las empresas efectivamente consideradas por la técnica disminuían considerablemente, al no presentar suficiente información histórica y tener que ser excluidas del análisis, además de provocar una menor cantidad de Clusters. En el caso de probar con un periodo de estudio de 15 años, la cantidad de empresas eliminadas superaba las 15 empresas en gran parte de las submuestras, mientras que, al reducir el periodo de tiempo en 5 años, la cantidad promedio de empresas eliminadas se reduce a un valor cercano a 4.
3.1. Estructuración de 30 portafolios a partir de la técnica de Clustering
En base los sectores del GICS previamente mencionados, se utilizó código de Python para acceder a Wikipedia y obtener información sobre el nombre de cada una de las empresas que cotizan en el S & P 500, así como su sector según la clasificación GICS. Una vez verificado que la información en Wikipedia incluía los datos de las 503 empresas que pertenecen al índice, se seleccionaron submuestras aleatorias de 50 empresas.
Al considerar el análisis de un conjunto de más de 500 empresas, realizar cálculos y estimaciones directamente sobre todos los datos puede ser una tarea computacionalmente intensiva y demandante en recursos. Además, se suma la dificultad de visualizar de manera efectiva los Clusters y las relaciones de dependencia. Es por ello que se optó por segregar la cantidad de empresas en subconjuntos representativos, seleccionados de manera aleatoria del conjunto completo. De esta forma, las posibles combinaciones entre empresas se realizan de manera imparcial, asegurando que cada empresa tenga la misma probabilidad de ser seleccionada.
A partir de estas submuestras, se utilizó la información pública disponible del S & P 500 a través de la base de datos de Yahoo! Finance para descargar los precios de cierre ajustados por dividendo de la muestra de empresas en el periodo comprendido entre el 3 de marzo de 2013 y el 5 de marzo del año 2023. Considerando el enfoque de muestreo aleatorio aplicado, no era necesario obtener información histórica de todas las empresas del índice. Por esta razón, empleando funciones y la API de Yahoo! Finance, fue posible descargar en tiempo real únicamente la información de las empresas seleccionadas, lo que permitió ahorrar tiempo y recursos computacionales.
La estimación de los parámetros de retorno esperado y matriz de covarianzas necesarios se realizó en base a la submuestra seleccionada de 10 años. A pesar de que se escogió trabajar con datos de periodicidad semanal, se descargó información histórica diaria. Esto se debe a que, en periodos más amplios, la ocurrencia de eventos que ocasionan fluctuaciones significativas en los precios de las acciones puede no ser vista en el promedio, lo que reduciría la precisión de las estimaciones [34]. Posteriormente, se procesaron los datos históricos diarios para obtener los retornos semanales de las empresas de la submuestra.
La razón de trabajar con retornos semanales radica en la periodicidad de la tasa libre de riesgo. Considerando que esta investigación involucra un análisis de inversión en acciones que cotizan en bolsas norteamericanas, se decidió utilizar la tasa de los bonos del Tesoro Estadounidense a 3 meses. La T-Bill a 3 meses se prefiere como tasa libre de riesgo debido a su sensibilidad a las condiciones actuales del mercado, siendo más precisa que una Letra del Tesoro de mayor plazo. Esta sensibilidad es crucial al comparar diferentes estrategias de inversión en un esquema retrospectivo o backtesting. Cuando se utilizan ventanas de tiempo específicas, se estiman los parámetros del modelo en cada ventana, y la sensibilidad se refleja en la capacidad del modelo para adaptarse a las condiciones cambiantes del mercado a medida que avanza el tiempo.
La información de esta letra del Tesoro es publicada de manera semanal por la Reserva Federal de Estados Unidos a través de la página de los Datos Económicos de la Reserva Federal (FRED), y corresponde al promedio de las tasas diarias de las letras. Tomando en cuenta que los retornos diarios de la tasa libre de riesgo no se distribuyen de manera uniforme a lo largo de la semana debido a que las transacciones financieras que generan estas tasas no se realizan los fines de semana ni días festivos, la transformación de las tasas semanales a diarias no capturaría las fluctuaciones reales. Por esta razón, resultó más apropiado trabajar directamente con tasas de periodicidad semanal, considerando además que Python es capaz de manejar grandes cantidades de datos.
Al transformar los precios de cierre de acciones diarios a retornos semanales, se utilizó la función “resample” dentro de Python, que por defecto está configurada para que el día de cierre sea el domingo. Dado que la tasa libre de riesgo utiliza el viernes como día de cierre, fue necesario ajustar dicha tasa para convertir los datos a la misma frecuencia semanal.
A partir de este punto, se aplicaron las tres técnicas de Aprendizaje No Supervisado mencionadas previamente a la submuestra seleccionada: Graphical Lasso, Clustering Affinity Propagation y Multi-Dimensional Scaling, utilizando una función de Análisis Gráfico definida. Una vez que se ejecutó la función, se obtuvo información sobre la cantidad de empresas analizadas, el número de Clusters obtenidos y las empresas correspondientes a cada Cluster, identificadas mediante tickers o símbolos bursátiles. Además, se generó una red gráfica que mostraba las correlaciones parciales entre las empresas de la muestra y estadísticas resumidas por acción. Entre estadísticas se incluía el índice de Sharpe o Sharpe Ratio.
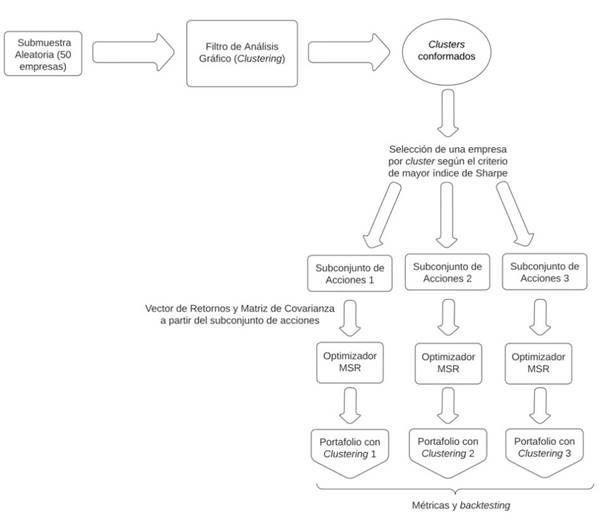
Basándose en el estudio de [35]Karina Marvin de 2015 titulado “Creating Diversified Portfolios Using Cluster Analysis” de la Universidad de Princeton, que propone la creación de carteras diversificadas de acciones de alto rendimiento eligiendo un activo con el índice de Sharpe más alto de cada Cluster para formar parte de un portafolio, se decidió seguir este método de selección de activos considerando que se basa en una métrica de riesgo y retorno de manera simultánea. De esta manera, todos los activos seleccionados se incluyeron nominalmente en el portafolio, es decir, en términos teóricos, pero no necesariamente con una asignación de peso.
