










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkActa Nova
versión On-line ISSN 1683-0789
RevActaNova. vol.9 no.2 Cochabamba jul. 2019
Artículo Científico
RNA's en el Análisis a Subyacentes de Divisas y Deuda Cotizadas en el MexDer.
Cinthya I. Mota-Hernández 1,3, Rafael Alvarado-Corona 1,3 & Benita Martha Jiménez García2
1Tecnológico de Estudios Superiores de Ixtapaluca, Tecnológico Nacional de México.
2Sección de Estudios de Posgrado e Investigación (SEPI), ESCA-Santo Tomás, Instituto Politécnico Nacional (IPN).
3Universidad Da Vinci.
Recibido: 18 de octubre 2018
Aceptado: 11 de junio 2019
Resumen: El presente trabajo de investigación reporta un modelo para el pronóstico de la tendencia en los activos de divisas (dólar y euro) y dos de deuda (CETES y TIIE) utilizados en futuros cotizados en el Mercado Mexicano de Derivados (MexDer), aplicando el enfoque de Redes Neuronales Artificiales (RNA's). Una de las principales aportaciones sugiere que el modelo propuesto basado en Inteligencia Artificial hace aproximaciones con un error menor al 19%. Las topologías utilizadas para la comparación de datos son: Perceptron Multicapa y Redes recurrentes con series de tiempo, las cuales ofrecen la posibilidad de obtener aproximaciones dentro de un rango aceptable en el pronóstico en el área financiera, considerando que a mayor riesgo mayor ganancia.
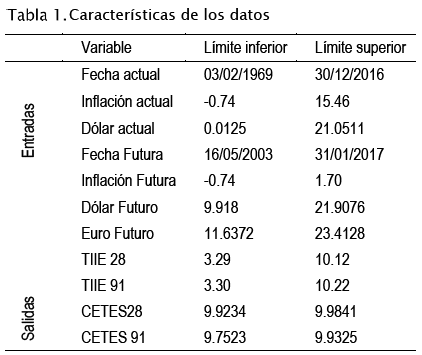
Como se mencionó con anterioridad, se evalúan 7 variables que representan las divisas: Dólar y Euro; los índices de deuda: TIIE a 28 y 91 días, los CETES a 28 y 91 días y se anexo la inflación debido a que es una de las variables macroeconómicas importantes. Debido a que se trata de predecir variables a corto, mediano y largo plazo en el tiempo, los datos de entrada para cada modelo de red toman en cuenta: la fecha actual, la inflación actual, el dólar actual como variable que representa al tipo cambiario y la fecha de predicción. Las RNA's fueron entrenadas con dato s históricos en donde las entradas consideran fechas a partir de 1969 y las salidas con datos históricos a partir del 2003. Los datos de las variables obtenidas serán comparados con datos reales de los años 2016, 2017 y 2018 y parte del 2019, para validar la RNA considerada óptima.
Palabras clave: Análisis, Divisas, RNA's, MexDer.
Abstract: This research paper reports a model for forecasting the trend in the currency assets (dollar and euro) and two debt (CETES and TIIE) used in futures quoted in the Mexican Derivatives Market (MexDer), applying the approach of Artificial Neural Networks (RNA's). One of the main contributions suggests that the proposed model based on Artificial Intelligence makes approximations with an error lower than 19%. The topologies used for the comparison of data are: Perceptron Multilayer and Recurrent networks with time series, which offer the possibility of obtaining approximations within an acceptable range in the forecast in the financial area, considering that the greater the risk the greater the gain.
As previously mentioned, 7 variables that represent currencies are evaluated: Dollar and Euro; the debt indices: TIIE at 28 and 91 days, the CETES at 28 and 91 days and inflation is added because it is one of the important macroeconomic variables. Because it is about predicting short, medium and long-term variables over time, the input data for each network model takes into account: the current date, current inflation, the current dollar as a variable representing the exchange rate and the prediction date. The RNAs were trained with historical data in which the entries consider dates from 1969 and the outputs with historical data from 2003. The data of the variables obtained will be compared with real data for the years 2016, 2017 and 2018 and part of the 2019, to validate the RNA considered optimal.
