










Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkActa Nova
versión On-line ISSN 1683-0789
RevActaNova. vol.8 no.4 Cochabamba set. 2018
Artículo Científico
Una técnica de muestreo para categorizar videos
A sampling technique to categorize videos
Denis Leandro Guardia Vaca, Juan Pablo Sandoval Alcocer
Departamento de Ciencias Exactas e Ingeniería, Universidad Católica Boliviana "San Pablo" Calle M. Marquez esquina Parque Jorge Trigo Andia Cochabamba, Bolivia.
Recibido: agosto 2018
Aceptado: septiembre 2018
Resumen: Categorizar grandes cantidades de videos de manera automática tiene muchas aplicaciones; como por ejemplo: el monitoreo de sistemas de seguridad o la búsqueda de videos. Una de las técnicas usadas para realizar esta actividad es el aprendizaje automático, a pesar de la gran precisión del aprendizaje automático en esta tarea, el tiempo que requiere entrenar los modelos de clasificación es considerablemente grande.
Este artículo describe una técnica de muestreo para reducir el tiempo que toma el entrenamiento de un clasificador de videos con el objetivo de mantener la precisión en la clasificación. La técnica consiste en utilizar aprendizaje automático para analizar solo una muestra del video y no así el video completo. Para entender el efecto del muestreo en el aprendizaje, se analizó un conjunto de videos de YouTube-8M, un conjunto de datos para clasificación de videos con más de siete millones de videos, utilizamos dos algoritmos de aprendizaje automático: regresión logística y red neuronal recurrente. Nuestros resultados muestran que, dependiendo del tamaño de la muestra, el tiempo de entrenamiento puede ser reducido considerablemente afectando levemente a la precisión.
Palabras clave: categorización de videos, sistemas de seguridad, aprendizaje automático.
Abstract: Automatically categorizing a large number of videos has many applications, for instance: security monitoring or video searching. Machine learning is one of the techniques that is used to automatically categorize videos. Beside the high precision of this technique, training a classification model may involve a large amount of time.
This paper describes a sampling technique to reduce training time while keeping a reasonable precision. This technique uses machine learning to analyze only a sample of a video instead of its full content. To better understand the effect of the video sampling in the categorization, we analyzed a subset of videos from YouTube-8M, a video classification dataset with more than seven million of videos, we used two machine learning algorithms: logistic regression and recurrent neuronal networks. Our results show that depending of the sample size, the training time may be considerable reduced, slightly affecting the precision.
Keywords: video categorization, security systems, machine learning.
1 Introducción
Hoy en día se generan y consumen inmensas cantidades de contenido digital, en diferentes formatos, este material es difundido de forma rápida y globalmente gracias a Internet. El contenido audiovisual en particular, debido a su eficacia comunicacional, es utilizado transversalmente en todos los ámbitos, un video puede tratar absolutamente de cualquier tópico, desde temas genéricos hasta áreas de interés sumamente específicas [8, 12, 17].
Cada día se crean cantidades inmensurables de videos, lo cual genera la necesidad de categorizar los mismos para agilizar su búsqueda. Diseñar un clasificador de temas principales de videos es un gran reto, un video contiene una carga semántica que depende de imágenes, movimiento, sonidos y orden de elementos audiovisuales que ocurren a través del tiempo. Una técnica genérica y efectiva de clasificación de videos conlleva muchos beneficios [12], dicha técnica podría categorizar y organizar grandes cantidades de videos de manera automática y rápida, así se mejorarán los mecanismos de búsqueda y recomendaciones, se podrá detectar contenido indeseado antes de ser publicado, se mejorarán sistemas de seguridad, entre otros.
Varias estrategias se han propuesto para categorizar videos, en los últimos años, subáreas de la inteligencia artificial como aprendizaje automático (machine learning) y el aprendizaje profundo (deep learning) han permitido grandes avances en el reconocimiento y clasificación de imágenes. Sin embargo, todavía no se ha profundizado lo suficiente en el campo de análisis de videos, actualmente se busca un modelo de aprendizaje efectivo para reconocer los temas principales de un video [17]. Este problema es complejo debido a distintas razones, entre ellas la gran carga computacional necesaria para procesar vastas cantidades de datos al ajustar modelos de aprendizaje.
Este articulo describe una técnica de muestreo para reducir la carga computacional que se requiere para ajustar modelos de aprendizaje para la categorización de videos, esta técnica fue motivada e inspirada por los resultados de la primera version del "Desafío de Comprensión de videos con Google Cloud y Youtube-8M" organizado por Google en Kaggle, la plataforma de competencias de modelamiento predictivo y análisis de datos para científicos de datos.