Seguidamente, se calculó el vector de retornos esperados anualizados y la matriz de covarianzas a partir de los activos seleccionados para conformar el portafolio. Se utilizó la función de optimización de un portafolio de Máximo Índice de Sharpe (
Este límite máximo de inversión por empresa se deriva de pruebas previas, donde se observó que, al analizar 50 empresas durante un periodo de 10 años, la cantidad mínima de Clusters obtenidos fue de 8 (como se mencionó anteriormente, Affinity Propagation determina automáticamente la cantidad de Clusters). De acuerdo con el método de selección de activos aplicado, esto implicaba que habría 8 empresas con una ponderación individual máxima del 12.5% en el portafolio, con el fin de limitar la exposición a cualquier activo individual. Sin embargo, con la intención de proporcionar un margen más amplio y premiar a las empresas con mejores rendimientos, se decidió establecer un límite máximo de inversión del 15%.
Es importante mencionar que la función de ponderación
Con toda esta información, se visualizó la evolución temporal del rendimiento del portafolio resultante por medio de un índice de riqueza generado a partir de los resultados del backtest y se incluyó un resumen estadístico del desempeño global del portafolio que involucre las medidas de rentabilidad-riesgo antes mencionadas: Retorno Promedio Anualizado, Volatilidad Anualizada, Asimetría, Curtosis, VaRde Cornish-Fisher, VaR Histórico Condicional, índice de Sharpey Máxima Reducción.
Finalmente, se calcularon los pesos de cada activo en la última ventana de tiempo del portafolio para determinar el número de acciones que contribuyeron significativamente al rendimiento general del mismo en el último año (número efectivo de constituyentes).
En base a la submuestra, se crearon dos portafolios adicionales utilizando el mismo método de selección de activos basado en el índice de Sharpe. Sin embargo, para el segundo portafolio se eligió el segundo mejor activo en términos de este criterio, en lugar del mejor. De manera similar, para el tercer portafolio se eligió el tercer mejor activo de cada Cluster. En el caso de que un Cluster en particular tuviese solo una empresa, dicha empresa se incluía en los tres portafolios nominalmente. De manera adicional, en los casos en los que un conglomerado o Cluster contenga dos empresas, no existían inconvenientes en la conformación de los dos primeros portafolios y en el caso del tercero, se volvía a recurrir a la acción con el índice de Sharpe más alto.
Se repitió este proceso para otras nueve submuestras aleatorias de acciones del S & P 500,obteniendo 3 portafolios a partir de cada submuestra y generando un total de 30 portafolios construidos mediante el filtro de Análisis Gráfico y optimizados mediante el modelo de ponderación de Máximo Índice de Sharpe (
Una vez que se armaron los 30 portafolios, se generó una tabla que contiene las estadísticas resumidas de los mismos, ordenados de mayor a menor según el índice de Sharpe. Además, se creó una gráfica utilizando los índices de riqueza previamente generados para cada portafolio, con el objetivo de conocer el retorno acumulado de cada uno a lo largo del tiempo y observar las diferencias y semejanzas entre sus comportamientos. A partir del ranking generado, se seleccionó el mejor portafolio. El procedimiento para la estructuración de un portafolio a partir de la técnica de Clustering Affinity Propagation se resume de la siguiente manera en la Figura 1.
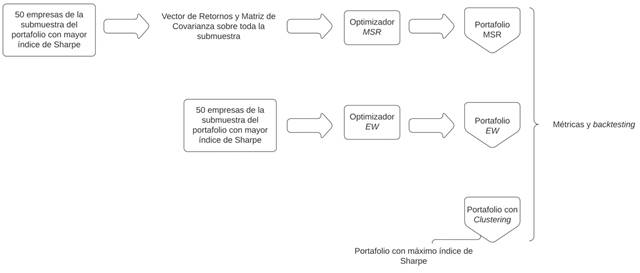
3.2. Comparación con portafolios estructurados a partir de técnicas tradicionales
El portafolio seleccionado con el Máximo Índice de Sharpe se comparó con los modelos de ponderación u optimizadores Máximo Índice de Sharpe (
De manera adicional, para el optimizador
En el siguiente enlace, se puede descargar todo el código en el lenguaje Python de los modelos de aprendizaje automático utilizados, así como las funciones que fueron manejadas: https://github.com/AlejandroPhD/Optimizacion-de-carteras-de-renta-variable-con-machine-learning
4. ANÁLISIS DE RESULTADOS
A partir de los resultados de las métricas presentadas, el resumen global es el siguiente. Los resultados de losportafolios se encuentran ordenados de mayor a menor según el Índice de Sharpe y se presentan en la Tabla 1.
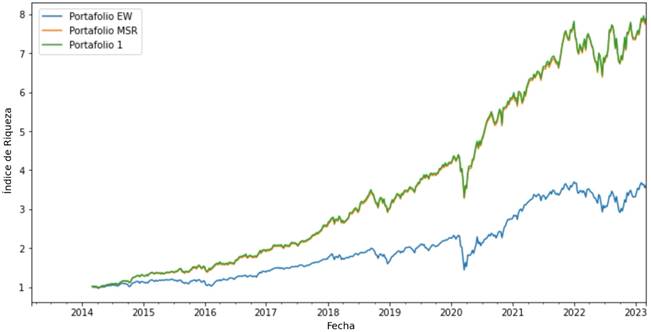
A partir de la Figura 3 presentada a continuación, se puede apreciar la evolución temporal del rendimiento acumulado de 4 portafolios representativos del total de 30 portafolios estructurados a partir de la técnica Clustering Affinity Propagation, mismos que fueron seleccionados como resultado de un análisis por cuartiles. Cada índice de riqueza individual o línea de portafolio comienza en el valor 1 en el periodo inicial, lo que indica que el valor de cada portafolio al comienzo del periodo fue igual a la inversión inicial. Es posible observar que hasta el año 2018, los portafolios presentaron una menor variación entre ellos. Sin embargo, a partir de este punto y a medida que avanzó el tiempo, su comportamiento presentó una mayor divergencia.
