











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. INTRODUCCIÓN
La diversificación de cartera tiene una larga historia, como lo señalan [1] y [2], la diversificación de cartera es una herramienta de inversión útil que puede reducir el riesgo en los mercados financieros. Evans y Archer [3] muestran empíricamente que el riesgo de una cartera se reduce efectivamente al aumentar el número de acciones, mejorando de esta manera la relación riesgo rendimiento.
Sin embargo, las crisis financieras y las consecuentes caídas del mercado de valores plantean interrogantes sobre la utilidad práctica de la teoría de portafolios. Incluso los inversores con una cartera bien diversificada, contrariamente a lo esperado, han sufrido grandes pérdidas provocadas por caídas del mercado, como la crisis financiera asiática de 1997 y la crisis financiera mundial de 2008 [4].
El estudio de por qué muchos mercados financieros mundiales colapsan simultáneamente es de vital importancia [5], aspecto que nos lleva a plantear la siguiente pregunta de investigación ¿existen mercados financieros que tienen una respuesta diferenciada en los periodos de crisis financiera?
Por otro lado, desde la década de los 90 el análisis de los mercados financieros a través de la aplicación de la ciencia de datos y las técnicas de aprendizaje automático (Machine Learning ML) se ha convertido en una poderosa herramienta para el estudio de diferentes fenómenos presentes en los mercados financieros, precisamente, las firmas de inversión utilizan cada vez más la tecnología en cada paso de la cadena de valor de la gestión de inversiones, para mejorar su comprensión de sus clientes hasta descubrir nuevas fuentes de rentabilidad y ejecutar operaciones de manera más eficiente [6].
Bajo ese contexto, el objetivo de la presente investigación fue analizar el comportamiento de los mercados financieros frente a situaciones de crisis, para lo cual, se estudiaron los rendimientos mensuales de 15 índices bursátiles de renta variable y se aplicaron métodos de aprendizaje automático que permitieron agrupar a los mercados en función a sus respuestas a los eventos identificados.
Para alcanzar este objetivo el trabajo fue organizado en cuatro partes: luego de la introducción en la segunda parte se desarrolla el marco teórico, donde se exponen conceptos sobre el estudio de eventos, aprendizaje automático y se presentan investigaciones realizadas en los mercados financieros con aplicaciones de ML, en la tercera parte se desarrolla la aplicación del estudio, primero se identifican los eventos de crisis, luego se describe la respuesta de los mercados financieros, se presenta el caso de la crisis entre Rusia y Ucrania, a continuación, se desarrolla la aplicación de métodos de aprendizaje automático para agrupar los mercados financieros, finalmente en la cuarta parte se exponen las conclusiones de la investigación.
2. MARCO TEÓRICO
2.1. Estudio de Eventos
Con frecuencia se pide a los analistas financieros que midan los efectos de un evento económico sobre el valor de las empresas; para lo cual se puede construir una medida del impacto del evento utilizando los precios de los valores observados durante un periodo de tiempo determinado. La utilidad de tales estudios proviene del hecho de que, dada la racionalidad del mercado, los efectos de un evento se deberían reflejar inmediatamente en los precios de los valores, aunque la dirección del impacto (positivo o negativo) puede ser diferente.
Las características de los eventos a ser estudiados pueden ser muy diversas, por ejemplo, se encuentran estudios sobre la partición de acciones (stock splits), fusiones y adquisiciones, crisis financieras e incluso la reacción de los mercados financieros a los conflictos armados internacionales; en esa línea, Schneider y Troeger [7] presentaron un estudio sobre la guerra y la economía mundial, el estudio realizado para el periodo de 1990 a 2000 tomo como referencia los índices de referencia CAC, Dow Jones y FTSE1, los resultados mostraron que los conflictos afectaron las interacciones en el núcleo de los mercados financieros occidentales en forma negativa. En el estudio se formularon y contrastaron las siguientes tres hipótesis: i) Los mercados financieros reaccionan negativamente a la intensificación de un conflicto si esperan que el conflicto sea costoso para la economía ii) Los mítines de guerra son probables en conflictos que siguen la lógica de la disuasión y en los que los principales oponentes pueden identificarse fácilmente; finalmente iii) los eventos conflictivos severos tienen un impacto negativo en el mercado de valores y aumentan la volatilidad del mercado.
Metodológicamente, el estudio de eventos puede ser abordado desde la perspectiva de la hipótesis de los mercados eficientes planteada por Fama [8] la cual, establece que los precios de los títulos valores reflejan completamente toda la información disponible (pública y privada). Una precondición necesaria en este concepto es que la información y los costos de transacción, es decir, el costo de obtener los precios para reflejar la información, siempre deberán ser iguales a cero. Una versión débil de la hipótesis señala que los precios reflejarán la información al punto en el cual los beneficios marginales de actuar sobre dicha información (las ganancias que se pueden obtener) no excederán su costo marginal [9].
Originalmente los trabajos de investigación dividieron el análisis de la eficiencia de mercado en tres categorías, conocidas como las formas de la eficiencia de mercado [8]: i) eficiencia débil, ii) eficiencia semi fuerte y iii) la eficiencia fuerte.
Sin embargo, cada una de las tres formas de eficiencia fueron replanteadas en función al tipo de pruebas que son utilizadas para medirlas [10] 2:
En lugar de test de eficiencia débil, se encuentran las pruebas de predictibilidad de los rendimientos, que además incluyen los trabajos sobre pronósticos en los rendimientos con variables tales como rendimientos por dividendos y tasas de interés.