2 Inteligencia Artificial y Clasificación de Videos
Una forma de clasificar los videos automaticamente es haciendo uso de inteligencia artificial, en particular técnicas de aprendizaje automático (machine learning) [6, 14, 15]. El aprendizaje automático consiste en alimentar un programa con datos de ejemplo, los métodos de aprendizaje reconocen patrones en los datos de ejemplo y ajustan su configuración interna para construir un modelo que aprenda a resolver problemas específicos, a este proceso se le conoce como entrenamiento. En otras palabras el aprendizaje automático se basa en la construcción de modelos probabilísticos que descubren correlaciones en datos y que representan los resultados que se esperan obtener a partir de determinadas entradas.
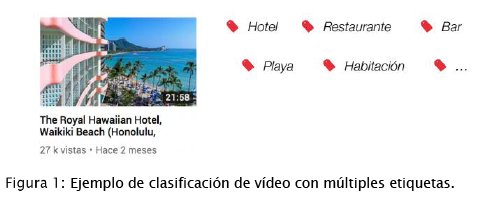
El resultado de clasificar un video es un conjunto de etiquetas que describen su contenido, por lo que la categorización de vídeos considera un problema de clasificación multi etiqueta [2, 9]. La clasificación multi etiqueta pertenece al dominio del aprendizaje supervisado, donde un conjunto de ejemplos de entrada asociados con salidas correctas son utilizados para el entrenamiento y la generación de modelo. En particular, para la clasificación de videos, la entrada son atributos audiovisuales y la salida es un conjunto de etiquetas que describen al video. Por ejemplo, considere la Figura 1, donde la entrada es un video de un hotel en Hawai y la salida son las etiquetas relacionadas a este video: hotel, restaurante, bar, playa, habitación, entre otras.
Una vez generado el modelo se puede usar el mismo para generar predicciones de salida para ejemplos con los cuales no fue entrenado. En nuestro caso, para generar etiquetas de videos sin clasificaciones previas.
El rendimiento de un clasificador depende de muchos factores, entre los más importantes están la cantidad y variedad de los datos de entrenamiento, la arquitectura del modelo y la configuración de su entrenamiento. Existen varias técnicas para clasificar los datos. En este artículo en particular, nos centraremos en dos: la regresión logística y la red neuronal recurrente LSTM. Las mismas se detallan en la siguientes subsecciones.
2.1 Regresión Logística
La Regresión Logística (RL) es un modelo sencillo de clasificación binaria, es decir, permite determinar si un elemento pertenece a una clase o no. Para dicha tarea, se utiliza la función sigmoidea o logística (Figura 2), esta función presenta una forma curvada que se extiende sin límites en el eje X, sin embargo, los limites del eje Y son O y 1 [6].

Este modelo se utiliza, por ejemplo, para la clasificación de correos electrónicos, en particular para determinar si un correo es spam o no, esta predicción está en función a los atributos del elemento como ser los metadatos y el contenido del correo. Debido a que el cálculo obtenido de una RL es un número entre 0 y 1, este se utiliza como una probabilidad de pertenencia y se lo transforma en un categoría con un "Umbral de Decisión", que generalmente es 0,5 [14]. En el caso de que un correo sea evaluado con 0.76 la predicción final es que el ejemplo es clasificado como no deseado (spam).
En el caso de los videos, la clasificación se realiza a partir de un marco o un fotograma de video. Las características de su contenido permiten a las RLs predecir a si este marco pertenece a una categoría o no. Por ejemplo, una imagen con diferentes matices de verde y con formas verticales cafés tiene una gran probabilidad de que pertenezca a la categoría "bosque". Una práctica común para clasificar videos de un conjunto de datos multi etiqueta es contar con múltiples RLs, donde cada una está especializada en reconocer una categoría del conjunto de datos.
2.2 Red Neuronal Recurrente
La Red Neuronal Recurrente de Memoria a Corto y Largo Plazo (RNR MCLP) es un modelo neuronal especializado en el análisis de secuencias de datos, es decir, conjuntos de elementos sucesivos e interdependientes [1]. Por ejemplo, las palabras de un texto, los sonidos en una nota de voz, y los fotogramas o marcos en los videos.
La RNR no es un modelo neuronal1 tradicional de propagación hacia adelante2, donde las neuronas propagan señales solamente a las capas siguientes de la arquitectura de la red. Las redes recurrentes presentan, adicionalmente, conexiones cíclicas en sus nodos, es decir que propaga información tanto hacia las siguientes capas como a sí mismas, esto permite modelar tomando en cuenta información pasada para su siguiente predicción y lograr modelar datos en secuencia como videos. Para comprender la característica recurrente de esta red, se grafica una flecha que sale de una capa de la red y que apunta hacia la fuente de origen, en la parte izquierda de la figura 3 se puede apreciar esta notación. En el lado derecho de la figura se puede observar la misma red en despliegue temporal, donde cada red representa un elemento de la secuencia que modela.