Key words: Analysis, ANN's, Foreign Exchange, MexDer.
1 Introducción
La predicción de series financieras ha adquirido gran atención dentro de las investigaciones empíricas. La importancia de conocer el comportamiento de activos financieros derivado en un futuro permite tomar previsiones para evitar tomar riesgos innecesarios o tener la oportunidad de obtener mayores beneficios en términos económicos.
Entre las técnicas estadísticas comúnmente empleadas para el pronóstico de series de tiempo se encuentran: la metodología Box-Jenkins [1]; la cual permite obtener buenas aproximaciones en el caso de que dicho método sea bien aplicado, ya que ésta metodología tiene una parte de arte en el sentido de que el proceso es iterativo hasta alcanzar el mejor modelo de acuerdo con la experiencia del investigador; los modelos estadísticos ARIMA; los modelos GARCH y mixtos.
Por otro lado, cada vez es más frecuente encontrar trabajos e investigaciones en donde se aplican técnicas innovadoras; entre las que se encuentran varias de la Inteligencia artificial [2-5], fractales [6], entre otras [7-9]; para pronosticar variables financieras.
Hasta ahora hay pocos estudios de pronóstico en México basados en redes neuronales artificiales aplicados en el Mercado Mexicano de Derivados (MexDer) para predecir sus variables. Se espera un mejor desempeño aplicando RNA's, en comparación a utilizar métodos estadísticos, ya que son capaces de identificar relaciones no lineales. Resulta muy recomendable también, saber cuáles son las virtudes de cada una de las técnicas disponibles, por lo que en este trabajo se presentan las fortalezas y debilidades del modelo que emplea RNA's como instrumento de predicción aplicado a series de tiempo financieras.
Se eligieron los activos subyacentes de divisas y dos de índices de deuda debido a la importancia de los contratos de futuros y opciones que se celebran en el MexDer [10]. Los primeros son un acuerdo negociado en una bolsa o mercado organizado, que obliga a las partes contratantes a comprar o vender un número de bienes o valores (activo subyacente) en una fecha futura, pero con un precio establecido de antemano. En cuanto a las opciones son contratos entre dos partes por el cual una de ellas adquiere sobre la otra el derecho, pero no la obligación, de comprarle o de venderle una cantidad determinada de un activo a un cierto precio y en un momento futuro.
Los contratos de futuros y opciones son instrumentos que presentan un alto grado de estandarización. Ello incorpora notables ventajas, pues simplifica los procesos e integra a los usuarios, incrementando los volúmenes de contratación y la liquidez de los mercados.
La creación del Mercado Mexicano de Derivados (MexDer) [10], inició en 1994 cuando la BMV y la S.D. Indeval asumieron el compromiso de proponer y crear el mismo. La Bolsa Mexicana de Valores (BMV) financió el proyecto de generar la bolsa de opciones y futuros que se denomina MexDer, Mercado Mexicano de Derivados, S.A. de C.V. Por su parte Indeval asumió la responsabilidad de promover la creación de la cámara de compensación de derivados que se denomina Asigna, Compensación y Liquidación, realizando las erogaciones correspondientes desde 1998 hasta las fechas de constitución de las empresas [10].
Posteriormente comenzaron a desarrollarse los instrumentos derivados financieros, cuyos activos de referencia son títulos representativos de capital o de deuda, índices, tasas y otros instrumentos financieros. Los principales derivados financieros son: futuros, opciones, opciones sobre futuros, warrants y swaps [11,12].
Es por esto por lo que se cuentan con contratos a futuro para:
DIVISAS: Dólar de los Estados Unidos de América, Euro.
INDICES: Índice de Precios y Cotizaciones de la BMV.
DEUDA: TIIE de 28 días, CETES de 91 días, Bono de 3 años, Bono de 10 años, Bono de 20 años, UDI, Swap de TIIE 10 años y Swap de TIIE 2 años.
ACCIONES, América Móvil L, Cemex CPO, Femsa UBD, Gcarso Al, Telmex L, Walmex V.
Y contratos de opción para:
INDICES: Opciones sobre Futuros del Índice de Precios y Cotizaciones de la BMV.