Considerando que la eficiencia de mercado y los problemas en los precios de equilibrio son inseparables, la discusión de la predictibilidad además considera la predictibilidad de corte transversal en los rendimientos, es decir, pruebas en los modelos de valoración de activos y las anomalías descubiertas mediante los test.
También se realizan estudios sobre la evidencia de comportamientos estacionales en los rendimientos (por ejemplo, efecto enero), además de los estudios que hacen énfasis en la volatilidad de los títulos.
Para la segunda categoría, en lugar de los test de eficiencia en forma semi fuerte, se plantean los estudios de eventos.
En lugar de los estudios de eficiencia fuerte, se utilizan los test de información privada.
Aunque existe importante evidencia que demuestra que los mercados son eficientes, como se señala en [11] también se han reportado una serie de ineficiencias potenciales, las cuales son denominadas anomalías de mercado. Estas anomalías, si son persistentes, son tratadas como excepciones a la noción de eficiencia del mercado, en otras palabras, una anomalía de mercado ocurre si el cambio en el precio de un activo o título valor no puede relacionarse directamente con la información actual y relevante que es conocida en el mercado.
Para el caso de los estudios de eventos, tomando como referencia los trabajos de Mackinlay [12] y Bowman [13], los pasos para realizar esta evaluación son los siguientes:
Identificar y definir el evento de interés, determinar el periodo de tiempo a lo largo del cual los precios de las acciones serán examinados.
Modelar la reacción del precio del valor, esto generalmente implica formular un modelo de expectativas condicionado al evento.
Medir los rendimientos anormales, que es la diferencia entre los rendimientos actuales en el periodo de análisis menos los rendimientos normales. Los rendimientos normales son aquellos que no se encuentran condicionados al evento en cuestión.
Analizar los resultados. Cuando sea posible, esto se hará con pruebas estadísticas de significación diseñadas para una hipótesis nula establecida.
2.2. Aprendizaje Automático (Machine Learning) y Modelos de Clasificación
Tanto los enfoques estadísticos como las técnicas de aprendizaje automático (ML) analizan un conjunto de datos con el propósito de revelar algún proceso subyacente; sin embargo, difieren en sus supuestos, terminología y técnicas. Los enfoques estadísticos se basan en suposiciones fundamentales y modelos explícitos de estructura, como muestras observadas que se supone que se extraen de una distribución de probabilidad subyacente específica. Estos supuestos restrictivos a priori pueden fallar en la realidad.
Por el contrario, el aprendizaje automático busca extraer conocimiento de grandes cantidades de datos con menos restricciones. El objetivo de los algoritmos de aprendizaje automático es automatizar los procesos de toma de decisiones al generalizar (es decir, "aprender") a partir de ejemplos conocidos para determinar una estructura subyacente en los datos. El énfasis está en la capacidad del algoritmo para generar estructuras o predicciones a partir de datos sin ayuda humana. Una forma elemental de pensar en los algoritmos de ML es "encontrar el patrón, aplicar el patrón" [6].
Entre sus principales ventajas se tienen [6]:
Las técnicas de aprendizaje automático son más capaces que los enfoques estadísticos (como la regresión lineal) para manejar problemas con muchas variables (alta dimensionalidad) o con un alto grado de no linealidad.
Los algoritmos de ML son particularmente buenos para detectar cambios, incluso en sistemas altamente no lineales, porque pueden detectar las condiciones previas de la ruptura de un modelo o anticipar la probabilidad de un cambio de régimen.
El aprendizaje automático se divide ampliamente en tres clases distintas de técnicas: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje profundo/aprendizaje de refuerzo.
2.2.1. Aprendizaje supervisado
El aprendizaje supervisado involucra algoritmos de ML que infieren patrones entre un conjunto de entradas (las X) y la salida deseada (Y). Luego, el patrón inferido se usa para mapear un conjunto de entrada dado en una salida predicha. El aprendizaje supervisado requiere un conjunto de datos etiquetado, uno que contenga conjuntos coincidentes de entradas observadas y la salida asociada. La aplicación del algoritmo ML a este conjunto de datos para inferir el patrón entre las entradas y la salida se denomina "entrenamiento" del algoritmo. Una vez que se ha entrenado el algoritmo, el patrón inferido se puede usar para predecir los valores de salida en función de las nuevas entradas (es decir, las que no están en el conjunto de datos de entrenamiento) [6].
En el aprendizaje automático supervisado, la variable dependiente (Y) es el objetivo, y las variables independientes (X) se conocen como características. Los datos etiquetados (conjunto de datos de entrenamiento) se utilizan para entrenar el algoritmo de aprendizaje automático supervisado para inferir una regla de predicción basada en patrones.
El aprendizaje supervisado se puede dividir en dos categorías: modelos de regresión y modelos de clasificación, y la distinción entre ellos está determinada por la naturaleza de la variable objetivo (Y). Si la variable objetivo es continua, entonces la tarea es de regresión. Si la variable objetivo es categórica u ordinal (es decir, una categoría clasificada), entonces es un problema de clasificación. La regresión y la clasificación utilizan diferentes técnicas de ML [6].
La clasificación se centra en clasificar las observaciones en distintas categorías. En un problema de regresión, cuando la variable dependiente (objetivo) es categórica, el modelo que relaciona el resultado con las variables independientes (características) se denomina "clasificador".
2.2.2. Aprendizaje no supervisado
El aprendizaje no supervisado es aprendizaje automático que no utiliza datos etiquetados. Más formalmente, en el aprendizaje no supervisado, se tienen entradas (X) que se utilizan para el análisis sin que se suministre ningún objetivo (Y). En el aprendizaje no supervisado, debido a que el algoritmo ML no recibe datos de entrenamiento etiquetados, el algoritmo busca descubrir la estructura dentro de los propios datos. Como tal, el aprendizaje no supervisado es útil para explorar nuevos conjuntos de datos porque puede proporcionar a los expertos humanos información sobre un conjunto de datos demasiado grande o complejo para visualizar [6].
