Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkActa Nova
On-line version ISSN 1683-0789
RevActaNova. vol.5 no.4 Cochabamba Sept. 2012
ARTÍCULO CIENTÍFICO
Estudio de las variables que influyen para alcanzar el máximo throughput en un trayecto de un sistema inalámbrico multi-salto multi-canal
Study of variables that influence to achieve maximum throughput on a path of a multi-hop multi-channel wireless system
Jorge Hernán Vásquez Hurtado
Nuxway Technology S.R.L.
Calle Reza E-0151, Cochabamba, Bolivia
e-mail: jorge.vasquez@nuxway.net
Recibido: enero 2012; Aceptado: junio 2012.
Resumen: El presente trabajo trata acerca del estudio de las variables que influyen para alcanzar la máxima capacidad de transferencia de datos en un trayecto de un sistema inalámbrico multi-salto multi-canal. La metodología empleada consistió en la realización de simulaciones usando el software ns2 modificado para el soporte de múltiples canales, variando en cada una de dichas simulaciones una serie de variables que influyen en este tipo de sistemas, como ser el número de nodos intermedios, el número de canales, el tamaño de los paquetes de datos y el tamaño de la cola de espera de dichos paquetes en cada uno de los nodos. Al final se obtuvo una serie de resultados que fueron procesados con el software de análisis estadístico SPSS, usando técnicas como el Análisis de Componentes Principales (ACP) y pruebas de hipótesis de comparación de medias.
Palabras clave: Análisis de Componentes Principales, multi-canal, multi-salto, OFDM, Pruebas de hipótesis, Sistema inalámbrico.
Abstract: This paper deals with the study of the variables that influence to achieve maximum data transfer capacity in a journey of a multi -hop multi - channel wireless system. The methodology consisted of performing simulations using the modified to support multi-channel software ns2, varying in each of these simulations a number of variables that influence these systems, such as the number of intermediate nodes, the number channels, the size of the data packets and the size of the queue of these packets in each of the nodes. Finally, a set of results that were processed with statistical analysis software SPSS were obtained, using techniques such as Principal Component Analysis (PCA) and hypothesis tests for comparison of means was obtained.
Keywords: Principal Component Analysis, multi-channel, multi-hop, OFDM, Hypothesis Testing, Wireless System.
1. Introducción
El desarrollo de los sistemas de telecomunicaciones inalámbricas en la actualidad está centrado, principalmente, en incrementar la capacidad de los mismos para poder mejorar la experiencia del usuario final, dándole acceso a servicios avanzados de banda ancha. Surgió entonces la interrogante de cuáles son las variables que influyen en alcanzar la capacidad máxima de transferencia de datos (inglés: throughput) en un trayecto de un sistema de comunicaciones inalámbricas multi-salto(inglés: multihop)multi-canal. El presente trabajo respondió precisamente a esta pregunta, realizando simulaciones en el software ns2 y aplicando técnicas de análisis estadístico como el Análisis de Componentes Principales y las pruebas de hipótesis.
1.1 Software ns2
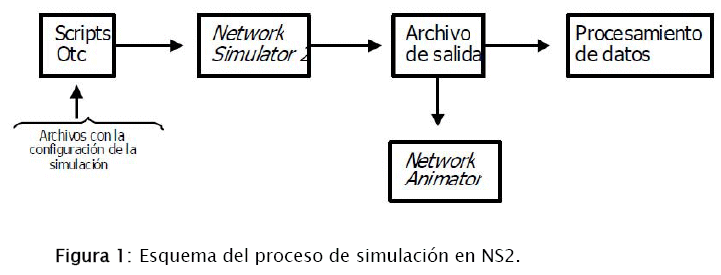
Ns2 es un software disponible en múltiples plataformas que ofrece soporte para la simulación de todo tipo de redes tanto cableadas como inalámbricas. Se trata de uno de los simuladores de redes más ampliamente utilizado entre la comunidad docente e investigadora del área de redes de datos, originalmente desarrollado dentro del proyecto VINT. Consta de un núcleo principal escrito en C++ al que se invoca simplemente tecleando ns en la línea de comandos. A partir de este punto el usuario puede interactuar directamente con el simulador, a través de un lenguaje de interface llamado OTcl, una versión del lenguaje Tcl 2 orientada a objetos. Otra forma más recomendable de usar ns2 es definiendo un script, donde se detalla los protocolos de comunicaciones y otros aspectos de la red a simular, como su topología, tipo de tráfico a generar: tasa de bits (inglés: bitrate)constante o variable, etc. Conforme avanza la simulación, se genera un conjunto de datos de salida que se almacena en un fichero de traza. A partir de las trazas de simulación se puede utilizar lenguajes como Perl y AWK para filtrar la traza y obtener los datos específicos que se desee evaluar; ns2 además incluye la herramienta Network Animator (nam), que permite realizar un análisis visual del envío y recepción de paquetes de datos y control a medida que avanza la simulación. La figura 1 muestra un esquema del proceso general de simulación [2].