ACCIONES: América Móvil L, Cemex CPO, GMéxico B, Naftrac 02, Televisa, CPO y Walmex V.
ETF's: Términos Específicos ETF's.
DIVISAS: Dólar de los Estados Unidos de América
Sin embargo, para el entrenamiento, validación y producción de datos con RNA's se eligieron trabajar con los subyacentes de divisas, CETES, TIIE pertenecientes a los subyacentes de índices de deuda y se anexo la inflación.
2 Desarrollo
La investigación emplea dos modelos de RNA's: a) Perceptrón Multicapa (MLP), la cual es una de las topologías más utilizadas en diferentes áreas debido a que permite el entrenamiento con grandes cantidades de datos, el tipo de entrenamiento que maneja esta red puede ser supervisado y es una de las topologías apropiadas para resolver los diferentes tipos de problemas que en este caso es de predicción [13,14]; b) Recurrente con series de tiempo (RST), considerada la estructura más usual para problemas de predicciones financieras [15-17] en donde el tiempo es uno de los factores más importantes.
Las muestras con las que fueron entrenadas ambas topologías se componen por datos históricos del dólar [18], el euro [18], la inflación con respecto al Índice de Precios al Consumidor (TPC)[18], la Tasa de Interés Interbancario (TIIE) a 28 y 91 días [18] y los CETES a 28 y 91 días [18]. Se pretende que las redes puedan predecir las variables a corto, mediano y largo plazo. La Tabla 1 muestra las características de los datos utilizados para el entrenamiento de las RNA's.
Es difícil poder definir el número de capas y neuronas que nos proporcionarán la RNA óptima, sin embargo, se pueden proponer dichos valores de acuerdo con las especificaciones de la maquina en donde serán entrenadas [19], el número de entradas, el número de salidas requeridas y el número de muestras del conjunto de entrenamiento. En este caso, ambas redes fueron entrenadas en un equipo con las características mostradas en la Tabla 2.

Las características de desarrollo del MLP y de la red recurrente con series de tiempo propuestas se determinaron con respecto al rendimiento de la computadora en donde fueron entrenados, es importante mencionar que el incrementar número de capas y neuronas no garantizan que se pueda obtener un menor error, y por consecuencia un máximo rendimiento. En el caso de la función de transferencia elegida para el entrenamiento de las redes se consideró la función tangencial hiperbólica de acuerdo con el comportamiento de las variables de salida que se quieren obtener. La Tabla 3 documenta las características de ambas topologías.

Entonces, con base en la literatura, básicamente, las fases que se sugieren realizar durante el entrenamiento de una RNA son tres [20,21]. Se describen de manera sintética enseguida:
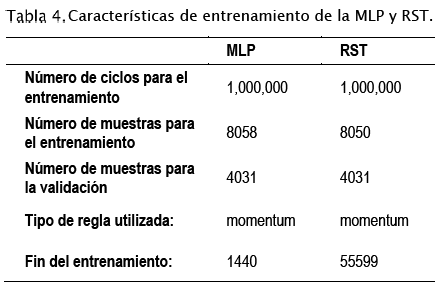
- Primera Fase: Se entrenó la red hasta que se obtuvieron los mejores pesos y se estabilizó la red. Durante la etapa de entrenamiento, al número de veces que se deben ingresar los datos de entrada y los deseados se le conoce como número de ciclos. Cuando la red aprende, el error debe tender a cero. En la Tabla 4 se pueden observar las características de entrenamiento de ambas redes propuestas.
- Segunda Fase: El entrenamiento en ambas topologías es supervisado por lo tanto es posible la validación de datos. Durante el entrenamiento, la red es alimentada también con las muestras seleccionadas para el conjunto de validación. Es importante mencionar que las muestras seleccionadas para el conjunto de validación no son parte del conjunto de entrenamiento. Se considera que del total 60% deberán conformar el conjunto de entrenamiento, 30% el de validación y 10% para producción de datos. La información generada por la red es comparada con los datos de salida reales del conjunto de validación. El rendimiento de la red es recopilado y se crea un informe que exhibe las diferencias entre los datos reales y los generados por la red para posteriormente calcular el porcentaje de error por cada salida y el de toda la red, tanto para el conjunto de entrenamiento como el de validación.