En general, los portafolios exhibieron comportamientos similares, pero de magnitud distinta a lo largo del tiempo. Esto significa que si bien los portafolios fueron afectados por los mismos factores o cambios en el mercado (riesgo sistémico), experimentaron diferentes grados de impacto debido a la composición específica de cada uno de ellos. Algunos portafolios tuvieron una mayor capacidad para generar ganancias durante periodos de auge, mientras que otros lograron proteger la inversión durante periodos de baja. Como se puede apreciar en la Figura 3, una de las caídas más pronunciadas de los portafolios se debió a la pandemia del COVID-19, la cual habría provocado pérdidas significativas de valor en los portafolios durante el primer trimestre del año 2020. No obstante, los portafolios presentaron una tendencia creciente a lo largo del periodo de estudio.
TABLA 1 - RESULTADOS DE MEDIDAS DE RETORNO Y RIESGO LOS PORTAFOLIOS ESTRUCTURADOS A PARTIR DE CLUSTERING DURANTE EL PERIODO MARZO 2013 - MARZO 2023
| Retorno Medio Anual (%) | Volatilidad Anual (%) | Asimetría | Curtosis | VaR de Cornish-Fisher (5%) | CVaR Histórico (5%) | Índice de Sharpe | Máxima Reducción (%) | |
|---|---|---|---|---|---|---|---|---|
| Portafolio 1 | 25.66 | 16.77 | (0.23) | 6.14 | 0.03 | 0.05 | 1.46 | (24.96) |
| Portafolio 3 | 26.40 | 18.79 | (0.28) | 6.28 | 0.04 | 0.06 | 1.34 | (27.89) |
| Portafolio 2 | 24.69 | 18.26 | (0.15) | 4.97 | 0.04 | 0.06 | 1.29 | (21.65) |
| Portafolio 19 | 27.71 | 21.44 | (0.17) | 8.01 | 0.04 | 0.06 | 1.24 | (34.04) |
| Poratfolio 7 | 22.10 | 16.93 | (0.43) | 9.45 | 0.03 | 0.05 | 1.24 | (25.71) |
| Portafolio 13 | 20.86 | 16.74 | (0.28) | 7.54 | 0.03 | 0.05 | 1.18 | (25.77) |
| Portafolio 25 | 22.44 | 18.16 | (0.04) | 6.20 | 0.04 | 0.05 | 1.17 | (25.20) |
| Portafolio 8 | 18.66 | 15.25 | (0.26) | 10.12 | 0.03 | 0.05 | 1.15 | (25.22) |
| Portafolio 26 | 21.76 | 18.50 | (0.05) | 5.43 | 0.04 | 0.05 | 1.12 | (24.95) |
| Portafolio 9 | 19.88 | 16.83 | (0.41) | 8.56 | 0.03 | 0.05 | 1.12 | (28.79) |
| Portafolio 22 | 20.66 | 18.08 | (0.15) | 6.77 | 0.04 | 0.06 | 1.08 | (27.30) |
| Portafolio 21 | 24.58 | 21.75 | (0.02) | 6.04 | 0.04 | 0.06 | 1.08 | (31.34) |
| Portafolio 28 | 17.08 | 15.08 | (0.18) | 5.55 | 0.03 | 0.05 | 1.06 | (18.86) |
| Portafolio 24 | 18.59 | 16.89 | (0.20) | 5.92 | 0.03 | 0.05 | 1.04 | (25.09) |
| Portafolio 27 | 21.30 | 19.56 | 0.10 | 6.33 | 0.04 | 0.06 | 1.03 | (27.64) |
| Portafolio 15 | 21.20 | 19.70 | (0.34) | 5.92 | 0.04 | 0.06 | 1.02 | (28.32) |
| Portafolio 4 | 19.49 | 17.95 | (0.53) | 11.42 | 0.04 | 0.06 | 1.02 | (31.85) |
| Portafolio 20 | 23.01 | 21.70 | (0.04) | 5.95 | 0.04 | 0.06 | 1.01 | (32.37) |
| Portafolio 16 | 16.87 | 15.72 | (0.24) | 4.74 | 0.03 | 0.05 | 1.00 | (16.53) |
| Portafolio 23 | 17.88 | 17.04 | (0.25) | 5.89 | 0.04 | 0.05 | 0.99 | (26.71) |
| Portafolio 14 | 17.34 | 17.29 | (0.29) | 7.11 | 0.04 | 0.05 | 0.94 | (28.39) |
| Portafolio 30 | 15.17 | 14.97 | (0.35) | 6.15 | 0.03 | 0.05 | 0.94 | (20.81) |
| Portafolio 18 | 17.90 | 18.08 | 0.01 | 3.99 | 0.04 | 0.05 | 0.93 | (18.03) |
| Portafolio 5 | 17.93 | 18.25 | (0.53) | 10.38 | 0.04 | 0.06 | 0.92 | (30.49) |
| Portafolio 17 | 14.04 | 15.75 | (0.47) | 4.62 | 0.04 | 0.05 | 0.82 | (18.72) |
| Portafolio 10 | 16.42 | 19.26 | (0.13) | 6.93 | 0.04 | 0.06 | 0.80 | (31.42) |
| Portafolio 29 | 12.95 | 15.21 | (0.61) | 7.01 | 0.03 | 0.05 | 0.78 | (24.65) |
| Portafolio 12 | 15.88 | 20.06 | 0.13 | 9.93 | 0.04 | 0.06 | 0.74 | (35.07) |
| Portafolio 6 | 14.47 | 18.47 | (0.65) | 8.41 | 0.04 | 0.06 | 0.73 | (30.50) |
| Portafolio 11 | 14.71 | 19.06 | - | 8.77 | 0.04 | 0.06 | 0.72 | (32.24) |
Fuente: Elaboración propia.