1.2 ACP: Análisis de Componentes Principales
El Análisis de Componentes Principales (ACP) es una técnica estadística de análisis de datos que pertenece a la familia de los análisis factoriales, por tanto, se puede decir que el ACP:
- Es una técnica descriptiva.
- Es una técnica de reducción de dimensionalidad.
- Persigue el estudio de las relaciones de interdependencia entre grupos de variables cuantitativas e individuos.
El ACP es la más primitiva de las técnicas de análisis factorial, tiene su origen en los trabajos de Kart Pearson publicados en 1901 en la revista Philosophical magazine con el título de Onlines and planes of closest fit to systems of points in space; esta técnica fue posteriormente estudiada por Hotelling alrededor de los años 1930, sin embargo, esta técnica no se popularizó sino hasta la aparición de las computadoras, puesto que el hecho de realizar los cálculos manualmente era algo muy difícil y tedioso; cosa que las computadoras hacen en tan sólo instantes.
En el ACP se parte de p-variables originales, correlacionadas entre sí, para luego obtener un conjunto de combinaciones lineales de dichas variables (llamadas componentes principales) no correlacionadas, de manera que la primera recoge el máximo de variabilidad, la segunda el máximo de lo que queda y así sucesivamente; de esta forma se consigue que la pérdida de información debida a la reducción de la dimensionalidad sea mínima; además se tendrá que el número máximo de nuevas variables es igual al de las originales.
Un aspecto clave en el ACP es la interpretación de las componentes principales, ya que ésta no viene dada a priori, sino que será deducida tras observar la relación de las mismas con las variables iniciales. Esto no siempre es fácil, y será de vital importancia el conocimiento que el experto tenga sobre la materia de investigación [6], [10].
1.3 Fases del Análisis de Componentes Principales
Las fases del ACP son las siguientes:
1. Análisis de la matriz de correlaciones: Un ACP tiene sentido si existen altas correlaciones entre las variables, ya que esto es indicativo de que existe información redundante y, por tanto, pocos componentes explicarán gran parte de la variabilidad total; si todas las variables fueran independientes, el ACP no tendría sentido, puesto que el número de componentes principales sería igual al número de variables originales; por tanto, no se estaría ganando nada en cuanto a reducción de la dimensionalidad.
2. Selección de las componentes principales: La elección de las componentes se realiza de tal forma que la primera recoja la mayor proporción posible de la variabilidad original; la segunda componente debe recoger la máxima variabilidad posible no recogida por la primera, y así sucesivamente; la medida de cuánta variabilidad está siendo capturada por una componente está dada por los autovalores o valores propios. Del total de componentes se elegirán aquéllas que recojan el porcentaje de variabilidad que se considere suficiente, o en otros términos, se elige generalmente aquéllas que tengan autovalores mayores que 1; a éstas se les denominará componentes principales (la cantidad de componentes principales r generalmente es 2 o 3, siendo 2 lo deseable, lo cual permite hacer representaciones gráficas en dos dimensiones).
3. Análisis de la matriz de componentes (o matriz factorial): Una vez seleccionados los componentes principales, se representan en forma de matriz. Cada elemento de la matriz representa los coeficientes factoriales de las variables (las correlaciones entre las variables y los componentes principales). La matriz tendrá tantas columnas como componentes principales y tantas filas como variables.