El informe generado en el entrenamiento y la validación contiene la información siguiente:
1. Gráfica de datos de salida en la red y salida deseada o real.
2. Se informa el error cuadrático medio (MSE), el error cuadrático medio normalizado (NMSE) y el porcentaje de error generado.
- Tercera Fase: se aplican únicamente nuevos datos de entrada para observar los resultados que brinda la RNA, lo cual es parte de la producción de datos.
3 Resultados y Discusión
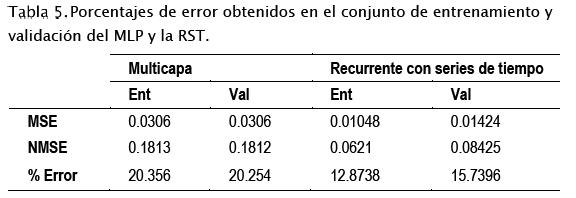
De acuerdo con los errores obtenidos en el entrenamiento y validación de las redes entrenadas se puede observar que la red óptima hasta el momento es la Recurrente con series de tiempo, debido a que es la que obtuvo un error del 15.79%. Los resultados obtenidos en ambas redes se observan en la Tabla 5.
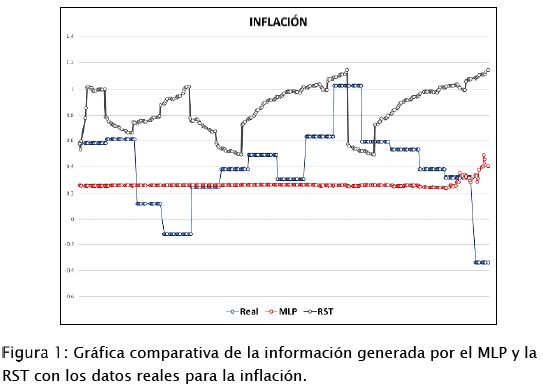
Posteriormente, se consideró un conjunto de 300 muestras para los datos de producción, comparando los datos reales con los generados por la red. La Figura 1: muestra los datos reales en comparación con los datos generados para la salida de inflación, en la cual se obtuvo un porcentaje de error promedio de 9.98 % en el MLP y del 32.21% para la RST.
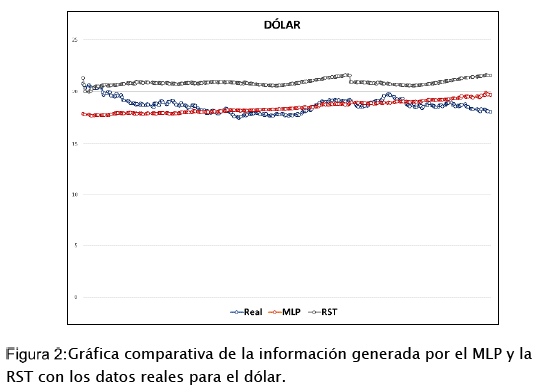
En el caso del dólar, el porcentaje de error que presento el MLP fue del 3.73 %, mientras que para la RST fue del 12.05 %. La Figura 2:, muestra las gráficas de los datos de producción obtenidos por las RNA's entrenadas en comparación con los datos reales del dólar.
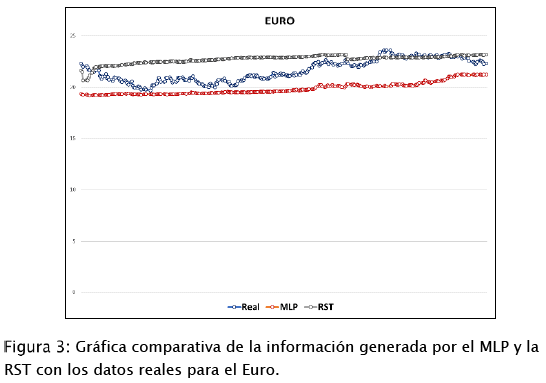
La Figura 3:, muestra las gráficas de los datos obtenidos por las RNA's entrenadas en comparación con los datos reales del Euro, en donde se obtuvo un porcentaje de error en el MLP del 7.95 % y en la RST de 5.77 %.