Fuente: Elaboración propia.
Figura 3: Resultados del backtest de los portafolios estructurados a partir de las técnicas de Machine Learning
4.1. Resultados Globales de las Técnicas Tradicionales
Si al análisis de los 30 portafolios estructurados a través de Clustering, añadimos los 6 portafolios conformados a partir de los modelos de ponderación
Por el contrario, los portafolios igualmente ponderados conformados a partir de las submuestras del portafolio 1, 19 y 7, presentaron en términos generales, un desempeño notablemente inferior al de los demás y es por esa razón que ocupan las posiciones más bajas del ranking, con el portafolio igualmente ponderado conformado a partir de la submuestra 7 (portafolio 19) como el peor según el índice de Sharpe. Es importante destacar que, si bien los optimizadores de Máximo Índice de Sharpe alcanzaron posiciones altas, el portafolio con las medidas de retorno y riesgo asumido más consistentes, además de lograr el índice de Sharpe más alto de todos, es el portafolio 1, resultado del filtro previo de Clustering Affinity Propagation y optimización de
TABLA 2 - RESULTADOS DE MEDIDAS DE RETORNO Y RIESGO DE TODOS LOS PORTAFOLIOS DURANTE EL PERIODO MARZO 2013 - MARZO 2023
| Retorno Medio Anual (%) | Volatilidad Anual (%) | Asimetría | Curtosis | VaR de Cornish-Fisher (5%) | CVaR Histórico (5%) | Índice de Sharpe | Máxima Reducción (%) | |
|---|---|---|---|---|---|---|---|---|
| Portafolio 1 | 25.66 | 16.77 | (0.23) | 6.14 | 0.03 | 0.05 | 1.46 | (24.96) |
| PortafolioMSR (P1) | 25.56 | 16.72 | (0.25) | 6.40 | 0.03 | 0.05 | 1.46 | (25.27) |
| PortafolioMSR (P7) | 24.26 | 16.49 | (0.09) | 6.91 | 0.03 | 0.05 | 1.40 | (21.53) |
| Portafolio 3 | 26.40 | 18.79 | (0.28) | 6.28 | 0.04 | 0.06 | 1.34 | (27.89) |
| Portafolio 2 | 24.69 | 18.26 | (0.15) | 4.97 | 0.04 | 0.06 | 1.29 | (21.65) |
| PortafolioMSR (P19) | 27.10 | 20.39 | (0.15) | 6.10 | 0.04 | 0.06 | 1.27 | (29.35) |
| Portafolio 19 | 27.71 | 21.44 | (0.17) | 8.01 | 0.04 | 0.06 | 1.24 | (34.04) |
| Portafolio 7 | 22.10 | 16.93 | (0.43) | 9.45 | 0.03 | 0.05 | 1.24 | (25.71) |
| Portafolio 13 | 20.86 | 16.74 | (0.28) | 7.54 | 0.03 | 0.05 | 1.18 | (25.77) |
| Portafolio 25 | 22.44 | 18.16 | (0.04) | 6.20 | 0.04 | 0.05 | 1.17 | (25.20) |
| Portafolio 8 | 18.66 | 15.25 | (0.26) | 10.12 | 0.03 | 0.05 | 1.15 | (25.22) |
| Portafolio 9 | 19.88 | 16.83 | (0.41) | 8.56 | 0.03 | 0.05 | 1.12 | (28.79) |
| Portafolio 26 | 21.76 | 18.50 | (0.05) | 5.43 | 0.04 | 0.05 | 1.12 | (24.95) |
| Portafolio 22 | 20.66 | 18.08 | (0.15) | 6.77 | 0.04 | 0.06 | 1.08 | (27.30) |
| Portafolio 21 | 24.58 | 21.75 | (0.02) | 6.04 | 0.04 | 0.06 | 1.08 | (31.34) |
| Portafolio 28 | 17.08 | 15.08 | (0.18) | 5.55 | 0.03 | 0.05 | 1.06 | (18.86) |
| Portafolio 24 | 18.59 | 16.89 | (0.20) | 5.92 | 0.03 | 0.05 | 1.04 | (25.09) |
| Portafolio 27 | 21.30 | 19.56 | 0.10 | 6.33 | 0.04 | 0.06 | 1.03 | (27.64) |
| Portafolio 4 | 19.49 | 17.95 | (0.53) | 11.42 | 0.04 | 0.06 | 1.02 | (31.85) |
| Portafolio 15 | 21.20 | 19.70 | (0.34) | 5.92 | 0.04 | 0.06 | 1.02 | (28.32) |
| Portafolio 20 | 23.01 | 21.70 | (0.04) | 5.95 | 0.04 | 0.06 | 1.01 | (32.37) |
| Portafolio 16 | 16.87 | 15.72 | (0.24) | 4.74 | 0.03 | 0.05 | 1.00 | (16.53) |
| Portafolio 23 | 17.88 | 17.04 | (0.25) | 5.89 | 0.04 | 0.05 | 0.99 | (26.71) |
| Portafolio 30 | 15.17 | 14.97 | (0.35) | 6.15 | 0.03 | 0.05 | 0.94 | (20.81) |
| Portafolio 14 | 17.34 | 17.29 | (0.29) | 7.11 | 0.04 | 0.05 | 0.94 | (28.39) |
| Portafolio 18 | 17.90 | 18.08 | 0.01 | 3.99 | 0.04 | 0.05 | 0.93 | (18.03) |
| Portafolio 5 | 17.93 | 18.25 | (0.53) | 10.38 | 0.04 | 0.06 | 0.92 | (30.49) |
| Portafolio 17 | 14.04 | 15.75 | (0.47) | 4.62 | 0.04 | 0.05 | 0.82 | (18.72) |
| Portafolio 10 | 16.42 | 19.26 | (0.13) | 6.93 | 0.04 | 0.06 | 0.80 | (31.42) |
| Portafolio 29 | 12.95 | 15.21 | (0.61) | 7.01 | 0.03 | 0.05 | 0.78 | (24.65) |
| Portafolio 12 | 15.88 | 20.06 | 0.13 | 9.93 | 0.04 | 0.06 | 0.74 | (35.07) |
| PortafolioEW (P7) | 15.86 | 20.06 | (0.25) | 14.82 | 0.04 | 0.06 | 0.74 | (39.06) |
| Portafolio 6 | 14.47 | 18.47 | (0.65) | 8.41 | 0.04 | 0.06 | 0.73 | (30.50) |
| Portafolio 11 | 14.71 | 19.06 | - | 8.77 | 0.04 | 0.06 | 0.72 | (32.24) |
| PortafolioEW (P1) | 15.24 | 20.29 | (0.17) | 12.48 | 0.04 | 0.07 | 0.70 | (38.17) |
| PortafolioEW (P19) | 14.30 | 19.82 | (0.16) | 15.36 | 0.04 | 0.06 | 0.67 | (40.40) |
Fuente: Elaboración propia.