4. Interpretación de las componentes principales: Cuando existe una alta correlación positiva entre todas las variables, la primera componente principal tiene todas sus coordenadas del mismo signo y puede interpretarse como un promedio ponderado de todas las variables o un factor global de tamaño. Las restantes componentes se interpretan como factores de forma y típicamente tienen coordenadas positivas y negativas que implica que contraponen unos grupos de variables frente a otros.
Para que una componente principal sea fácilmente interpretable (es decir, sea fácil de asignarle algún nombre relacionado con las variables originales) debe tener las siguientes características, las cuales son difíciles de conseguir:
- Los coeficientes factoriales deben ser próximos a 1.
- Una variable debe tener coeficientes elevados sólo con una de las componentes principales.
- No deben existir componentes principales con coeficientes similares.
5. Para concluir con la interpretación de los datos: se elabora un gráfico llamado gráfico de individuos, el cual representa los datos originales en un plano cuyos ejes son precisamente los componentes principales (plano factorial); este gráfico nos permite ver el posicionamiento de los datos originales en cuanto a las variables agrupadas por las componentes principales.
1.4 Pruebas de hipótesis
Una prueba de hipótesis es una metodología de inferencia estadística para juzgar si una propiedad que se supone cumple una población estadística es compatible con lo observado en una muestra de dicha población. Fue iniciada por Ronald Fisher y fundamentada posteriormente por Jerzy Neyman y Karl Pearson. Mediante esta teoría, se aborda el problema estadístico considerando una hipótesis determinada y una hipótesis alternativa, y se intenta determinar cuál de las dos es la hipótesis verdadera, tras aplicar el problema estadístico a un cierto número de experimentos. Está fuertemente asociada a los considerados errores de tipo I y II en estadística, que definen respectivamente, la posibilidad de tomar un suceso verdadero como falso, o uno falso como verdadero. Existen diversos métodos para desarrollar dicho test, minimizando los errores de tipo I y II, y hallando por tanto la hipótesis con mayor probabilidad de ser correcta [11].
Planteamiento de una prueba de hipótesis
El enfoque actual considera siempre una hipótesis alternativa a la hipótesis nula. De manera explícita o implícita, la hipótesis nula, a la que se denota habitualmente por H0, se enfrenta a otra hipótesis que es denominada hipótesis alternativa y que se denota H1. En los casos en los que no se especifica de manera explícita, se puede considerar que ha quedado definida implícitamente como es falsa. Si por ejemplo se desea comprobar la hipótesis de que dos poblaciones tienen la misma media, se está implícitamente considerando como hipótesis alternativa ambas poblaciones tienen distinta media. Se puede, sin embargo, considerar casos en los que H1 no es la simple negación de H0[11].
Errores en una prueba de hipótesis
Una vez realizado el contraste de hipótesis, se habrá optado por una de las dos hipótesis, H0 o H1, y la decisión escogida coincidirá o no con la que en realidad es cierta. Se pueden dar los cuatro casos que se exponen en la Tabla 1.

Si la probabilidad de cometer un error de tipo I está unívocamente determinada, su valor se suele denotar por la letra griega α, y en las mismas condiciones, se denota por β la probabilidad de cometer el error de tipo II, esto es:
P(escoger H1/H0 es cierta)=α
P(escoger H0/H1 es cierta)=β
Se denomina Potencia del contraste al valor de 1-β, esto es, a la probabilidad de escoger H1 cuando ésta es cierta:
P(escoger H1/H1 es cierta)=1-β
Se denomina Nivel de confianza al valor de 1-α, esto es, a la probabilidad de escoger H0 cuando ésta es cierta:
P(escoger H0/H0 es cierta)=1-α
Cuando es necesario diseñar una prueba de hipótesis, sería deseable hacerlo de tal manera que las probabilidades de ambos tipos de error fueran tan pequeñas como fuera posible. Sin embargo, con una muestra de tamaño prefijado, disminuir la probabilidad del error de tipo I (α), conduce a incrementar la probabilidad del error de tipo II (β). Usualmente, se diseñan los contrastes de tal manera que la probabilidad α sea el 5% (0,05), aunque a veces se usan el 10% (0,1) o 1% (0,01) para adoptar condiciones más relajadas o más estrictas. El recurso para aumentar la potencia del contraste, esto es, disminuir β, probabilidad de error de tipo II, es aumentar el tamaño muestral, lo que en la práctica conlleva un incremento de los costes del estudio que se quiere realizar [11].