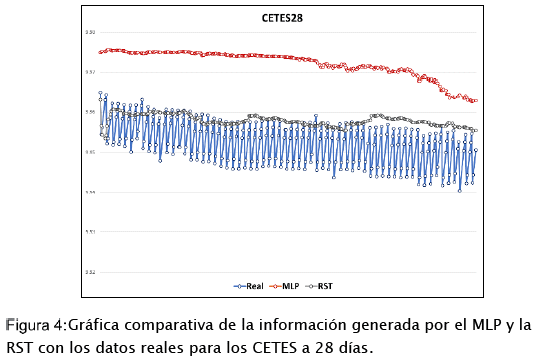
En el caso de los CETES a 28 días, el porcentaje de error que presento el MLP fue del 0.2 %, mientras que para la RST fue del 0.05 %. La Figura 4:, muestra las gráficas de los datos de producción obtenidos por las RNA's entrenadas en comparación con los datos reales del CETES a 28 días.
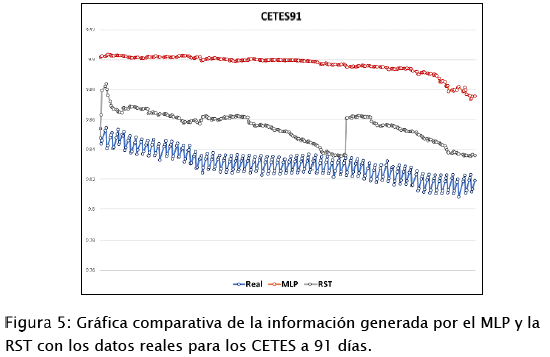
A la par, la Figura 5:, muestra las gráficas de los datos obtenidos por las RNA's entrenadas en comparación con los datos reales de los CETES a 91 días, en obteniendo un porcentaje de error en el MLP del 0.67 % y en la RST de 0.24 %.
En la Figura 6: se observa la salida deseada en el conjunto de producción de datos para la TIIE a 28 días comparada con la información generada por las RNA's, obteniendo un porcentaje de error de 42.40% en el MLP y 16.49 % en la RST.
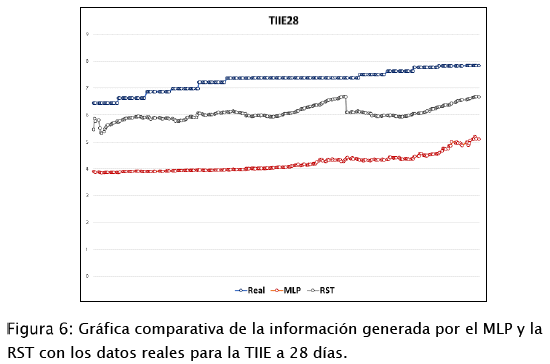
Por último, en la Figura 7: se muestra la salida deseada en el conjunto de producción de datos para la TIIE a 91 días en comparación con los datos proporcionados por las RNA's, en donde se obtuvo un porcentaje de error de 42.11% en el MLP y 23.12% en la RST.
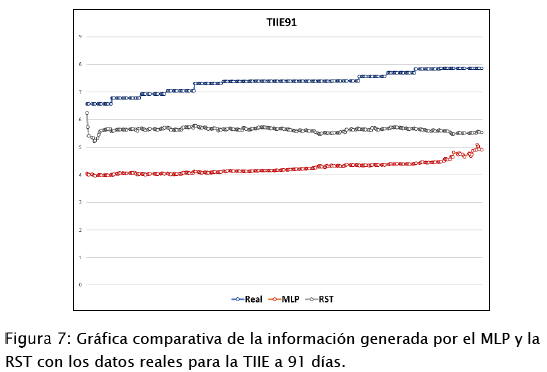
En la Tabla 6 se observan los porcentajes de error obtenidos para cada una de las salidas de las redes diseñadas y el porcentaje de error total en el conjunto de producción de datos, considerando como fecha futura datos desde el 1 de febrero de 2017 hasta el 16 de abril del 2018.