4.2. Resultados Específicos de las técnicas de Machine Learning
4.2.1. Los tres Portafolios con las mejores métricas de rentabilidad y riesgo
Si analizamos los portafolios de manera individual, los resultados encontrados muestran que el portafolio que maximiza las medidas de rentabilidad y riesgo es el Portafolio 1 de Clustering. Este portafolio presenta el índice de Sharpe más alto de todos, con un valor igual a 1.46, lo que indica que logró el mayor retorno en exceso por unidad de riesgo asumido.
En comparación con los demás portafolios sometidos al Clustering, el portafolio 3, obtenido a partir de la misma submuestra, es otro que presenta un índice de Sharpe elevado, pero con un valor significativamente menor de 1.34. Durante el período de tiempo estudiado, el Portafolio 1 mostró una caída máxima del 24.96%, mientras que el Portafolio 3 tuvo una disminución máxima de 27.89%. Esto significa que después de que ambos portafolios alcanzaran un pico del 100% en su valor total respectivamente, la pérdida máxima que sufrió el Portafolio 3 redujo aún más su valor en comparación con el Portafolio 1.
Si bien el Portafolio 3 obtuvo un retorno promedio anualizado superior en 0.74%, mostró una volatilidad anualizada significativamente mayor que la del Portafolio 1 en un 2.02%, lo que no compensa el mayor retorno. Esta mayor variabilidad en los retornos del portafolio 3 hace referencia a una inversión con mayor riesgo asociado. Además, el portafolio 1 presenta la mejor relación entre las medidas de retorno medio anual y volatilidad anual, con valores de 25.66% y 16.77%, respectivamente.
En cuanto al Var de Cornish-Fisher (5%) y Var Condicional Histórico (5%), ambos portafolios mostraron niveles relativamente bajos de riesgo. Para el caso del Portafolio 1, el CVar Histórico presentó un porcentaje de 5%, indicando que dentro del 5% de los peores escenarios posibles, el promedio de pérdidas del portafolio fue del 5% o menos. El Var de Cornish - Fisher obtuvo un valor de 4%, haciendo referencia a que existe una probabilidad del 5% de que el portafolio experimente perdidas iguales o mayores al 4% en un año determinado. El portafolio 3 mostró una leve variación mayor en 1% en ambos casos.
Ambos subconjuntos de empresas presentaron una Asimetría y Curtosis similares, con valores de curtosis mayores a 6 pero menores que el promedio general de 7.02. Esto indica una menor probabilidad, en comparación con otros portafolios, de encontrar retornos muy lejanos de la media y, por tanto, un menor riesgo de cartera para ambos. Además, mostraron coeficientes de asimetría cercanos a cero, pero negativos. Sin embargo, el portafolio 1 obtuvo un valor de Asimetría ligeramente mayor, lo que indica una gran acumulación de retornos en la parte superior de la media y un menor número de retornos en la parte inferior de la distribución.
Asimismo, el portafolio 2 destaca dentro del análisis al presentar una de las pérdidas máximas más bajas de entre el total de los portafolios. Sin embargo, la diferencia con el índice de Sharpe del primer portafolio incrementa aún más que en relación con el portafolio 3, ya que presenta un valor igual a 1.29. El portafolio 2 y 3 mostraron los mismos valores en Var de Cornish-Fisher (5%) y Var Condicional Histórico (5%), indicando también un riesgo ligeramente mayor que el portafolio 1. Si bien en comparación al portafolio 1, presenta un coeficiente de asimetría mayor cercano a cero y una curtosis menor cercana a 5, lo que indica una mayor acumulación de retornos alrededor de la media, también presentó una volatilidad anualizada mayor en 1.49% y una rentabilidad media anualizada menor en casi 1%. Aunque el portafolio 2 presenta una mejora en ciertas medidas de rentabilidad y riesgo analizadas, como Asimetría, Curtosis y Máxima Disminución, en términos generales, el portafolio 1 es aquel que presenta una mayor consistencia en los resultados y logra la mejor relación entre la rentabilidad y el riesgo de la inversión.
4.2.2. Los tres Portafolios con las peores métricas de rentabilidad y riesgo
Entre los portafolios analizados que obtuvieron las peores medidas de rentabilidad y riesgo, destaca el portafolio 12. Este portafolio, junto con los portafolios 11 y 6, presentaron las peores relaciones entre la rentabilidad media anualizada y la volatilidad anualizada, siendo el portafolio 11 el peor en este criterio. A pesar de ello, el portafolio 12 tuvo una relación similar, pero con una volatilidad mayor de poco más del 20%, muy cercana al valor de volatilidad máxima de 21.75%.
A pesar de que el portafolio 6 alcanzó el coeficiente de Asimetría más bajo de todos, igual a-0.65, el coeficiente del portafolio 12 mostró un valor positivo de 0.13, indicando una gran acumulación de retornos negativos y solo algunos positivos. Además, los portafolios 6, 11 y 12 mostraron coeficientes de Curtosis superiores al promedio de 7.02 previamente mencionado. Los valores para los portafolios 6 y 11 fueron menores a 9, mientras que el portafolio 12 tuvo un valor de 9.93. Este coeficiente cercano a 10 hace referencia a una elevada probabilidad de encontrar retornos extremos y, por tanto, un riesgo considerable para la inversión.