Procedimiento de realización de una prueba de hipótesis
Según [8], el procedimiento que se debe seguir para realizar una prueba de hipótesis es el siguiente:
1. Identificar el parámetro de interés.
2. Establecer la hipótesis nula H0.
3. Especificar una hipótesis alternativa adecuada H1.
4. Seleccionar un nivel de significancia α.
5. Establecer un estadístico de prueba adecuado.
6. Establecer la zona de aceptación y la zona de rechazo de H0.
7. Aceptar o rechazar H0.
Prueba de hipótesis de comparación de medias
Este procedimiento permite saber si las medias a nivel poblacional μ de dos muestras pueden ser consideradas iguales, para ello se realiza el contraste de la hipótesis nula H0: μ1 = μ2 frente a la hipótesis alternativa H1: μ1 ≠μ2 en el caso de muestras independientes y varianzas poblacionales desconocidas, distinguiendo los casos en que éstas sean iguales o distintas. Por ello, también se debe efectuar previamente un contraste de comparación de varianzas poblacionales, que es la Prueba de Levene (un contraste más independiente que otros respecto de la hipótesis de normalidad de las variables implicadas). Recordemos que para aplicar esta técnica se ha de cumplir que las variables tengan distribución normal o que los tamaños muestrales sean grandes (mayores o iguales que 30) [7].
1.5 OFDM: Multiplexión por División de Frecuencias Ortogonales
La modulación multi-portadora es el principio por el cual se transmiten datos dividiendo el flujo de bits en varios otros flujos, cada uno de los cuales tiene una menor tasa de bits; estos flujos son utilizados para modular varias sub-portadoras. La característica de la Multiplexión por División en Frecuencias Ortogonales (OFDM) es que las sub-portadoras son mutuamente ortogonales, de tal manera que no se interfieran entre sí aunque se solapen. Este tipo de ondas puede ser generado usando la transformada discreta de Fourier (DFT) [9].
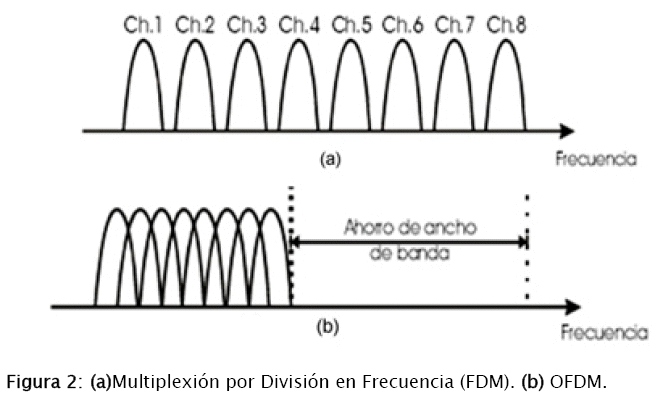

2. Trabajos previos
2.1 Máxima capacidad de transferencia de datos de un trayecto inalámbrico multi-salto de un solo canal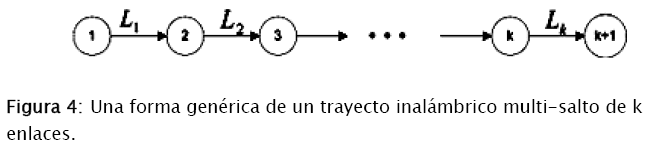
En [5]se resolvió la interrogante de cuál es la máxima capacidad de transferencia de datos extremo a extremo de un trayecto inalámbrico multi-salto de un solo canal, el cual consta de dos puntos: A (transmisor) y B (receptor) conectados mediante múltiples nodos intermedios. Se presentó los siguientes escenarios, en los cuales se consideraba que todos los enlaces Li tenían una capacidad normalizada de 1:
- Nodos intermedios ubicados de manera óptima, sólo hay interferencia entre nodos adyacentes, se tiene un ambiente libre de errores. En este caso se demostró que la máxima capacidad del sistema es de 1/3.
- Nodos intermedios ubicados de manera óptima, sólo hay interferencia entre nodos adyacentes, se tiene un ambiente con presencia de errores. En este caso se demostró que la máxima capacidad del sistema es igual al mínimo de las capacidades máximas de segmentos consecutivos de 3 saltos dentro del trayecto total.