Dos tipos importantes de problemas que se adaptan bien al aprendizaje automático no supervisado son la reducción de la dimensión de los datos y la clasificación de los datos en grupos.
La reducción de dimensiones se enfoca en reducir el número de características mientras conserva la variación entre las observaciones para preservar la información contenida en esa variación. La reducción de dimensiones puede tener varios propósitos. Puede aplicarse a datos con muchas características para producir una representación de menor dimensión (es decir, con menos características). La reducción de dimensiones también se utiliza en muchas aplicaciones de gestión de riesgos e inversiones cuantitativas en las que es fundamental identificar los factores más predictivos que subyacen a los movimientos de los precios de los activos [6].
La agrupación se centra en clasificar las observaciones en grupos (conglomerados) de modo que las observaciones en el mismo conglomerado se parezcan más entre sí que con las observaciones en otros conglomerados. Los grupos se forman en base a un conjunto de criterios que pueden o no especificarse (como el número de grupos). Los gestores de activos han utilizado la agrupación para clasificar las empresas basadas en sus fundamentos (p. ej., en función de los datos de sus estados financieros o características corporativas) en lugar de agrupaciones convencionales (p. ej., en función de sectores o países) [6].
2.2.3. Agrupación en clústeres
La agrupación en clústeres es otro tipo de aprendizaje automático no supervisado, que se utiliza para organizar puntos de datos en grupos similares llamados clústeres. Un grupo contiene un subconjunto de observaciones del conjunto de datos de modo que todas las observaciones dentro del mismo grupo se consideran "similares". El objetivo es encontrar un buen agrupamiento de los datos, lo que significa que las observaciones dentro de cada conglomerado son similares o cercanas entre sí (una propiedad conocida como cohesión) y las observaciones en dos conglomerados diferentes están lo más alejadas entre sí o son lo más diferentes posible (una propiedad conocida como separación) [6].
El agrupamiento jerárquico es un procedimiento iterativo que se utiliza para construir una jerarquía de clústeres. En el agrupamiento de k-medias, el algoritmo segmenta los datos en un número predeterminado de grupos; no existe una relación definida entre los grupos resultantes. En el agrupamiento jerárquico, sin embargo, los algoritmos crean rondas intermedias de grupos de tamaño creciente (en "aglomerativo") o decreciente (en "divisivo") hasta que se alcanza un agrupamiento final. El proceso crea relaciones entre las rondas de grupos, como sugiere la palabra "jerárquica". Aunque computacionalmente más intensivo que el agrupamiento de k-medias, el agrupamiento jerárquico tiene la ventaja de permitir que el analista de inversiones examine segmentaciones alternativas de datos de diferente granularidad antes de decidir cuál usar [6].
Un tipo de diagrama de árbol para visualizar un análisis de conglomerados jerárquicos se conoce como dendrograma, que destaca las relaciones jerárquicas entre los conglomerados.
Los cúmulos están representados por una línea horizontal, el arco, que conecta dos líneas verticales, llamadas dendritas, donde la altura de cada arco representa la distancia entre los dos cúmulos considerados. Las dendritas más cortas representan una distancia más corta (y una mayor similitud) entre grupos. Las líneas discontinuas horizontales que cortan las dendritas muestran el número de grupos en los que se dividen los datos en cada etapa [6].
2.2.4. Investigaciones sobre agrupación de activos financieros mediante modelos de ML
Como alternativa para la diversificación de portafolios Nanda, Mahanty y Tiwari [14] presentaron un enfoque de minería de datos para la clasificación de acciones en clústeres. Después de la clasificación, las acciones podrían seleccionarse de estos grupos para construir una cartera, el estudio, concluye que los resultados presentados cumplieron con el criterio de minimizar el riesgo mediante la diversificación de una cartera.
Gupta y Sharma [15] mostraron que es posible obtener resultados eficientes en la predicción de los mercados de acciones mediante la aplicación de clasificación por clústeres.
Como señalan Aghabozorgi y Wah [16] un sistema automático de categorización bursátil sería invaluable para los inversores individuales y expertos financieros, ya que les brindaría la oportunidad de predecir los cambios en el precio de las acciones de una empresa con respecto a otras empresas. En los últimos años, la agrupación o clústeres de todas las empresas en los mercados de valores en función de sus similitudes se ha convertido cada vez más en un esquema común, como el análisis realizado por Chen et al. [17] para el mercado de valores en China; sin embargo, para realizar una clasificación más adecuada se debe reconocer el problema de alta dimensionalidad. En ese contexto, Aghabozorgi y Wah [1] propusieron un novedoso modelo de agrupamiento de tres fases para categorizar empresas en función de la similitud en la forma de sus mercados bursátiles. Los resultados mostraron que este enfoque tiene un rendimiento superior en eficiencia y eficacia en comparación con los algoritmos de agrupamiento convencionales existentes.
Kocheturov et al.[18] estudiaron la dinámica de las estructuras de clúster en los mercados financieros de Estados Unidos y Suecia. Los resultados mostraron que durante los períodos de crisis financiera mundial como la crisis de las hipotecas sub-prime, la crisis de las punto-com y la crisis bancaria en Suecia, estas estructuras de clúster fueron más estables, mientras que en períodos de tiempo que no son de crisis, las estructuras de los clústeres cambiaron de manera más caótica. Por lo tanto, concluyen que una estabilidad creciente de una estructura de clúster de gráficos de mercado obtenida a través del método PMP (P-Median Problem) podría usarse como un indicador de una crisis venidera.