Las tres carteras mostraron el mismo valor de Var de Cornish-Fisher (5%) y Var Condicional Histórico (5%) que los portafolios 2 y 3. Si bien el índice de Sharpe más bajo de todos fue de 0.72 correspondiente al portafolio 11, el portafolio 12 alcanzó un valor levemente mayor en un 2%. Finalmente, de entre los 30 portafolios, el portafolio 12 presentó la peor pérdida en Máxima Disminución, con un valor igual a 35.07%, muy por encima del promedio de 26.68%. En términos generales, el análisis de estas métricas muestra que el portafolio 12 proporciona valores vinculados a un nivel de riesgo relativamente alto en relación con su potencial de rentabilidad.
4.3. Análisis Comparativo entre Técnicas Tradicionales y Clustering
El portafolio 1 mostró el mejor desempeño en las medidas de rentabilidad y riesgo analizadas en relación con los modelos de optimización que no fueron sometidos a la técnica Clustering Affinity Propagation. A partir de la Tabla 3, es posible identificar que portafolio 1 tuvo la mejor relación entre retorno medio anual y volatilidad anual, con una volatilidad significativamente menor en comparación con el portafolio igualmente ponderado en casi un 4% y ligeramente mayor que el optimizador de Máximo índice de Sharpe (Portafolio
La Tabla 3 muestra que los coeficientes de Asimetría de estos tres portafolios se situaron cerca de cero, en un rango estrecho entre - 0.25 y - 0.17. La ligera variación se debe a que los portafolios comparten la misma submuestra de empresas, pero difieren en las ponderaciones. Las distribuciones de estos portafolios muestran un sesgo a la izquierda por una mayor acumulación de retornos en la parte superior de la media. El valor de Curtosis de los portafolios presenta un intervalo más amplio, desde 6.14 para el portafolio 1 hasta 12.48 para el Portafolio Igualmente Ponderado. Específicamente, el
El VaR de Cornish-Fisher (5%) y VaR Condicional Histórico (5%) del portafolio 1 y del optimizador de Máximo Índice de Sharpe mostraron los mismos valores de 3% y 5% respectivamente. En cambio, el Portafolio Igualmente Ponderado presentó un nivel de riesgo mayor en ambos casos. Este portafolio mostró un CVaR Histórico del 7%, indicando que dentro del 5% de los peores escenarios posibles, su promedio de pérdidas fue el más alto de todos.
Finalmente, tanto el portafolio 1 como
TABLA 3 - COMPARACIÓN DE TÉCNICAS A PARTIR DEL PORTAFOLIO 1 DE CLUSTERING
| Retorno Medio Anual (%) | Volatilidad Anual (%) | Asimetría | Curtosis | VaR de Cornish-Fisher (5%) | CVaR Histórico (5%) | Índice de Sharpe | MáximaReducción (%) | |
|---|---|---|---|---|---|---|---|---|
| Portafolio EW | 15.24 | 20.29 | (0.17) | 12.48 | 0.04 | 0.07 | 0.70 | (38.17) |
| Portafolio MSR | 25.56 | 16.72 | (0.25) | 6.40 | 0.03 | 0.05 | 1.46 | (25.27) |
| Portafolio 1 | 25.66 | 16.77 | (0.23) | 6.14 | 0.03 | 0.05 | 1.46 | (24.96) |
Fuente: Elaboración propia.
La Figura 4 permite apreciar que el rendimiento acumulado del portafolio 1 y que el optimizador de Máximo Índice de Sharpe fue similar durante todo el periodo de estudio. En este sentido, los índices de riqueza de ambos portafolios parecen estar superpuestos, es decir, uno sobre el otro. En cambio, el Portafolio Igualmente Ponderado siguió un camino distinto mostrando rendimientos acumulados menores en todo el periodo de estudio e incrementando su divergencia respecto a estos dos portafolios a medida que pasa el tiempo.
Ambos portafolios optimizados mediante
4.4. Análisis de los Clusters que forman el Portafolio que Maximiza las métricas
El portafolio 1 se originó a partir de la submuestra aleatoria de 50 acciones de empresas 1. Como se puede apreciar en la Tabla 4, esta submuestra se compone de 1 empresa del sector Energético, 8 empresas del sector de Materiales, 4 de Industriales, 5 empresas que producen bienes no esenciales (Consumo Discrecional), 5 empresas de Productos de Primera Necesidad, 3 empresas que fabrican productos y prestan servicios vinculados a la Salud, 7 empresas que prestan servicios Financieros, 9 empresas dedicadas a la Tecnología de Información, 4 empresas de servicios de Comunicación, 2 de servicios de Utilidad Pública y 2 empresas que ofrecen servicios vinculados a bienes raíces (Bienes Inmobiliarios).
TABLA 4 - COMPOSICIÓN DE LA SUBMUESTRA DE EMPRESAS ALEATORIAS 1
| Ticker | Nombre | Sector |
|---|---|---|
| AMD | AMD | Tecnología de la Información |
| ANSS | Ansys | Tecnología de la Información |
| AON | Aon | Finanzas |
| APA | APA Corporation | Energía |
| AJG | Arthur J. Gallagher & Co. | Finanzas |
| CPB | Campbell Soup Company | Consumo Discrecional |
| CE | Celanese | Materiales |
| CTAS | Cintas | Industrial |
| DHI | D.R. Horton | Consumo Discrecional |
| DISH | Dish Network | Servicios de Comunicación |
| DOW | Dow Inc. | Materiales |
| EMN | Eastman Chemical Company | Materiales |
| ECL | Ecolab | Materiales |
| FDS | FactSet | Finanzas |
| FISV | Fiserv | Tecnología de la Información |
| BEN | Franklin Templeton | Finanzas |
| GILD | Gilead Sciences | Salud |
| HRL | Hormel Foods | Productos de Primera Necesidad |
| K | Kellogg's | Productos de Primera Necesidad |
| KDP | Keurig Dr Pepper | Productos de Primera Necesidad |
| KEY | KeyCorp | Finanzas |
| KEYS | Keysight | Tecnología de la Información |
| LH | LabCorp | Salud |
| LEN | Lennar | Consumo Discrecional |
| LYV | Live Nation Entertainment | Servicios de Comunicación |
| LYB | LyondellBasell | Materiales |
| MTD | Mettler Toledo | Salud |
| MNST | Monster Beverage | Productos de Primera Necesidad |
| NTAP | NetApp | Tecnología de la Información |
| NUE | Nucor | Materiales |
| ORLY | O'Reilly Auto Parts | Consumo Discrecional |
| ODFL | Old Dominion | Industrial |
| PAYC | Paycom | Tecnología de la Información |
| PNC | PNC Financial Services | Finanzas |
| PPG | PPG Industries | Materiales |
| PPL | PPL Corporation | Utilidades |
| PTC | PTC | Tecnología de la Información |
| SRE | Sempra Energy | Utilidades |
| SPG | Simon Property Group | Bienes Raíces |
| STLD | Steel Dynamics | Materiales |
| SYF | Synchrony Financial | Finanzas |
| SNPS | Synopsys | Tecnología de la Información |
| TTWO | Take-Two Interactive | Servicios de Comunicación |
| TXT | Textron | Industrial |
| TSCO | Tractor Supply | Consumo Discrecional |
| URI | United Rentals | Industrial |
| VICI | Vici Properties | Bienes Raíces |
| WBD | Warner Bros. Discovery | Servicios de Comunicación |
| WDC | Western Digital | Tecnología de la Información |
| WYNN | Wynn Resorts | Consumo Discrecional |
Fuente: Elaboración propia.