- Nodos intermedios ubicados aleatoriamente, los cuales pueden interferir con cualquiera de sus nodos vecinos, se tiene un ambiente libre de errores. En este caso se demostró que la máxima capacidad del sistema es igual al inverso de γ(G)+1, donde G es el grafo de conflictos (un grafo de conflictos tiene como nodos a los enlaces del sistema Li. Si dos enlaces interfieren entre sí, sus respectivos nodos estarán unidos por un arco) del trayecto multi-salto y γ(G) es el máximo grado de envío del grafo (el grado de envió de un nodo Li en un grafo de conflictos se define como el número de nodos vecinos cuyos índices son mayores a i.)
- Nodos intermedios ubicados aleatoriamente, los cuales pueden interferir con cualquiera de sus nodos vecinos, se tiene un ambiente con presencia de errores. En este caso se demostró que la máxima capacidad del sistema es igual al mínimo de las máximas capacidades de los cliques (un clique en un grafo de conflictos G se define como un conjunto máximo de nodos mutuamente adyacentes) del grafo de conflictos G del trayecto multi-salto.
3. Metodología
La metodología implementada para la resolución del problema fue la siguiente:
- Se realizó simulaciones en el programa ns2 modificado para soportar múltiples canales y múltiples interfaces, el cual se puede adquirir de [3]. Esta modificación fue realizada en base al trabajo citado en [1], donde los autores proveen una guía de cambios necesarios al código fuente de ns2 para soportar la funcionalidad anteriormente mencionada.
- Las parámetros generales de simulación fueron los siguientes:
– Modelo de propagación: Espacio libre.
– Protocolo MAC: 802.11.
– Tipo de la cola: FIFO.
– Tamaño de la cola variable, igual para todos los nodos.
– Se tiene un nodo origen y un nodo destino, comunicados por un número de nodos intermedios variable.
– El nodo origen genera un tráfico CBR (Constant Bit Rate), con tamaño de paquete variable e intervalo de duración del paquete constante (0,008 ms).
– Antenas omnidireccionales.
– Número de canales variable.
– Nodos posicionados aleatoriamente.
- Se corrió un total de 225 simulaciones, para cada una de las cuales se varió los siguientes parámetros:
– Número de nodos en total: 2-6.
– Número de canales: 1-5.
– Tamaño del paquete: 10, 100, 1000 bytes.
– Máxima cantidad de paquetes en la cola: 10, 1.000, 100.000.
- Para cada simulación se computó el throughput.
- Los resultados de las simulaciones fueron almacenados en un archivo de texto con valores separados por comas, para que el mismo fuera procesado posteriormente usando el programa de análisis estadístico SPSS. Las variables almacenadas fueron:
1. identifi: Identificador del número de simulación.
2. nn: Número de nodos.
3. nc: Número de canales.
4. ps: Tamaño del paquete (bytes).
5. len: Tamaño de la cola (paquetes).
6. trput: Throughput (Kbps).
4. Resultados
Se realizó un ACP en SPSS con los datos obtenidos, y los resultados fueron los siguientes:
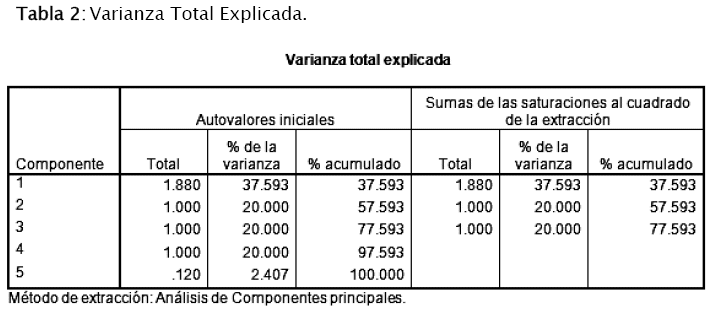
Observando la Tabla 2: se tiene que:
1. La componente 1 captura el 37,593% de la variabilidad de los datos.
2. La componente 2 captura el 20%.
3. La componente 3 captura el 20%.
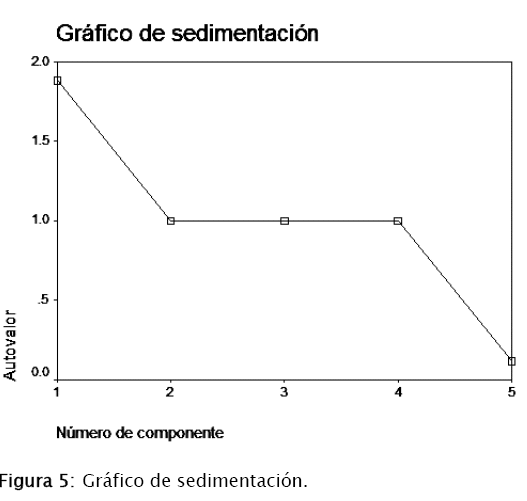
Sumando entre las tres componentes se tiene un 77,593%; por tanto se puede decir que estas tres componentes capturan gran parte de la variabilidad de los datos. Además, los autovalores de los componentes 1, 2 y 3 son mayores o iguales 1, como se puede observar en la tabla 2 y en la figura 5, por tanto, éstas serán las componentes consideradas.
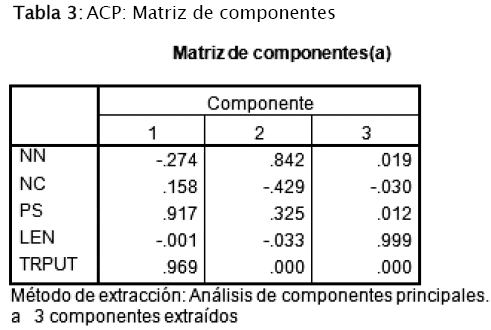

Observando la Tabla 3 y la Figura 6, se puede llegar a las siguientes conclusiones:
1. Las variables throughput y tamaño del paquete están fuertemente relacionadas con la componente 1.
2. Las variables número de nodos y número de canales están relacionadas con la componente 2.
3. La variable tamaño de la cola está fuertemente relacionada con la componente 3.
En base a los anteriores resultados, se pudo elaborar el gráfico de individuos, presentado en la Figura 7, el cual es un gráfico de dispersión que representa los valores obtenidos en cada simulación, respecto a las tres componentes principales obtenidas.
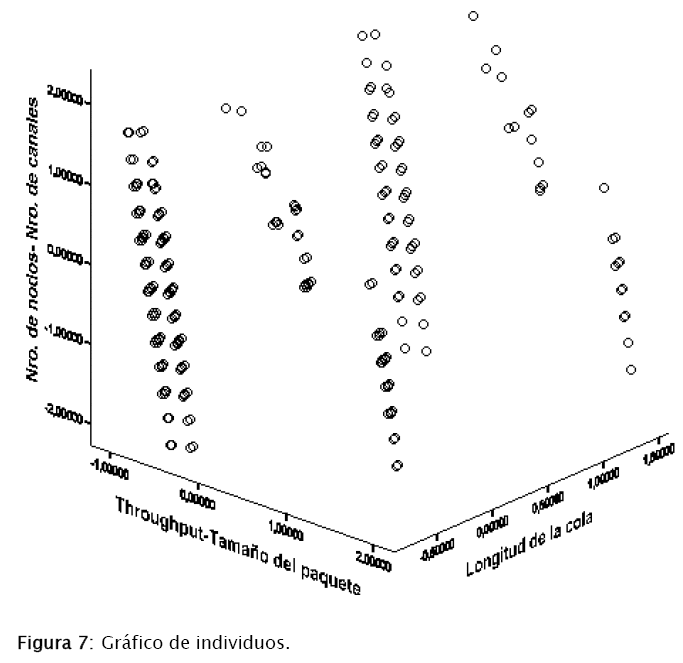
Analizando el gráfico de individuos, se pudo observar que la variable len no influye en el throughput, para comprobar este hecho se aplicó pruebas de hipótesis de comparación de medias usando el software SPSS bajo las siguientes condiciones:
– Se consideró un nivel de significancia α=5%.
– Las poblaciones fueron definidas en base a la variable len:
* Población 1: len=10.
* Población 2: len=1.000.
* Población 3: len=100.000.
– Se tomó muestras aleatorias de cada población:
* Población 1: 50 muestras.