En otra investigación Luz et al.[19] demostraron que la aplicación de un algoritmo de agrupación jerárquica (clustering) para la construcción de un portafolio dinámico alcanzó un retorno de inversión superior a una cartera de Markowitz. Los resultados se explican porque la estrategia aplicada seleccionó mejor el portafolio de inversión, considerando el efecto de impulso y la predicción de las tendencias del mercado.
El trabajo de Chatzis et al. [20] se enfocó en realizar un pronóstico de las crisis en los mercados financieros mediante la aplicación de técnicas de machine learning y deep learning, su trabajo contribuyó al debate sobre la naturaleza y las características de los canales de propagación de eventos de crisis en los mercados bursátiles internacionales, específicamente, investigaron los mecanismos de transmisión entre los mercados de valores junto con los efectos de los mercados de bonos y divisas. El enfoque desarrollado combinó diferentes algoritmos de aprendizaje automático que se presentan con datos diarios de acciones, bonos y divisas de 39 países que cubren un amplio espectro de economías. Específicamente, utilizaron las siguientes técnicas deep learning y boosting que incluyen: árboles de clasificación, máquinas de vectores de soporte, bosques aleatorios, redes neuronales, aumento de gradiente extremo y redes neuronales profundas. Las variables independientes incluidas tuvieron información sobre los dos canales de vinculación fundamentales a través de los cuales se puede iniciar el contagio financiero: rendimientos y volatilidad. Entre las conclusiones más importantes se destacan:
Los resultados experimentales proporcionan una fuerte evidencia de que las crisis del mercado de valores tienden a exhibir persistencia.
También encontraron evidencia significativa de interdependencia y efectos de contagio cruzado entre los mercados de acciones, bonos y divisas.
Finalmente, mostraron que el uso de redes neuronales profundas aumenta significativamente la precisión de la clasificación, al tiempo que ofrece una forma sólida de crear una herramienta de alerta temprana sistémica global. Por lo tanto, los bancos centrales pueden utilizar estas herramientas para ajustar tempranamente su política monetaria, para garantizar la estabilidad financiera.
3. APLICACIÓN - ANÁLISIS DE ÍNDICES BURSÁTILES
3.1. Identificación de Eventos
Los eventos identificados se desarrollan desde enero del año 2007 hasta julio del año 2022, haciendo un total de quince años y siete meses de análisis. En la Tabla 1 se presenta un detalle de la línea de tiempo de los eventos de crisis más importantes.
TABLA 1 - LÍNEA DE TIEMPO DE LOS EVENTOS DE CRISIS PARA EL PERIODO 2007 - 2022
| Periodo | Evento |
| 2007 a 2008 | La crisis financiera de 2007 a 2008, también conocida como la crisis de las hipotecas de alto riesgo, fue el resultado del colapso del mercado inmobiliario de EE. UU. y, en última instancia, condujo a una gran recesión. Más de dos años antes de la crisis, la Reserva Federal había estado elevando constantemente la tasa de los fondos federales del 1,25 % al 5,25 %,15 lo que condujo a un número cada vez mayor de prestatarios de alto riesgo que incumplían los pagos de los préstamos. Para 2008, el Departamento del Tesoro de EE. UU. tuvo que nacionalizar a los dos principales prestamistas hipotecarios del país, Fannie Mae y Freddie Mac, para evitar su colapso. Más tarde ese año, el banco de inversión Lehman Brothers presentó la mayor quiebra en la historia de los EE. UU. y, en octubre de 2008, el gobierno de los EE. UU. aprobó un paquete de rescate para proteger el sistema financiero de los EE. UU. y promover el crecimiento económico. |
| 2011 | El 8 de agosto de 2011, los mercados bursátiles de EE. UU. y del mundo cayeron debido a que el debilitamiento de la economía de EE. UU. y una crisis de deuda cada vez mayor en Europa disminuyeron la confianza de los inversionistas. Antes de este evento, EE. UU. recibió una rebaja crediticia de Standard & Poor's (S & P) por primera vez en la historia en medio de un estancamiento anterior del techo de deuda. Aunque finalmente se resolvió el estancamiento político, S & P consideró que el acuerdo no alcanzaba lo que se necesitaba para reparar las finanzas de la nación. |
| 2015 a 2016 | La caída del mercado de valores de 2015 a 2016 fue una liquidación masiva de ventas que tuvo lugar durante un período de un año a partir de junio de 2015. En los EE. UU., el DJIA cayó 530,94, o aproximadamente un 3,1 %, el 21 de agosto de 2015. La volatilidad del mercado comenzó inicialmente en China cuando a los inversionistas vendieron acciones a nivel mundial en medio de una serie de circunstancias económicas volátiles, incluido el fin de las medidas de política monetaria (quantitative easing) en los Estados Unidos, una caída en los precios del petróleo, el impago de la deuda griega y el voto Brexit. |
| 2020 | El desplome del mercado de valores a causa del coronavirus de 2020 es el desplome más reciente de EE. UU., que se produjo debido a las ventas de pánico tras el inicio de la pandemia de COVID-19. El 16 de marzo, la caída de los precios de las acciones fue tan repentina y dramática que se desencadenaron múltiples interrupciones en las operaciones en un solo día. Desde el 12 de febrero hasta el 23 de marzo, el DJIA perdió el 37 % de su valor y las operaciones en la NYSE se suspendieron varias veces. El mercado de valores se recuperó y el 18 de agosto, el S & P 500 alcanzó máximos históricos.19 El 24 de noviembre de 2020, el DJIA superó los 30 000 puntos por primera vez en la historia. |
| 2022 | Invasión de Rusia a Ucrania, en febrero de 2022 Rusia inició una invasión a Ucrania el conflicto se extiende hasta la fecha, durante el desarrollo del conflicto, a partir del 24 de febrero de 2022 y hasta junio de 2022, se aplicaron 83 eventos de sanciones a Rusia, por parte de 17 países. Un segundo factor está relacionado con las condiciones económicas en los Estados Unidos y varios países en el Mundo, resultantes de la pandemia del COVID-19. Cabe mencionar que las medidas de confinamiento mundial provocaron la caída repentina de la actividad económica, para lo cual, se tuvo que adoptar medidas urgentes de estímulo de la demanda con expansiones fiscales y monetarias que generaron un aumento considerable de la masa monetaria [21]; este incremento de la liquidez trajo como consecuencia el incremento en los niveles de inflación a partir del año 2021, en el caso de los Estados Unidos llegando a superar el 8% a febrero de 2022 [22]. Como describen [23] en marzo de 2022 la Reserva Federal (FED) resolvió tomar medidas que no se veían desde el año 2018, incrementando la tasa de interés en 25 puntos básicos, sin embargo, esta medida fue revisada a la alza el mes de mayo donde la FED decidió incrementar las tasas en 50 puntos básicos; nuevamente el mes de junio la FED elevó las tasas de interés en 75 puntos básicos, siendo esta última su medida más agresiva hasta el momento para tratar de controlar la inflación. |
Fuente: Elaboración propia con información obtenida de [24].