4.5. Análisis Global de los Clusters formados
No se consideraron para el análisis las empresas Dow Inc., Keysight, Paycom, Synchrony Financial ni Vici Properties, ya que presentaron información faltante o incompleta durante el periodo de estudio. Por lo tanto, los Clusters formados utilizando la técnica de Clustering Affinity Propagation están compuestos por un total de 45 empresas, agrupadas de la siguiente manera:
Cluster 1: AJG, AON, CTAS, FDS, FISV
Cluster 2: AMD
Cluster 3: ANSS, MTD, PTC, SNPS
Cluster 4: CPB, HRL, K
Cluster 5: DHI, LEN
Cluster 6: APA, BEN, CE, ECL, EMN, LYB, NTAP, ODFL, PPG, URI, WDC, WYNN
Cluster 7: GILD
Cluster 8: KDP
Cluster 9: DISH, KEY, LYV, PNC, SPG, TXT, WBD
Cluster 10: MNST
Cluster 11: NUE, STLD
Cluster 12: LH, PPL, SRE
Cluster 13: ORLY, TSCO
Cluster 14: TTWO
De manera más atractiva, se visualiza los Clusters conformados a través de la técnica Multi-Dimensional Scaling (MDS), como ya se mencionó previamente. Esta representación gráfica se muestra en la Figura 5, donde se observa una amplia gama de arcos de color amarillo, que van desde tonalidades suaves hasta las más fuertes, indicando una correlación baja, menor a 0.10. Sin embargo, existen algunas relaciones más significativas que se evidencian mediante arcos de color naranja, especialmente entre nodos específicos como los del Cluster6, que son de color turquesa.
Las relaciones más interesantes emergen a medida que la fuerza de las correlaciones aumenta. En este sentido, se presentan arcos de color rojizo, como el que conecta a las empresas Lyondell Basell (LYB) y Eastman Chemical Company (EMN) en el sector de materiales, o el que vincula a las empresas O'Reilly Auto Parts (ORLY) y Tractor Supply (TSCO) en el sector de consumo discrecional. Además, se destacan tres correlaciones con valores cercanos a 0.35 de fuerza, que corresponden a relaciones entre empresas del sector financiero, de tecnología de la información y de productos de primera necesidad. Estas correlaciones se muestran en arcos de color guindo. Por último, se identifican tres relaciones que destacan por ser las correlaciones parciales más fuertes entre todas las acciones analizadas. La primera corresponde al sector de consumo discrecional, la segunda al sector financiero y la tercera al sector de materiales.
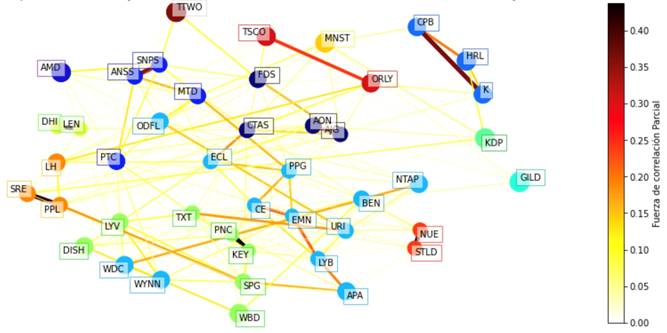
Fuente: Elaboración propia
Figura 5:Red Gráfica de los Clusters conformados y las relaciones entre las empresas de la Submuestra 1 durante el periodo de marzo 2013 - marzo 2023.
Cabe destacar que en los Clusters conformados por las 10 submuestras aleatorias, es común encontrar relaciones más fuertes entre empresas que pertenecen al mismo sector, como en esta submuestra. No obstante, se presentaron excepciones, algunas de las cuales se muestran en las redes gráficas de las siguientes submuestras:
Submuestra 2: La empresa Sysco (SYY) del sector de productos de primera necesidad mostró una correlación parcial de 0.20 con el fabricante de aviones Boeing (BA) del sector industrial, además de pertenecer al mismo Cluster. Otro caso similar dentro de la misma submuestra es la relación entre Crown Castle (CCI) del sector de bienes raíces y American Water Works (AWK), una empresa estadounidense de servicios básicos.
Submuestra 3: Las empresas Mohawk Industries (MHK) y D.R. Horton (DHI), ambas empresas de bienes de consumo no esenciales presentaron una correlación parcial más fuerte con Masco (MAS) del sector industrial queentre ellas mismas, a pesar de formar parte del mismo sector. Las tres empresas están agrupadas en el mismo Cluster.
Submuestra 4: La multinacional Juniper Networks (JNPR) dedicada a sistemas de redes y seguridad mostró una correlación parcial aproximada de 0.20 con la empresa de energía AES Corp. (AES) del sector de servicios de utilidad pública.