* Población 2: 39 muestras.
* Población 3: 48 muestras.
– Se comparó las medias de las poblaciones 1 y 2, y los resultados se muestran en la tabla 4:
H0: μ1 = μ2
H1: μ1 ≠ μ2
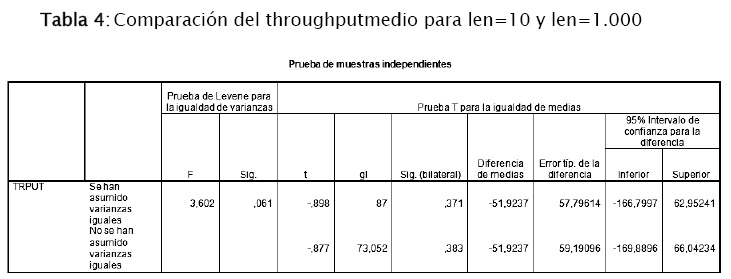
Para la prueba de Levene, como Sig=0,061 > α, se considera varianzas iguales. Entonces se tiene que, para la prueba de igualdad de medias, Sig=0,371> α, por tanto se acepta H0.
– Se comparó las medias de las poblaciones 1 y 3, y los resultados se muestran en la tabla 5:
H0: μ1 = μ3
H1: μ1 ≠ μ3

Para la prueba de Levene, como Sig=0,112> α, se considera varianzas iguales. Entonces se tiene que, para la prueba de igualdad de medias, Sig=0,429> α, por tanto se acepta H0.
- Se comparó las medias de las poblaciones 2 y 3, y los resultados se muestran en la tabla 6:
H0: μ2 = μ3
H1: μ2 ≠ μ3

Para la prueba de Levene, como Sig=0,718> α, se considera varianzas iguales. Entonces se tiene que, para la prueba de igualdad de medias, Sig=0,889> α, por tanto se acepta H0.
5. Conclusiones
Interpretando el gráfico de individuos, se pudo llegar a las siguientes conclusiones:
- Se alcanza el máximo throughput cuando no se tiene nodos intermedios entre el transmisor y el receptor.
- El throughput y el tamaño de los paquetes están íntimamente relacionados.
- Si se aumenta el número de canales y se mantiene todos los demás parámetros del sistema constantes, el throughput se incrementa.
- A medida que se aumenta el número de nodos intermedios, el throughput va disminuyendo; aunque se incremente el número de canales.
- El tamaño de la cola FIFO no es un parámetro que afecte al throughput del sistema. Esta conclusión es además confirmada por las pruebas de hipótesis realizadas, las cuales demuestran que el valor medio del throughput es el mismo para todos los tamaños de cola.
Referencias
[1] Agüero Calvo, R. & Pérez Campo, J.. Adding multiple interface support in NS2. http://telecom.inescporto.pt/~rcampos/ucMultiIfacesSupport.pdf, accedido el 23/11/2013. [ Links ]
[2] Hernández, C. & Vicente, J. Introducción al simulador de redes NS-2. http://riunet.upv.es/bitstream/handle/10251/12735/Art%C3%ADculo%20docente%20NS-2.pdf?sequence=1, accedido el 23/11/2013. [ Links ]
[3] http://www.codeforge.com/article/212010, accedido el 23/11/2013. [ Links ]
[4] Londoño, C.A. 2004. wMultiplexación por División de Frecuencia Ortogonal. Bogotá, Colombia: s.n.
[5] Mao, Guoquiang. The Maximum Throughput of A Wireless Multi-Hop Path. 2009.
[6] Marín Diazaraque, Juan Miguel. Análisis de componentes principales. http://halweb.uc3m.es/esp/Personal/personas/jmmarin/esp/AMult/tema3am.pdf, accedido el 23/11/2013. [ Links ]
[7] Marín Fernández, Josefa. Prácticas de ordenador con SPSS para Windows. http://www.catedras.fsoc.uba.ar/sautu/pdfs/manual-spss.pdf, accedido el 23/11/2013. [ Links ]
[8] Rincón, P. & Juan, J. Pruebas de hipótesis. http://lc.fie.umich.mx/~jrincon/pruebas%20de%20hipotesis.ppt, accedido el 23/11/2013. [ Links ]