3.2. La Respuesta de los Mercados Financieros
Considerando la importancia del mercado de capitales de Estados Unidos, y con el propósito de tener un contexto general, se parte de una descripción del comportamiento histórico del índice bursátil S & P 500.
Tal y como se puede observar en la Figura 1 el índice tuvo una tendencia positiva a lo largo de los últimos 20 años, sin embargo, se evidencian periodos con pérdidas significativas ocurridos durante los años 2008 y 2009 (crisis sub-prime), 2020 (crisis sanitaria pandemia del COVID-19) y 2022 (conflicto armado invasión de Rusia a Ucrania); también se debe destacar el significativo incremento ocurrido en el índice posterior al inicio del confinamiento global hasta finales de 2021 impulsado principalmente por el crecimiento de las empresas del sector tecnológico.
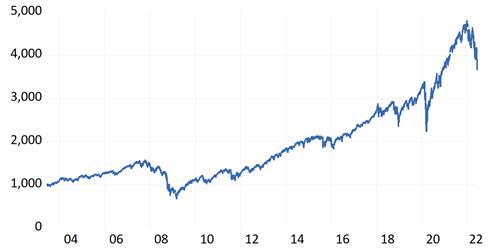
Fuente: Elaboración propia, en base a datos obtenidos de Capital IQ PRO [25].
Figura 1: Índice S & P 500 (2004 - 2022).
La evolución del índice se puede apreciar en términos relativos a través de las tasas de rendimiento, tal y como se presenta en la Figura 2 existen dos periodos que se destacan en los cuales la variabilidad diaria fue muy alta: 2008-2009 y a inicios del 2020.
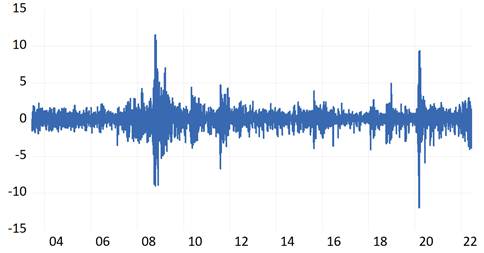
Fuente: Elaboración propia, en base a datos obtenidos de Capital IQ PRO [25].
Figura 2: Rendimientos diarios del Índice S & P 500 (2004 - 2022).
Precisamente uno de los indicadores más importantes es el nivel de riesgo de los mercados, el cual se puede medir mediante el índice de volatilidad (VIX)3. Tal y como se presenta en la Figura 3, el mercado de renta variable en periodos estables presentó un nivel de volatilidad en el rango de 10 a 20% como se observa en el periodo 2003 a 2007, sin embargo, la volatilidad se puede incrementar hasta un 40% como fue el caso del periodo 2020 a 2022, e incluso puede superar la volatilidad del 80% tal y como se presentó el año 2018 o a inicios de 2020.
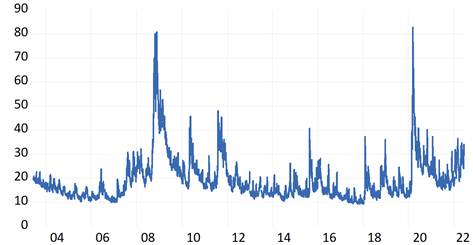
Fuente: Elaboración propia, en base a datos obtenidos de Capital IQ PRO [25].
Figura 3: Índice de Volatilidad (VIX) (2004 - 2022).
Una vez contextualizado los resultados de los mercados financieros, nos concentraremos en analizar el periodo 2007 - 2022 de 15 índices bursátiles que representan los siguientes mercados: Estados Unidos (S & P500 y NASDAQ100), China (CSI 300), Japón (Tokyo y Hang Seng), Corea (KOSPI), Reino Unido (FTSE 100), Alemania (DAX), Francia (CAC40), Suiza (SWISS), Brasil (IBOVESPA), Sud África (FTSE South A), España (IBEX35), Argentina (MERVAL), Chile (IPSA).