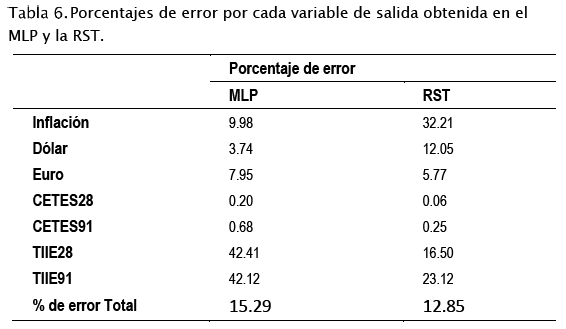
Algunos factores que intervinieron para obtener porcentajes de error bajos fueron el número de capas ocultas y el número de neuronas contenidas en cada capa oculta, sin embargo, el incrementar el número de capas y el número de neuronas por capa no garantiza que el porcentaje de error disminuirá. Los resultados sugieren mayor exactitud en la RST.
4 Conclusiones
Para el diseño de una red neuronal artificial se sugiere seleccionar el modelo de red que más se adecue a la resolución del problema, al número de muestras que se tienen, al error esperado, entre otros y por mencionar algunos. Se puede observar que las redes recurrentes con series de tiempo pueden ser una buena opción para problemáticas relacionadas con finanzas. Mientras que las de tipo Perceptrón multicapa son adecuadas cuando se cuentan con gran cantidad de muestras. Por otro lado, se considera relevante la elección de la función de activación que se van a utilizar, el número de capas y el número de neuronas en las capas ocultas, la regla de propagación y el tipo de aprendizaje. En el caso de las topologías propuestas, ambas se entrenaron con una regla de propagación de tipo momentum, por la gran cantidad de muestras que se trabajaron. En el caso de la regla de aprendizaje, se optó por el tipo supervisado, debido a que, a pesar de ser un conjunto de muestras grande, era posible que la computadora procesara de manera correcta los datos con este tipo de aprendizaje, utilizando 3 capas y entre 50 y 100 neuronas por capa.
Se puede ver que el número de neuronas de entrada y de salida viene dado por el número de variables que definen el problema, y a pesar de que actualmente hay fórmulas para calcular el comportamiento de la red por capas el mejoramiento y perfeccionamiento de una red se realiza más bien por prueba y error.
El MLP es un modelo/topología de red dentro de las RNA's que ha sido utilizado para abordar y resolver diferentes tipos de problemas con enfoques diversos, sin embargo, es una red cuyo entrenamiento puede llegar a consumir recursos como tiempo y en consecuencia considerarse lento, lo anterior dependiendo del número de capas y neuronas utilizadas, así como el hardware empleado, con base en lo anterior, los resultados sugieren que el error hasta ahora obtenido entre el 15% y 16% puede disminuir. Más investigación es necesaria para enriquecer, robustecer y pulir el modelo a través de la observación, análisis, síntesis y reflexión.
Agradecimientos
Los autores agradecen y reconocen al Instituto Politécnico Nacional por el apoyo otorgado para la elaboración del presente trabajo de investigación, al CONACyT y a todas y cada una de las instituciones públicas o privadas así como a las personas que de una u otra forma contribuyeron y aportaron al desarrollo del presente.
Referencias Bibliográficas
[1] Morales M. Oswaldo, Balankin Alexander, Contreras T. Teresa I., Mota H. Cinthya I, “La complejidad y la modelación de mercados financieros”. Memorias del XI Congreso Nacional de Ingeniería Electromecánica y de Sistemas. Escuela Superior de Ingeniería Mecánica y Eléctrica. Instituto Politécnico Nacional. 2009.
[2] Winston, Patrick H., Inteligencia Artificial. 3ª ed., Addison-Wesley Iberoamericana, 1994., pp. 805.
[3] Russell Stuard & Norvig Peter, “Inteligencia Artificial: Un enfoque Moderno.” Pearson Education S.A., Prentice Hall, Hispanoamerica S.A., 2004, pp. 1240.