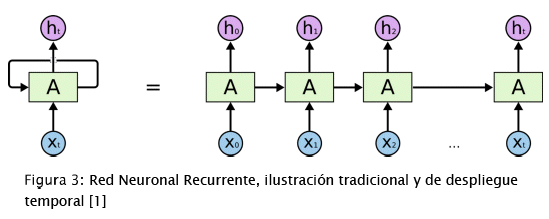
Existen diferentes redes recurrentes, en este trabajo se utilizó la Red Recurrente de Memoria prolongada de corto plazo (Long Short-Term Memory). Las neuronas que componen esa red se caracterizan por almacenar un estado interno que permiten retener información de elementos pasados de las secuencias de datos y tomarlos en cuenta para las predicciones actuales. Estas unidades cuentan con un mecanismo de compuertas encargado de seleccionar datos útiles, filtrar información innecesaria y reconocer datos relevantes para propagarlos [1].
El proceso de clasificación con una implementación de RNR MCLP se define con los siguientes pasos [10]:
1. Se ejecuta una serie de operaciones aritméticas entre los datos de ejemplo ingresados y los pesos del modelo.
2. Las neuronas seleccionan y descartan información para actualizar el estado interno de cada celda de memoria.
3. Las neuronas filtran los datos que consideran relevantes para propagarlos a sí mismas (conexión recurrente) y hacía las neuronas de la siguiente capa de la red, antes de la propagación se les aplica la función rectilínea uniforme (ReLU) para suprimir la propiedad lineal del modelo.
4. Se repiten los pasos 1, 2 y 3, la cantidad de veces correspondiente al número de capas de la red.
La última capa de la red devuelve una salida considerada como una predicción de un siguiente elemento en la secuencia de datos. Adicionalmente, la última capa de la red almacena el estado interno con la memoria de las características y evolución de los todos los elementos previamente evaluados.
3 Diseño Experimental
Para entender mejor el efecto del muestreo de videos en el tiempo de entrenamiento y la precisión diseñamos una metodología que se puede resumir en cuatro pasos:
Paso 1: Selección de conjunto de datos (videos).
Paso 2: Muestreo de videos.
Paso 3: Entrenamiento de modelos de clasificación.
Paso 4: Medición de tiempo de entrenamiento y precisión de clasificación.
En las siguientes subsecciones se detallan cada uno de estos pasos.
3.1 Selección del Conjunto de Datos
Para nuestro experimento utilizamos el conjunto de datos denominado Youtube-8M. Este conjunto de datos contiene más de 7 millones de videos que conforman aproximadamente 477 mil horas de visualización. Los videos de Youtube-8M están categorizados con un vocabulario de 4716 etiquetas [13].
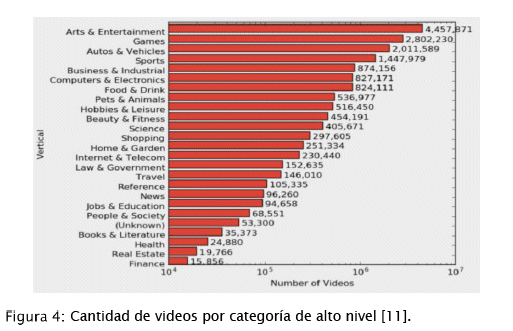
Actualmente, Youtube-8M tiene un conjunto de videos ya clasificados con sus respectivas etiquetas, estas etiquetas fueron extraídas del "Grafo de Conocimiento" de Google bajo la condición de que sean visualmente reconocibles. Algunas de las etiquetas del conjunto de datos son actividades humanas, animales, atracciones turísticas, comida, deportes, productos, entre otros. Con propósitos de organización, las 4716 etiquetas fueron agrupadas en 25 grupos de alto nivel o categorías verticales, en la figura 4 se puede ver la cantidad de videos por categoría vertical. Los videos están clasificados con un promedio de 3.4 etiquetas cada uno [4, 5, 7, 11].
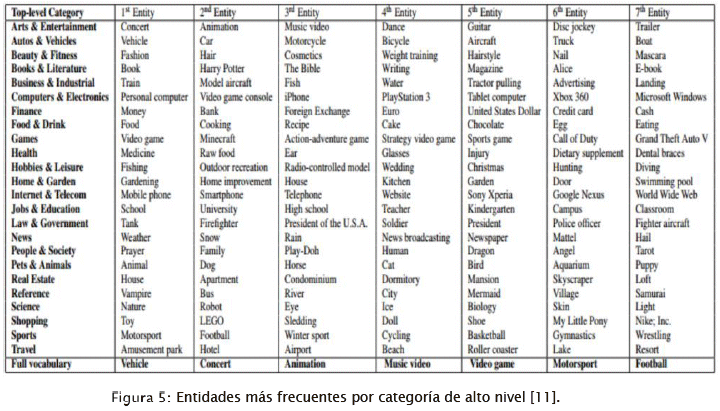
Los videos que componen el conjunto de datos fueron extraídos de la plataforma de Youtube, se seleccionaron videos en base al vocabulario que se construyó previamente. Este filtro fue posible debido a que los videos de la plataforma son automáticamente etiquetados por un sistema basado en reglas al momento de subirlos. Luego del proceso de selección y filtrado el conjunto de datos cuenta con 7,009,128 videos que duran entre 120 y 300 segundos. La Figura 5 muestra las categorías más frecuentes y las entidades3 que se consideraron por categoría.