La Figura 4 permite apreciar con detalle el comportamiento de cada uno de los mercados, en el periodo los índices más destacados fueron: NASDAQ100 y S&P 500 de Estados Unidos, CSI300 de China y BOVESPA del Brasil. El comportamiento general a lo largo del tiempo se resume en los siguientes puntos: i) un periodo de crecimiento sostenido hasta finales de 2007 antes de la crisis hipotecaria, en el cual el mercado chino tuvo una expansión notable, ii) la caída de todos los mercados durante la crisis financiera, iii) un periodo de recuperación con elevada volatilidad hasta el 2011, iv) una disminución en el crecimiento de los mercados durante el periodo 2015 a 2016, con excepción del mercado de la china, v) a partir del 2016 los mercados se expandieron a diferentes ritmos, fue notable el crecimiento de las empresas tecnológicas hasta inicios del año 2022, vi) la caída de los mercados como resultado de la crisis sanitaria a inicios del año 2020, vii) una recuperación de los mercados, con un ritmo de crecimiento notable en Estados Unidos, la China y el Brasil, finalmente viii) la caída de los mercados a partir de enero de 2022, como resultado del conflicto entre Rusia y Ucrania, así como las condiciones económicas internas de Estados Unidos caracterizadas por elevados niveles de inflación y el consecuente incremento de las tasas de interés por parte de la FED.
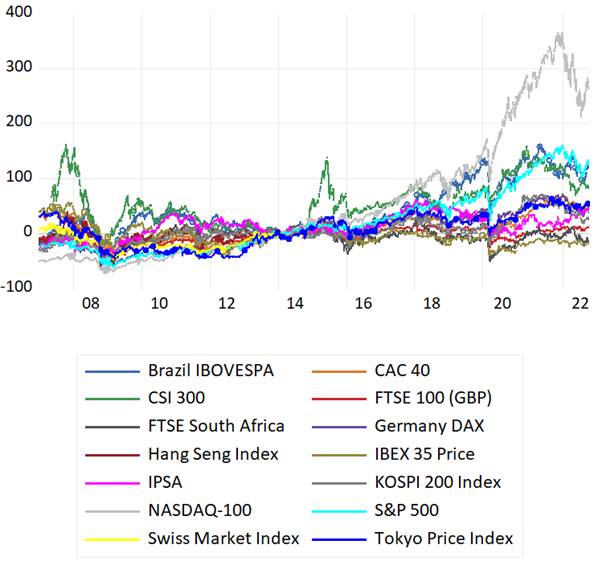
Fuente: Elaboración propia, en base a datos obtenidos de Capital IQ PRO [25].
Figura 4: Comportamiento de los índices bursátiles en los mercados internacionales (2007 - 2022).
3.2.1. El caso del conflicto armado entre Rusia y Ucrania
En este acápite se presenta el caso relacionado con el conflicto armado entre Rusia y Ucrania; para poder medir el impacto de este evento, tal y como señala Henderson [26] primero es necesario caracterizar los rendimientos normales, posteriormente se deben estimar los rendimientos en exceso, que se calculan como la diferencia matemática entre los rendimientos observados respecto a los rendimientos normales, Henderson [26] también recomienda implementar las respectivas pruebas de hipótesis para evaluar la significación estadística de los resultados.
Para realizar la estimación de los rendimientos normales Mackinlay [12] plantea: i) el modelo de rendimientos promedios constantes (constant mean return model), ii) el modelo de mercado y iii) modelos económicos de equilibrio (CAPM o APT)4.
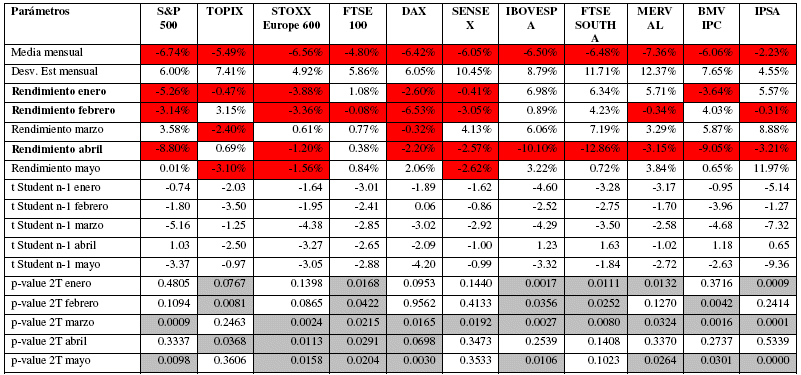
En la Tabla 2 se presentan los resultados obtenidos para 13 índices de mercado, se utilizó como variable proxy de rendimiento normal la media de rendimientos, que fue calculada a partir de datos mensuales correspondientes al periodo de enero de 2003 a junio de 2022, los rendimientos obtenidos a lo largo de los meses de enero a junio de 2022 fueron comparados con esta media y se evaluó la hipótesis nula de que los retornos fueron iguales.
Se evidencia que en todos los mercados al menos existió un mes cuyos rendimientos fueron estadísticamente diferentes a su promedio, se destaca el impacto que se tuvo en los meses de enero5, febrero y abril. Los mercados que tuvieron mayor cantidad de meses con rendimientos negativos fueron los europeos y la India (STOXX Europe 600, DAX, SENSEX), por otro lado, se evidencia que el Reino Unido, Sud África, Brasil y Argentina (FTSE 100, FTSU SA, IBOVESPA, MERVAL) tuvieron el menor impacto, incluso reportando rendimientos positivos cuando la mayor parte de los mercados estuvieron con pérdidas; finalmente el mercado ruso (MOEX) tuvo un comportamiento a la baja muy fuerte durante el mes de marzo.