Submuestra 5: La Compañía General Motors del sector consumo discrecional y la empresa TE Connectivity del sector tecnológico pertenecen al mismo Cluster.
Submuestra 7: El fabricante de aviones Boeing (BA) mostró una correlación parcial cercana a 0.25 con la compañía de seguros Aflac (AFL), además de que pertenecen al mismo Cluster.
Submuestra 10: La empresa de servicios públicos Xcel Energy (XEL) mostró una correlación cercana a 0.20 con la empresa Welltower (WELL) y con el grupo de Inversión en Activos Inmobiliarios SBA Communications (SBAC), ambas vinculadas a servicios de bienes raíces.
CONCLUSIONES
Se cumplió el objetivo de la investigación en el camino a encontrar el modelo de gestión de portafolio que maximice las medidas de rentabilidad y riesgo. En este sentido, el portafolio que pasó por el filtro previo de Clustering (Análisis Gráfico) y fue sometido al modelo de ponderación de Máximo Índice de Sharpe, denominado portafolio 1, logró ser el que maximiza las medidas, colocándose por encima de técnicas tradicionales como la función de ponderación de
Considerando que el modelo con filtro de Clustering Affinity Propagation tiene el mejor desempeño de todos los portafolios conformados, incluidos los modelos tradicionales presentados, se concluye que las técnicas de Aprendizaje Automático pueden ser aplicadas como una alternativa viable y efectiva para el problema en cuestión. Como se vio en el análisis, esto no indica que estos modelos tengan en todos los casos medidas de rentabilidad y riesgo superiores a los modelos tradicionales, e incluso es necesario considerar que la elección del portafolio depende de las necesidades y preferencias individuales de cada inversor, vinculadas al perfil de riesgo y objetivos de inversión, además del contexto del mercado.
A partir de esta investigación se pretende abrir el espacio para explorar casos particulares y distintos factores que puedan afectar el desempeño de estas técnicas de Aprendizaje Automático, entre ellos, la cantidad de Clusters, métodos de selección de activos, número de portafolios construidos, etc.
Se recomienda el uso de técnicas de Aprendizaje Automático y en particular el Clustering, como base del análisis en esta investigación, debido a su capacidad para identificar patrones y relaciones entre empresas con comportamientos similares, incluso si a primera vista no parecen estar relacionadas por no pertenecer al mismo sector. Como se observó, ciertos patrones se repetían entre algunos sectores, mientras que otros y empresas específicas, tendían a aparecer en su propio Cluster. Al aplicar esta técnica y complementarla con Graphical Lasso y Multi-Dimensional Scaling, se obtuvieron valiosos e innovadores conocimientos que permiten una visión más completa de la realidad, así como identificar o eliminar relaciones que podrían pasar desapercibidas a simple vista y en otro tipo de análisis.
Clustering aporta una perspectiva exploratoria vinculada a generar nuevo conocimiento mientras que el enfoque tradicional de modelos de valoración, análisis fundamental y estadísticas clásicas, proporcionan un marco sólido basado en teorías establecidas. Es por ello, que ambos enfoques pueden complementarse para lograr un panorama más completo a la hora de tomar decisiones.
Adicionalmente, por medio de esta técnica se logró apreciar que por más de que se considere un universo de empresas más amplio como fue el caso de los modelos de ponderación en relación con los portafolios optimizados con filtro de Clustering, esto no garantiza que se consiga una mejora en los resultados de rentabilidad y riesgo. En ello radica la importancia de seleccionar las empresas adecuadas, más allá de la cantidad total de activos.
Hoy en día, la Inteligencia Artificial es una tecnología que ha transformado muchos sectores, incluso el financiero. Resulta esencial adaptarse a los nuevos contextos que surgen a medida que la Inteligencia Artificial se acerca a nuevas aplicaciones para mejorar la toma de decisiones. Aún más cuando su uso permite reducir costos, incrementar niveles de eficiencia y como se evidenció en esta investigación, obtener un mayor conocimiento y comprensión de los mercados de renta variable además de lograr un portafolio con el mejor desempeño financiero.
Entre las sugerencias y propuestas para las futuras investigaciones, se encuentran:
Utilizar estimadores de retorno y riesgo basados en modelos econométricos en lugar de depender únicamente en estimaciones basadas en la muestra. Los estimadores basados en datos históricos pueden ser sensibles a cambios en la distribución de los datos y a la presencia de valores atípicos. En contraste, los modelos econométricos como las estadísticas bayesianas, modelos factoriales e incluso modelos que permiten extraer retornos esperados implícitos a partir de ingeniería inversa como el Modelo Black - Litterman, pueden mejorar la precisión y robustez de las estimaciones de riesgo y retorno.
En esta investigación se utilizaron algunos modelos de ponderación para construir portafolios y comparar modelos con la premisa de identificar si las técnicas de Aprendizaje Automático pueden superar a modelos tradicionales como el de Markowitz. Sin embargo, es importante mencionar que existen muchos otros modelos que pueden utilizarse, como el portafolio ponderado por su capitalización, que asigna una mayor ponderación a las empresas de mayor capitalización bursátil; el optimizador de Black-Litterman, que combina las expectativas del inversor con la información de mercado para generar una cartera óptima; y el modelo de ponderación Equal Risk Contribution (ERC), que se basa en el concepto de que cada activo contribuya por igual al riesgo total de la cartera.
Aplicar distintos métodos para determinar la cantidad optima de portafolios a partir una muestra con un número definido de Clusters. De manera predeterminada, en esta investigación se generaron 3 portafolios por cada submuestra de Clusters. Sin embargo, existen diversos métodos para encontrar la cantidad óptima de portafolios, algunos de los cuales se basan en la maximización o minimización de la distancia entre los datos, como el método del Codo o el método de la Silueta.
Además de utilizar el índice de Sharpe como medida para seleccionar los activos dentro de cada Cluster para construir portafolios, se pueden considerar otras medidas de rentabilidad y riesgo, tanto de las que se emplearon en esta investigación como de otras que se ajusten a los objetivos específicos. Es importante destacar que la selección de activos y la proporción puede variar según el enfoque. Otros métodos también involucran el análisis fundamental de cada empresa relacionado a ratios de liquidez, rentabilidad, endeudamiento, eficiencia o de mercado.