El peso del conjunto de los videos recolectados es enorme (cientos de Terabytes), esto crea limitaciones computacionales y de almacenamiento para los investigadores. Por tal razón los videos de Youtube-8M fueron preprocesados, esta transformación permitió reducir el peso de almacenamiento de los videos con el objetivo de facilitar el análisis y transporte de los mismos. El proceso consistió en la extracción de las características principales de los marcos de video y audio [13], los resultados fueron 1024 bytes de atributos de imágenes y 128 bytes de atributos audio por cada segundo de video. Esta información (en bytes) representa las características principales del video durante cada segundo. Este trabajo utilizo este conjunto de datos pre-procesado para realizar los experimentos.
3.2 Muestreo de videos
Considere V={v1, v2 ... ,vn} como la información de un video de n segundos de duración en el conjunto de datos, donde v¡ es un arreglo que contiene los atributos principales del marco del video en el segundo i, donde 1 ≤ i ≤ n y 120 ≤ n ≤ 300. Youtube-8M provee las atributos visuales y de audio por cada segundo de video vi, para todos los videos del conjunto de datos. Definimos MV como una muestra de un video V, donde MV es un subconjunto de V. En este artículo, se propone utilizar solo una muestra del video para clasificar (etiquetar) el mismo. Es en este sentido, no es necesario utilizar la información de todos los segundos del video para poder clasificarlo, el objetivo es reducir carga computacional de la clasificación al utilizar una muestra y no el video completo.
Para extraer una muestra del video, utilizamos una técnica muy simple, recolectamos periódicamente información con un salto periódico al cual llamamos intervalo de recorte.
Por ejemplo, si consideramos un video de 10 segundos y utilizamos un intervalo de recorte K=3, entonces la muestra estará conformada con la información de los segundos 1, 4, 7 y 10 del video. La figura 6 muestra cómo las muestras son extraídas con diferentes intervalos de recorte.

De esta forma podemos extraer una muestra de video dado un intervalo de recorte K, donde el tamaño de la muestra de video dependerá del tamaño de K. A medida que K se incrementa, la muestra de marcos del vídeo es más pequeña.
3.3 Entrenamiento del modelo de clasificación.
Para entender el efecto del muestreo en la clasificación, analizamos dos técnicas de aprendizaje de clasificación: la regresión logística y la red neuronal recurrente LSTM. Estos modelos fueron seleccionados porque sus implementaciones están probadas y listas4 para ser entrenadas con los datos de Youtube-8M.
Parámetros de Entrenamiento. Para poder entrenar el modelo de clasificación se deben configurar los siguientes parámetros:
Atributos visuales: para nuestro experimento entrenamos al modelo con los atributos visuales de los videos, es decir, 1024 bytes disponibles por cada segundo de video después del preprocesamiento.
Epochs: para el entrenamiento se requiere analizar todo el conjunto de entrenamiento varias veces. Esta métrica indica la cantidad de veces que se introduce la totalidad del set de entrenamiento al modelo para el entrenamiento. En este experimento se utilizó un valor de 5, el cual es el valor por defecto [5].
Índice de Aprendizaje: este valor determina en qué proporción se actualizan los pesos sinápticos (w) de modelo después de cada análisis de un lote de videos (iteración), se utilizó un índice de 0.1, que también es el valor por defecto en el código inicial para trabajar con el conjunto de datos [5].
Otras variables. Aparte de los parámetros de entrenamiento que requiere el modelo, también consideramos las siguientes variables en el experimento:
Atributos de audio (Si / No): Para evaluar el impacto del uso de audio en la categorización, realizamos el experimento concatenando la información de audio del video. Al igual que los atributos visuales, se tiene las características principales del audio del video dividido en intervalos de un segundo, la diferencia es que el tamaño del arreglo es de 128 Bytes.
Tamaño de lote (128 / 1024): El entrenamiento de un modelo es un proceso iterativo, donde cada paso de entrenamiento consiste en analizar cierta cantidad de videos, esto se conoce como tamaño de lote. Debido a que este parámetro tiene un impacto directo en el experimento, se tomará en cuenta un lote de videos pequeño (128) y otro grande (1024). Dichos valores se tomaron del repositorio oficial de Youtube-8M [5].
Subconjunto de entrenamiento: El modelo será entrenado un con un subconjunto aleatorio del dataset. Durante el experimento utilizamos 80% de los subconjuntos de datos para entrenar los modelos de clasificación, 20% para la validación.