El índice S & P500 reportó rendimientos negativos durante los meses de enero y febrero de 2022, marzo tuvo un repunte importante que hacía prever una recuperación del mercado, sin embargo, los niveles de inflación daban señales de un incremento en las tasas de interés, estos factores fueron descontados por el mercado generado la caída más importante del periodo durante el mes de abril.
Para complementar el análisis en la Tabla 3 se realizaron las mismas pruebas en cada mercado, sin embargo, en este caso los resultados alcanzados durante los meses de enero a junio de 2022 fueron comparados con los rendimientos promedios correspondientes al periodo de la crisis financiera ocurrido durante junio de 2008 a febrero de 2009. Se puede evidenciar que el impacto de los eventos relacionados con el conflicto bélico, así como la subida de las tasas de interés, llegaron a tener una caída en los retornos de los mercados internacionales en varios meses de una magnitud similar a la observada durante la crisis financiera.
Los valores de t-Student y los valores en probabilidad (p-value) permiten contrastar la hipótesis nula (Ho): Los rendimientos del mes fueron iguales al rendimiento promedio mensual, respecto a la hipótesis alterna (H1): Los rendimientos del mes fueron diferentes al rendimiento promedio mensual. Para los índices S & P500, DAX, SENSEX, FTSE SA, IPSA, y MOEX, se rechazó Ho en todos los meses. Para el TOPIX no se pudo rechazar Ho el mes de abril; el STOXX Europe 600 no se rechazó Ho el mes de marzo; en el FTSE 100 no se pudo rechazar Ho durante los meses de febrero, marzo y abril; el CSI 300 y el IBOVESPA no se rechazó Ho para el mes de febrero; en el caso del MERVAL no se pudo rechazar Ho para los meses de marzo y mayo; finalmente la BMV IPC no se rechazó Ho el mes de mayo.
Los valores de t-Student y los valores en probabilidad (p-value) permiten contrastar la hipótesis nula (Ho): Los rendimientos del mes fueron iguales al rendimiento promedio mensual correspondiente al periodo de crisis financiera (2008-2009), respecto a la hipótesis alterna (H1): Los rendimientos del mes fueron diferentes al rendimiento promedio mensual correspondientes al periodo de crisis financiera (2008-2009). Para el índice SP&500 no se rechazó Ho durante los meses de enero, febrero y abril; para el TOPIX no se rechazó Ho los meses de marzo y mayo; STOXX EUROPE 600 no se rechazó los meses de enero y febrero; el FTSE 100 se rechazó Ho durante todos los meses; el DAX no se rechazó Ho los meses de enero y febrero; en el SENSEX solo se rechazó Ho el mes de marzo; en IBOVESPA se rechazó Ho todos los meses excepto abril; en el FTSE SA no se rechazó Ho los meses de abril y mayo; en el MERVAL no se rechazó Ho los meses de febrero y abril; en BMV IPC no se rechazó Ho en enero y abril; finalmente el IPSA no se rechazó Ho los meses de febrero y abril.
TABLA 2 - EVALUACIÓN DE LOS RENDIMIENTOS MENSUALES (ENERO A JUNIO 2022)

Fuente: Elaboración propia, en base a datos obtenidos de Capital IQ PRO [25].
TABLA 3 - EVALUACIÓN DE LOS RENDIMIENTOS MENSUALES (ENERO A JUNIO 2022)
Fuente: Elaboración propia, en base a datos obtenidos de Capital IQ PRO [25].
3.3. Agrupación de los Índices Bursátiles por Métodos Jerárquicos
Los métodos jerárquicos tienen como objetivo formar agrupaciones de forma sucesiva con el objetivo de minimizar alguna distancia o maximizar alguna medida de similitud. Dichos métodos pueden ser aglomerativos, cuando todos los casos se agrupen en un mismo conglomerado o disociativos cuando, se empieza a través de un conglomerado y con sucesivas divisiones se forman grupos más pequeños hasta llegar a tantas agrupaciones como casos se tenga [27].
El dendrograma representa una jerarquía de grupos en la cual las distancias se convierten en alturas. De esta manera, se agrupan n variables, cada una con función p en grupos más pequeños. Para formar este diagrama se forman conglomerados de observaciones en cada paso y sus niveles de similitud. El nivel de similitud se mide en el eje vertical (aunque también se puede mostrar el nivel de distancia), y las diferentes observaciones se especifican en el eje horizontal, tal y como se presenta en la Figura 5.

Fuente: Elaboración Propia en base a Datos de Capital IQ.
Figura 5: Dendrograma de índices bursátiles.
Las unidades en el mismo grupo están vinculadas por una línea horizontal y proporcionan una representación visual de los clústeres. Se puede apreciar una similitud en los índices bursátiles que tienen proximidad geográfica, comparten similitudes en su comportamiento en su gran mayoría, con excepciones como el índice bursátil argentino MERVAL, este comportamiento anómalo en la autocorrelación de rendimientos puede deberse a los periodos de no transacción en mercados latinoamericanos [28].
El conglomerado de índices obtenido en la figura 1 comienza con todos los mercados separados, cada una formando su propio conglomerado. En el primer paso, los dos índices más cercanos entre sí se unen. En el siguiente paso, un tercer mercado se une a las primeras dos u otras dos variables se unen para formar un conglomerado diferente. Este proceso continuará hasta que todos los índices bursátiles que muestran un comportamiento similar se encuentren agrupados por conglomerados6.