[4] Montaño Moreno Juan José, “Redes Neuronales Artificiales aplicadas al Análisis de Datos”, Universitat De Les Illes Balears Facultad de Psicología, Palma De Mallorca, 2002 Tesis doctoral
[5] Ponce Jarrín, J. X. (2017). Comparación entre varios métodos de pronósticos basados en series de tiempo para predecir la demanda de placas digitales en empresas del sector gráfico quiteño desde el año 2009 hasta el año 2015. 370 hojas. Quito : EPN.
[6] Morales Matamoros, Oswaldo, Balankin, Alexander, Hernández Simón, Luis M., Metodología de predicción de precios del petróleo basada en dinámica fractal. Científica [en linea] 2005, 9 (Sin mes) : [Fecha de consulta: 18 de marzo de 2019] Disponible en:<http://www.redalyc.org/articulo.oa?id=61490101> ISSN 1665-0654
[7] León Anaya, Luis Manuel; Landassuri Moreno, Víctor Manuel; Orozco Aguirre, Héctor Rafael;Quintana López, Maricela. Predicción del IPC mexicano combinando modelos econométricos e inteligencia artificial Revista Mexicana de Economía y Finanzas. Nueva Época / Mexican Journal of Economics and Finance, vol. 13, núm. 4, diciembre, 2018, pp. 603-629 Instituto Mexicano de Ejecutivos de Finanzas A.C. Distrito Federal, México
[8] Santana Quintero, Luis Vicente; Coello Coello, Carlos A. Una introducción a la Computación Evolutiva y alguna de sus aplicaciones en Economía y Finanzas // An Introduction to Evolutionary Computation and some of its Applications in Economics and Finance. Revista de Métodos Cuantitativos para la Economía y la Empresa, [S.l.], v. 2, p. Páginas 3 a 26, nov. 2016. ISSN 1886-516X. Disponible en: <https://www.upo.es/revistas/index.php/RevMetCuant/article/view/2057>.
[9] Quirós Hernández, S.A. (2018). Predicción de fragilidad financiera para sociedades anónimas colombianas mediante la aplicación de las técnicas Logit, árboles de clasificación y boosting. (Tesis de Maestría). Universidad de Antioquia, Medellín. [ Links ]
[10] MexDer: www.mexder.com [ Links ]
[11] Alfonso de Lara. Productos derivados financieros: instrumentos, valuación y cobertura de riesgos. DO NOT USE, 2005. ISBN: 9681866339, 9789681866334. 186 páginas.
[12] Oscar Elvira Benito, Xavier Puig Pla, Comprender los productos derivados: Futuros, opciones, productos estructurados, caps, floors, Collars, CFDS. Profit Editorial, 2015. ISSN:8416115796, 9788416115792
[13] Manual Neurodimentions, Neurosolutions. (http://www.nd.com).
[14] Schlickewei, Ulrich, dir. Rojas Satián, Kevin Ricardo. Redes neuronales y series de tiempo : una aplicación en valores de activos financieros. Tesis (Licenciado en Matemáticas), Universidad San Francisco de Quito, Colegio de Ciencias e Ingenierías; Quito, Ecuador, 2018.
[15] Agustín Granell, Pau. Redes Neuronales Recurrentes: Una aplicación para los mercados bursátiles. 2018.
[16] Montañez, Miguel Alfonso Becerra, et al. Redes neuronales en predicción de mercados financieros: una aplicación en la bolsa mexicana de valores (neural networks in financial market prediction: an application in the mexican stock exchange). Pistas educativas, 2018, vol. 40, No. 130.
[17] Horacio Paggi, Predicción de series de datos utilizando redes neuronales, Montevideo, Uruguay, 2003, Instituto De Computación, Universidad De La República, Tesis De Maestría.
[18] De México, Banco. Banxico. 2015. http://www.banxico.org.mx/
[19] Mota-Hernández, C. I.; Alvarado-Corona, R.; Contreras-Troya, T. I. Eclectic Method for Developing Optimum ANN's. Procedia Computer Science, 2015, vol. 46, p. 1827-1834.
[20] Mota Hernández, Cinthya Ivonne. Metodología sistémica para solucionar problemas económico-financieros: caso MEXDER. 2012.
[21] Isasi Viñuela, Pedro, et al. Redes de neuronas artificiales: un enfoque práctico. 2004.