3.4 Medición de tiempo de entrenamiento y precisión del modelo.
Nuestro experimento consiste en comparar el efecto del muestreo en el tiempo que toma entrenar el modelo y su precisión de clasificación [10]. Sin embargo, también es necesario considerar el efecto de las variables descritas en la anterior subsección (3.3). Por lo que medimos el tiempo de entrenamiento y la precisión del modelo utilizando las siguientes configuraciones e infraestructuras.
Infraestructura. Para entrenar el modelo, medir su tiempo de ejecución y calcular su precisión se utilizaron dos infraestructuras diferentes:
Computadora Personal. Macbook Pro del año 2013, equipada con un microprocesador Intel-Core i7 (2.3GHz) de 4ta generación, 16 GBs de RAM y sin habilitación de aceleración por GPU.
Entorno Remoto. Motor de Aprendizaje Automático de Google [14], se utilizaron procesadores gráficos (GPU) NVIDIA Tesla K80 y se entrenaron la cantidad de modelos que cubrieron los créditos gratuitos que ofrece la plataforma [3].
Regresión Logística. Para analizar el efecto de la segmentación en la técnica de Regresión Logística medimos el tiempo de ejecución y la precisión utilizando las siguientes configuraciones.
Computadora Personal. Para realizar el experimento en la computadora persona solo se usaron 16,96 Gigabytes de videos del conjunto de datos Youtube-8M, 13,28 GB para el entrenamiento y 3,68GB para la validación. Sobre todo por las limitaciones de hardware que se tiene al ser una computadora personal. El experimento se realizó con diferentes tamaños de lote, 128 y 1024, así también como con y sin atributos de audio. En resumen, se entrenaron modelos con las siguientes configuraciones:
Tamaño de Lote 128, sin Audio.
Tamaño de Lote 128, con Audio.
Tamaño de Lote 1024, sin Audio.
Tamaño de Lote 1024, con Audio.
Entorno Remoto. Para realizar el experimento en el entorno remoto, se utilizó 572 Gigabytes de videos, 450 GB para el entrenamiento y 122 GB para la validación. Gracias a las características de hardware del entorno remoto que se utilizó (procesamiento acelerado por GPU y gran memoria RAM) se realizó el experimento con un conjunto de datos de mayor magnitud. Sin embargo, debido a la gran cantidad de tiempo que se necesita para entrenar el modelo, solo se realizaron pruebas con tamaño de lote de 1024 y con audio, como se detalla a continuación:
Tamaño de Lote 128, con Audio.
Tamaño de Lote 1024, con Audio.
Red Neuronal Recurrente. Del mismo modo analizamos el efecto en la técnica de Red Neuronal Recurrente, medimos el tiempo de ejecución y la precisión utilizando las siguientes configuraciones.
Computadora Personal. A diferencia de la regresión logística, las redes neuronales recurrentes requieren mucho más tiempo para entrenar el modelo, por esta razón solo se utilizo 1,67 Gigabytes de videos para el entrenamiento y 372MB para la validación. Usando las siguientes configuraciones:
Tamaño de Lote 128, sin Audio.
Tamaño de Lote 128, con Audio.
Tamaño de Lote 1024, sin Audio.
Tamaño de Lote 1024, con Audio.
Entorno Remoto. A pesar de que el entorno remoto tiene buenas características en hardware, debido a la gran cantidad de tiempo que se necesita para entrenar el modelo, no fue viable realizar el experimento en un tiempo considerable, para analizar el comportamiento del modelo al ser entrenado con una mayor cantidad de videos que en la computadora personal. Como trabajo futuro, planeamos realizar el experimento con un subconjunto del dataset más grande.
4 Resultados
4.1 Regresión Logística
4.1.1 Tiempo de Entrenamiento.
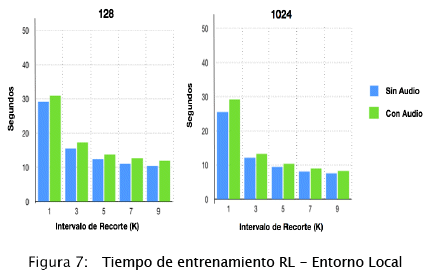
Computadora Personal. La figura 7 muestra el tiempo requerido para entrenar la red neuronal con diferentes intervalos de recorte y tamaño de lote. Como se esperaba, la figura muestra que mientras más grande sea el intervalo de recorte el tiempo de entrenamiento es más pequeño. Esto es debido a que un mayor intervalo de recorte resulta en muestras de vídeos más pequeñas, por lo que la RL se entrena con menos datos acelerando el proceso de entrenamiento. Como era de esperarse, el entrenamiento con atributos de audio dura más tiempo en comparación al procesamiento sin audio.
Las diferencias entre el entrenamiento sin recorte (K=1) y con recorte de 3 segundos es de 14 segundos aproximadamente, esta es la disminución de mayor magnitud, por otro lado, los modelos entrenados con recortes de 5 segundos o mas disminuyeron en menor proporción, entre 3 y 1 segundos.