Los resultados expuestos en el Dendrograma muestran siete agrupaciones o clúster de los mercados financieros internacionales7, al interior de cada clúster las respuestas fueron similares, sin embargo entre cada uno de los clúster el comportamiento frente a los eventos de crisis fue diferente; cabe destacar que los clústeres están asociados a la ubicación geográfica de cada mercado, tal y como se detalla a continuación: Clúster 1 Europa - IBEX35, GDAXI, SOTXX, CAC40, FTSE100 y SWISSMIP, Clúster 2 Estados Unidos - NASDAQ y SP500, Clúster 3 Asia y Chile - HANGSENG, Tokyo, KOSPI200, IPSA, Clúster 4 China con CSI300, Clúster 5 Brasil con IBOVESPA, Clúster 6 Argentina con MERVAL y Clúster 7 Sud África FTSESA.
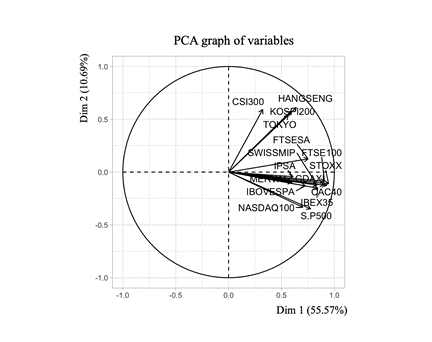
Para complementar este análisis se realizó una agrupación por componentes principales de los índices bursátiles; el análisis por componentes principales conocido como PCA, tiene como objetivo transformar un conjunto de variables correlacionadas en un nuevo clúster de variables no correlacionadas [29], en otras palabras, lograr una reducción de la dimensión de las variables.
Los resultados expuestos en la Figura 6 nuevamente demuestran agrupaciones de los mercados en función a su proximidad geográfica, el PCA dio como resultados dos dimensiones, vale decir que el conjunto de índices bursátiles se podrían consolidar en dos dimensiones8 sin embargo, dentro de estas dimensiones, se puede evidenciar la proximidad de los siguientes índices: i) IBEX35, GDAXI, STOXX, CAC40, SWISSMIP y FTSE100, FTSESA ii) NASDAQ 100 y SP500, iii) HANGSENG, KOSPI200, TOKYO, IPSA, y separados del resto de los índices se encuentran el MERVAL, CSI300, IBOVESPA. Los resultados en términos de cercanía en la gráfica son similares a los obtenidos en la Figura 6.

Fuente: Elaboración Propia en base a Datos de Capital IQ
Figura 6: Componentes principales de los índices bursátiles.
Finalmente, se implementó un análisis de círculo de correlaciones (Figura 7), en el cual se puede evidenciar que entre los dos componentes contienen el 66,26 % de la información total de las variables analizadas.
Mediante el círculo de correlaciones nuevamente se puede comprobar que los mercados financieros reaccionan de una manera directamente proporcional a las noticias y a los eventos macroeconómicos relevantes. La longitud de las flechas indica que tan bien representada esta la variable por los componentes principales, mientras más cercana al círculo unitario se encuentre esta flecha, mejor representada estará. Los índices CSI300, HANSENG, KOSPI200, TOKYOY FTSESA, tienen una correlación positiva respecto a las dos dimensiones, en el caso de NASDAQ100, SP500, IBOVESPA, CAC40 tienen una correlación positiva respecto a la dimensión 2 y correlación negativa respecto a la dimensión 1, finalmente los otros índices tienen una correlación cercana a 0 respecto a los dos índices.
4. CONCLUSIONES
A continuación, se detallan las principales conclusiones que reflejan el impacto de eventos ocurridos a lo largo de los últimos quince años sobre los mercados financieros:
El índice más representativo de los mercados financieros S&P 500 tuvo una tendencia positiva a lo largo de los últimos 15 años, sin embargo, se evidencian periodos con pérdidas significativas ocurridos durante los años 2008 y 2009 (crisis sub-prime), 2020 (crisis sanitaria pandemia del COVID-19) y 2022 (conflicto armado invasión de Rusia a Ucrania); también se debe destacar el significativo incremento ocurrido en el índice posterior al inicio del confinamiento global hasta finales de 2021 impulsado principalmente por el crecimiento de las empresas del sector tecnológico.
Respecto al comportamiento de los mercados internacionales, se destaca los niveles de rentabilidad alcanzados por NASDAQ100 de Estados Unidos, CSI300 de China y BOVESPA del Brasil. Durante el periodo de estudio los mercados atravesaron varios periodos de crisis y recuperación, sin embargo, a partir del año 2016 los mercados se expandieron a diferentes ritmos, como se mencionó fue notable el crecimiento de las empresas tecnológicas.
En el caso específico de la crisis generada por el conflicto armado entre Rusia y Ucrania, se pudo comprobar que en todos los mercados al menos existió un mes cuyos rendimientos fueron estadísticamente diferentes a su promedio, resultado que demuestra el impacto de estos eventos de crisis.
La aplicación de los modelos de ML a través del dendrograma y Componentes Principales muestran siete agrupaciones de los mercados financieros internacionales: Clúster 1 Europa - IBEX35, GDAXI, SOTXX, CAC40, FTSE100 y SWISSMIP, Clúster 2 Estados Unidos - NASDAQ y SP500, Clúster 3 Asia y Chile - HANGSENG, Tokyo, KOSPI200, IPSA, Clúster 4 China con CSI300, Clúster 5 Brasil con IBOVESPA, Clúster 6 Argentina con MERVAL y Clúster 7 Sud África FTSESA.
Por tanto, la existencia de estos clústeres es evidencia que los mercados financieros llegan a tener un comportamiento distinto frente a los periodos de crisis las cuales se encuentran asociadas a la ubicación geográfica de cada mercado.