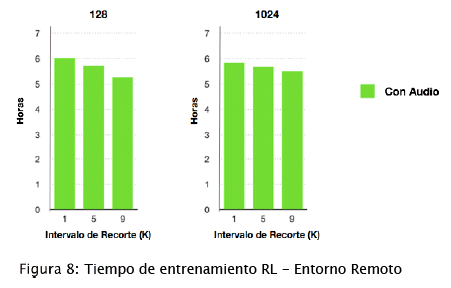
Entorno Remoto. La figura 8 muestra el tiempo de entrenamiento en horas de nuestros experimentos en el entorno remoto. Al igual que en el entorno local, el tiempo de entrenamiento reduce a un mayor intervalo de recorte. Note que en el entorno remoto, la disminución del tiempo de entrenamiento no es tan grande como en las pruebas locales, el procesamiento necesario para ajustar RLs no es tan costoso, este entrenamiento en la nube no está condicionado por cálculos computacionales llevados a cabo por GPUs, sino por un cuello de botella generado por el acceso continuo a memoria para la lectura de datos. Debido a largo tiempo que tarda en entrenar, solo se hizo el análisis incluyendo los atributos de audio.
4.1.2 Precisión de la clasificación
Como se observó en el análisis de tiempos, el entrenamiento de modelos con más videos por iteración (tamaño de lote) disminuye el tiempo entrenamiento, por esta razón, se descartó el entrenamiento con lotes de tamaño pequeño (128 videos) en el análisis de precisión. Sin embargo, en las pruebas en el entorno remoto se realizó una excepción, se entrenaron modelos con tamaños de lote de 1024 y 128 para estudiar el efecto en la precisión de la clasificación al entrenar modelos con subconjuntos grandes de datos.
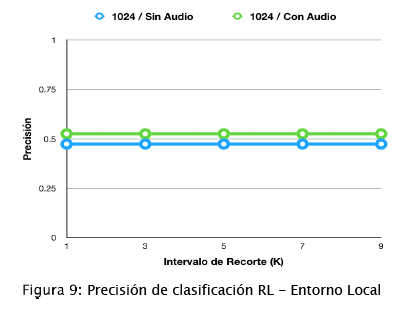
Computadora Personal. Como se puede ver en la figura 9, la precisión no se ve afectada a medida que se incrementa el intervalo de recorte. Las precisiones (Precisión Promedio Global) están alrededor de 0,5, estos valores indican que el modelo no supo clasificar correctamente muchos de los videos del conjunto de validación. Por otro lado, la RL alimentada con atributos de audio tiene 0,05 más precisión que el modelo entrenado sin audio, por lo tanto, incluir los datos de audio beneficia el aprendizaje de clasificación.
Entorno Remoto. La figura 10 muestra la precisión de la RL en un entorno remoto. Al igual que en las pruebas locales, la precisión no se vio afectada a medida que se incrementaron los intervalos de recorte. En este caso, la precisión de ambos modelos se encuentra alrededor de 0,715, este valor indica que los modelos cometen menos errores al clasificar videos en comparación con las RLs entrenadas localmente, esta mejora se debe a que se tomó una muestra grande del conjunto de entrenamiento para ajustar el modelo. Ademas, como se puede ver en la figura 10, la diferencia de precisión entre los modelos entrenados con lote de 128 y 1024 videos es insignificante (0,007).
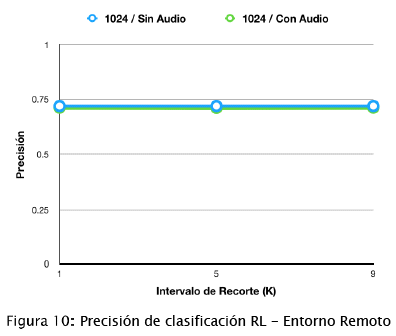
La RL entrenada con más datos presentó una precisión de 0,719, este resultado se obtuvo después de un entrenamiento en el entorno remoto de aproximadamente 6 horas con 450 GB del conjunto de entrenamiento sin recortes. En el entorno local se obtuvo una precisión de 0,525 después de 5 minutos de entrenamiento con 13 GB del conjunto de entrenamiento y con un intervalo de recorte de 9 segundos.
4.2 Red Neuronal Recurrente
4.2.1 Tiempo de Entrenamiento
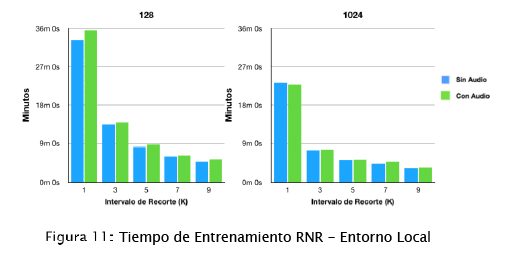
Computadora Personal. En la Figura 11 se pueden observar los tiempos de entrenamiento para las diferentes configuraciones de las RNRs MCLP, en el caso de estas redes, los tiempos disminuyen en mayor magnitud que las RLs a medida que se incrementan los intervalos de recorte. Como se puede observar, la reducción de tiempo con periodos de análisis de 1 y 9 segundos es de aproximadamente 85%. Al igual que con las RLs, el recorte de marcos cada 3 segundos presenta la mayor disminución de tiempos de entrenamiento.
Como sucedió con las RLs, las RNRs configuradas incluyendo el audio y con lote 128 requirieron más tiempo en entrenar y, por otro lado, los modelos entrenados con lote 1024 incluyendo y excluyendo audio, fueron los modelos que concluyeron el entrenamiento en menor tiempo. Como se puede observar en la figura 11, una caracteristica propia de las RNRs MCLP es que el tamaño de lote de videos influye en los tiempos de entrenamiento en mayor medida que la inclusión o exclusión de atributos audio.
4.2.2 Precisión de la clasificación
Entorno Local. En la figura 12 se puede observar la PPG de las RNRs MCLP entrenadas localmente, los valores son extremadamente bajos (menores a 0.04), esto se debe a la complejidad de las RNRs y a la pequeña magnitud del conjunto de entrenamiento. Las redes aprendieron a interpretar las secuencias de marcos específicamente para los videos con los que fueron entrenados, generando predicciones incorrectas ante nuevos ejemplos del conjunto de validación, este fenómeno es conocido como sobreentrenamiento[16].
Otra peculiaridad de estos resultados es un notable patrón en las variaciones de las precisiones de ambos modelos (tamaño de lote 1024, con y sin audio), las RNRs entrenadas con recortes de 5 segundos presentan la precisión mínima y los modelos con recortes de 7 segundos presentan las máximas precisiones. Es posible que los marcos analizados cada 5 segundos hayan entrenado el modelo incorrectamente para ciertos ejemplos del conjunto de validación y que al contrario los marcos analizados cada 7 segundos hayan favorecido el aprendizaje para la posterior validación con ejemplos parecidos a los que ocasionaron el sobreentrenamiento. Por otro lado, también se puede observar que, aunque sea en pequeña escala, incluir el audio beneficia la precisión de la clasificación.

Las RNRs tardan mucho tiempo en entrenar debido a que cada marco ingresado representa una unidad temporal que actualiza la red por cada elemento de la secuencia ingresado previamente. En el peor de los casos, al ingresar el último marco de la secuencia de un video de 300 segundos, la RNR debe actualizar 299 redes, la arquitectura de la red consiste en dos capas de 1024 celdas de memoria MCLP cada una, esta es la razón de la gran carga computacional de las RNRs.
Las precisiones obtenidas de las RNRs también se mantuvieron constantes con el incremento de intervalos de recorte, en este caso, a pesar de los largos tiempos de entrenamiento, las precisiones obtenidas son mínimas (entre 0,02 y 0,035), sin embargo, estos resultados no reflejan un aprendizaje analizable.
5 Discusión y Trabajo Futuro
Intervalo de Recorte. Si bien usando un intervalo de recorte constante resultó en buenos resultados en términos de precisión, pueden existir mejores estrategias. Por ejemplo, establecer un intervalo de recorte aleatorio o pseudo aleatorio. Como trabajo futuro planeamos evaluar el muestreo con diferentes estrategias de segmentado de video.
Datos de Entrenamiento. La efectividad de los algoritmos de aprendizaje puede variar de acuerdo a la cantidad de datos de entrenamiento. Si bien utilizamos una cantidad de datos de entrenamiento relativamente grande, es posible tener una mejor precisión usando más datos. Como trabajo futuro planeamos analizar el efecto del conjunto de datos de entrenamiento en la precisión.
Número de epochs. Tanto los entrenamientos ejecutados en el experimento utilizamos un epoch=5 (5 iteraciones). La configuración de este parámetro fue 5 porque este es el valor por defecto del repositorio de código inicial para trabajar con Youtube-8M. Debido a que el número de epochs influye directamente en los tiempos de entrenamiento, como trabajo futuro pretendemos analizar el grado de mejora en la precisión y tiempo de entrenamiento con diferentes valores de epochs.
Otras técnicas de clasificación. Existen otras técnicas que permite clasificar sucesiones de elementos audiovisuales. Como trabajo futuro, se planea analizar el efecto del muestreo con diferentes técnicas de modelamiento temporal, particularmente con: RNR GRU (Gated Recurrent Unit), RNR Bidireccionales, VLAD (vector of locally aggregated descriptors). También se pretende realizar el análisis con redes neuronales convolucionales.
6 Conclusión
Este artículo presenta una técnica de muestreo para reducir la carga computacional que se requiere para entrenar modelos de clasificación de videos. Nuestro experimento muestra que esta técnica pudo reducer el tiempo de entrenamiento, afectando levemente la precisión de la clasificación utilizando un modelo de Regresión Logística. En la computadora personal, se obtuvo una reducción de más del 40% dependiendo del intervalo de recorte. Por otro lado, en el entorno remoto, la reducción no superó el 5%, debido a las características de hardware del entorno, donde el entrenamiento esta acelerado GPU y el muestreo influyo levemente en los tiempos de entrenamiento.
Por otro lado, Las Redes Recurrentes de Memoria a Corto y Largo Plazo procesaron el entrenamiento lentamente. Aunque sus precisiones tampoco se vieron afectadas por el incremento del intervalo de recorte y el tamaño de la muestra. Sin embargo, la situación no es la misma que con las RLs, los subconjuntos de datos que se utilizaron para entrenar RNRs fueron pequeños, debido a la gran cantidad de tiempo que se requiere para entrenar el modelo con un conjunto de datos mayor. El uso un de conjunto de datos pequeño causo el sobre-entrenamiento en el modelo, este hecho se vio reflejado en las precisiones pequeñas (menores a 0.04). Por lo que por el momento, no podemos determinar una conclusión concreta acerca del efecto del muestreo en redes neuronales recurrentes. Como trabajo futuro planeamos realizar el mismo experimento con un conjunto de datos de mayor magnitud.
Notas
1 Su arquitectura surgió de la idea de la replicación de la estructura del cerebro humano, una inmensa red de neuronas que envían y reciben señales a través de múltiples interconexiones.
2 Las Redes neuronales de propagación hacia adelante se caracterizan por presentar una arquitectura de múltiples capas de neuronas donde las conexiones y los flujos de datos sólo se dan hacia las capas siguientes.
3 Un entidad puede ser una objeto de la vida real, tanto animado o inanimado, que puede ser fácilmente identificado.
4 Estos modelos se encuentran disponibles en el repositorio de código inicial para trabajar con Youtube-8M.
Referencias Bibliográficas
[1] A. Karpathy, "The Unreasonable Effectiveness of Recurrent Neural Networks," 2015. [En línea]. Disponible en: http://karpathy.github.io/2015/05/21/rnn-effectiveness/.
[2] F. C. A. J. R. M. J. d. J. Francisco Herrera, Multilabel Classification: Problem analysis, Metrics and Techniques, 2016.
[3] Google Inc., "Google Cloud Machine Learning Engine," 2017. [En línea]. Disponible en: https://cloud.google.com/ml-engine/. [Último acceso: 27 03 2017].
[4] Google Research Blog, "An updated YouTube-8M, a video understanding challenge, and a CVPR workshop. Oh my!," 15 02 2017. [En línea]. Disponible en: https://research.googleblog.com/2017/02/an-updated-youtube-8m-video.html. [Último acceso: 29 07 2017].
[5] Google, "Starter Code for working with the Youtube-8M dataset," 2017. [En línea]. Disponible en: https://github.com/google/youtube-8m.
[6] K. P. Murphy, Machine Learning: A Probabilistic Perspective, The MIT Press, 2012.
[7] K. X. J. L. J. Z. Haosheng Zou, "The Youtube-8M Kaggle Competition: Challenges and Methods," 2017.
[8] KPCB, "2016 Internet Trends," [En línea]. Disponible en: http://www.kpcb.com/internet-trends. [Último acceso: 23 Marzo 2017]. [ Links ]
[9] M. H. S. V. O. V. R. M. G. T. Joe Yue-Hei Ng, "Beyond Short Snippets: Deep Networks for Video Classification," 04 2015.
[10] M. Zhu, "Recall, Precision and Average Precision," 2014.
[11] Machine Perception Research @ Google, "Youtube-8M Website," 2017. [En línea]. Disponible en: https://research.google.com/youtube8m/index.html. [Último acceso: 25 Julio 2017].
[12] MDP Digital Media, "10 statistics that show video is the future of marketing," [En línea]. Disponible en: https://mwpdigitalmedia.com/blog/10-statistics-that-show-video-is-the-future-of-marketing/. [Último acceso: 23 Marzo 2017]. [ Links ]
[13] N. K. J. L. P. N. G. T. B. V. S. V. Sami Abu-El-Haija, "YouTube-8M: A Large-Scale Video Classification Benchmark," 09 2016.
[14] Stanford University, "Machine Learning Online Course," 2016.
[15] T. M. M. M. I. Jordan, "Machine Learning: Trends, perspectives, and prospects," Sciencemag, 2015.
[16] Yoshua Bengio, "Practical Recommendations for Gradient-Based Training of Deep Architectures", 2012.
[17] Youtube, "Youtube," [En línea]. Disponible en: https://www.youtube.com/yt/press/es-419/statistics.html . [Último acceso: 23 Marzo 2017]. [ Links ]

